GaussDB数据库SQL系列-数据去重
二、数据去重应用场景
-
数据库管理(含备份):在数据库中进行数据去重可以避免数据重复存储、备份,提高数据库的存储效率、降低备份的存储成本。 -
数据集成:在数据集成的过程中,需要合并多个数据源的数据,去重可以避免重复的数据对合并结果的影响。 -
数据分析(或挖掘):在进行数据分析或数据挖掘时,去重可以避免重复的数据对分析或挖掘结果的干扰,提高分析的准确性。 -
电商平台:在电商平台上进行商品去重可以避免重复上架相同的商品,提高平台的用户体验。 -
金融风控:在金融风控领域,去重可以避免重复的数据对风控模型的影响,提高风控的准确性。
三、数据去重案例(GaussDB)
1、示例场景描述
-
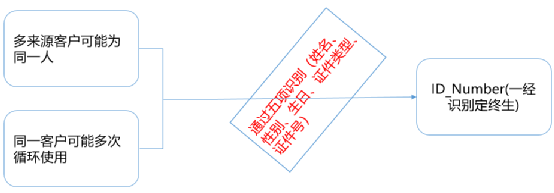
情况一:同一个客户有不同的来源渠道:客户即购买了寿险、又购买了产险(两个不同的来源系统); -
情况二:同一个客户多次回流:客户在同一个渠道多次购买(续保或者购买同一险种的不同产品)。
2、定义重复数据
3、制定去重规则
-
随机:根据去重规则,随机保留一条数据。 -
优先级:根据去重规则 + 业务逻辑,保留优先需要的一条数据。例如优先保留“是否有房、是否有车”。
2)多合一
-
将重复数据合并成一条数据,合并规则根据业务逻辑确定。
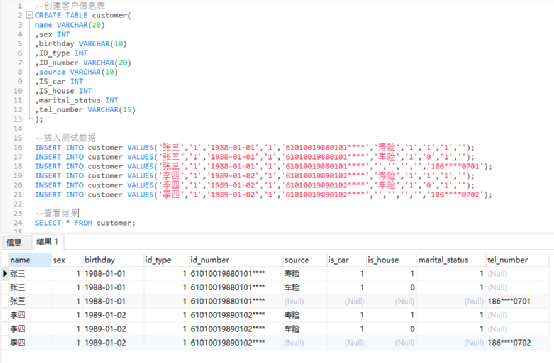
4、创建测试数据(GaussDB)
|
|
5、编写去重方法(GaussDB)
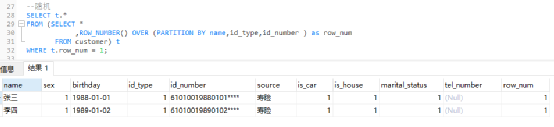
1)随机保留:根据业务逻辑,随机保留一条记录。
|
|
-
ROW_NUMBER(): 从第一行开始,依次为每一行分配一个唯一且连续的编号。 -
PARTITION BY col1[, col2...]: 指定分区的列,例如去重的键“姓名、证件类型、证件号码”。 -
WHERE row_num = 1:取ROW_NUMBER()生成的编号1。
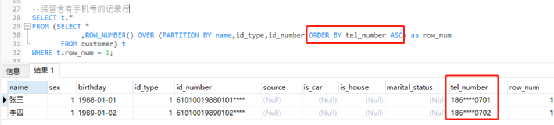
2)按优先级保留:根据业务逻辑,优先保留有手机号的一条记录,如果有多条记录含有手机号或有没有手机号,则在此基础上随机保留。
|
|
-
ROW_NUMBER(): 从第一行开始,依次为每一行分配一个唯一且连续的号码。 -
PARTITION BY col1[, col2...]: 指定分区的列,例如去重的键“姓名、证件类型、证件号码”。 -
ORDER BY col [asc|desc]: 指定排序的列。升序( ASC )排列指只保留第一行,而降序排列( DESC )则指保留最后一行。 -
WHERE row_num = 1:取ROW_NUMBER()生成的编号1。
3)合并保留:根据业务逻辑,合并完整性高、准确性高的字段信息。例如优先将含有手机号的记录行进行补齐,需要补齐的字段有“是否有车、是否有房、婚姻状况”,其取值是来源为“车险”的对应记录。
|
|
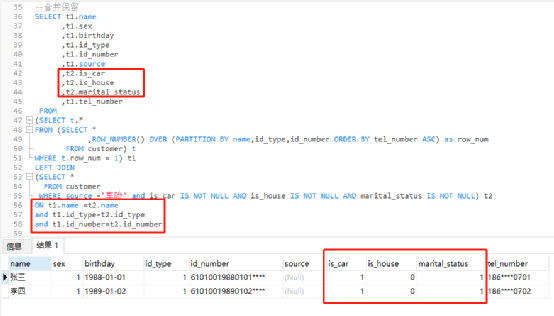
6、附:全字段去重
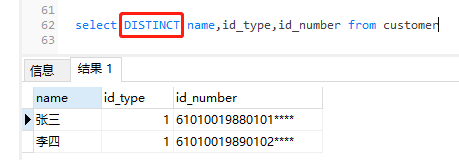
1) DISTINCT (假设全部有如下三个字段)
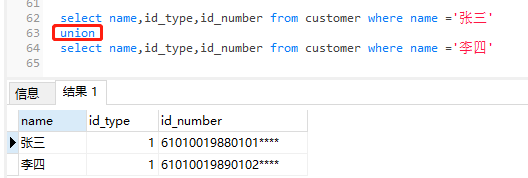
2) UNION(假设全部有如下三个字段)
四、数据去重效率提升建议
-
选择合适的去重算法 :根据数据集的特点和规模,选择适合的去重算法,可以大大提高去重效率。 -
优化数据存储结构:采用合适的数据存储结构,如哈希表、B+树等,可以加快数据的查找和比较速度,从而提高去重效率。 -
并行化处理:采用并行化处理的方式,将数据集分成多个子集,分别进行去重处理,最后合并结果,可以大大加快去重速度。 -
使用索引加速查找:对数据集中的关键字段建立索引,可以加速查找和比较速度,从而提高去重效率。 -
前置过滤:采用前置过滤的方式,先对数据集进行一些简单的筛选和处理,如去除空值、去除无效字符等,可以减少比较次数,从而提高去重效率。 -
去重结果缓存(临时表):对去重结果进行缓存,可以避免重复计算,从而提高去重效率。 -
不建议重写(备份):涉及一些分区表,等不建议直接将去重后的结果集重写到生产表,创建临时换成,或进行备份后操作。
五、总结
如果您发现该资源为电子书等存在侵权的资源或对该资源描述不正确等,可点击“私信”按钮向作者进行反馈;如作者无回复可进行平台仲裁,我们会在第一时间进行处理!
- 最近热门资源
- 桌面通用(全架构)【在双系统环境下隐藏Windows启动菜单】操作指南 2083
- 银河麒麟桌面操作系统V10(SP1)2203-如何进行远程桌面互访? 2008
- 银河麒麟桌面操作系统【保留数据盘重装系统】 1817
- 麒麟系统各种原因开不了机解决(合集) 1621
- 桌面通用(全架构)【rpm包转成deb包】操作方法 933
- 银河麒麟桌面操作系统 V10-SP1 双系统安装 efi 分区问题 916
- 统信系统安装(合集) 860
- 统信桌面专业版【手动分区安装UOS系统】介绍 849
- 统启动异常几种类型(initramfs 模式) 691
- 银河麒麟服务器操作系统V10(X86|ARM)【进入单用户模式】操作方法 16
- 最近下载排行榜
- 桌面通用(全架构)【在双系统环境下隐藏Windows启动菜单】操作指南 0
- 银河麒麟桌面操作系统V10(SP1)2203-如何进行远程桌面互访? 0
- 银河麒麟桌面操作系统【保留数据盘重装系统】 0
- 麒麟系统各种原因开不了机解决(合集) 0
- 桌面通用(全架构)【rpm包转成deb包】操作方法 0
- 银河麒麟桌面操作系统 V10-SP1 双系统安装 efi 分区问题 0
- 统信系统安装(合集) 0
- 统信桌面专业版【手动分区安装UOS系统】介绍 0
- 统启动异常几种类型(initramfs 模式) 0
- 银河麒麟服务器操作系统V10(X86|ARM)【进入单用户模式】操作方法 0

prtyaa 收益393.72元

zlj141319 收益221.42元

1843880570 收益214.2元

IT-feng 收益213.03元

风晓 收益208.24元

777 收益172.82元

Fhawking 收益106.6元

信创来了 收益105.89元

克里斯蒂亚诺诺 收益91.08元

技术-小陈 收益79.65元
