详解瀚高数据库PDR性能诊断报告
一、pdr功能介绍
通常国产数据库运维是一个难点,特别是DBA人员对数据库进行性能分析时,使用一些工具等手段会大大降低分析难度。
瀚高数据库(以下简称HGDB)提供性能监控与诊断工具pdr, 实现了周期性的收集、处理、持久化和维护性能统计数据,主要用于数据库性能问题的诊断与解决,可以用来作为一段时期内数据库性能调整的参考。另外,pdr可以生成简单明了、信息丰富和分类清晰的HTML格式性能诊断报告,让DBA人员阅读起来非常方便。
二、pdr实现原理
HGDB的Postmaster负责fork出postgres进程,用于相应用户的查询请求,同时还fork出若干辅助进程,用于支持HGDB的运行。
pdr也是在postmaster启动时,注册的一个后台工作者进程。后台工作者进程hgPdr会使用SPI接口,对HGDB内核进行直接访问,实现统计信息的采集和存储。采集数据的过程类似于PgStat,不同之处在于,hg_pdr不会反馈采集信息给HGDB。
pdr启动后,首先初始化SPI接口,用于统计信息的采集和保存。所有信息保存在一个_pg_pdr模式中。_pg_pdr模式一共有四个表,分别保存等待事件信息、SQL执行信息、Database基本信息以及Table基本信息。
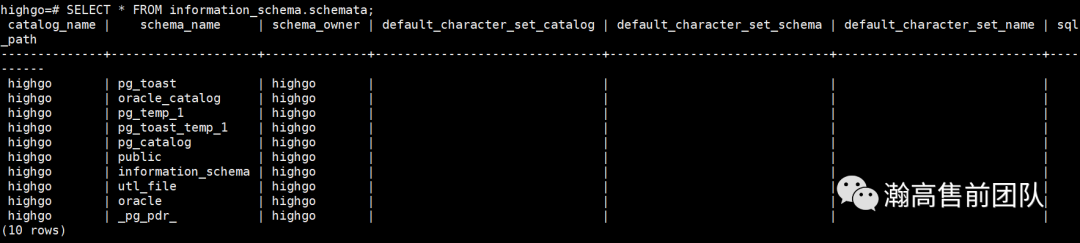
默认情况下,每隔一个小时,pdr会采集一次信息,将这些信息存入hg_pdr_模式的四个表里。每一条信息都带有一个快照id,用以识别采集的数据属于哪个时间段。这些数据,Database基本信息和Table基本信息,来自于HGDB自带的PgStat进程,pdr直接从共享内存中将这部分数据读取出来,并存入_pg_pdr_的表中。SQL执行信息来自pg_stat_statements插件,这部分信息也是保存在共享内存中的,可以通过相关函数直接读出。等待事件目前使用了pg_wait_sampling插件,对pg_stat_activity视图进行高频采样,将等待事件进行保存。_pg_pdr_中保存的统计信息,默认保留7天,超过7天的信息会被清理,以节约存储空间。
HGDB还提供一个pdr_report工具,用于生成性能分析报告。pdr_report工具会连接HGDB,将用户指定的时间段内的数据库信息取出,再结合报告模板,生成一份HTML格式的报告。
当使用pdr_report工具时,用户需要指定生成的数据库名,快照id的起止范围,生成报告的文件名。pdr_report工具会根据这些信息,从数据库中把用户指定的信息读取出来,填写到pdr_report.html模板中,最终生成pdr报告。
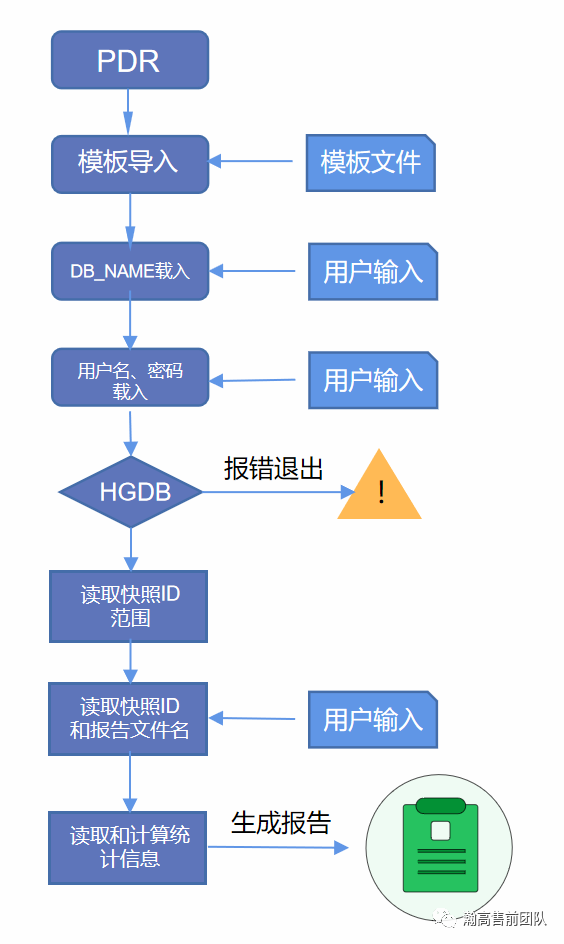
模板文件存放在share目录下,模板文件的样式可以进行修改,不会影响到报告的生成。
三、使用pdr
1、启用pdr
HGDB初始化完成后,实际上已经包含了pdr功能,我们只需要通过配置postgresql.conf来启用:
shared_preload_libraries= 'worker_pg_pdr,pg_stat_statements,pg_wait_sampling'完成修改后,重启数据库,pdr功能启用成功。让我们查看一下后台进程情况:
ps -ef |grep postgres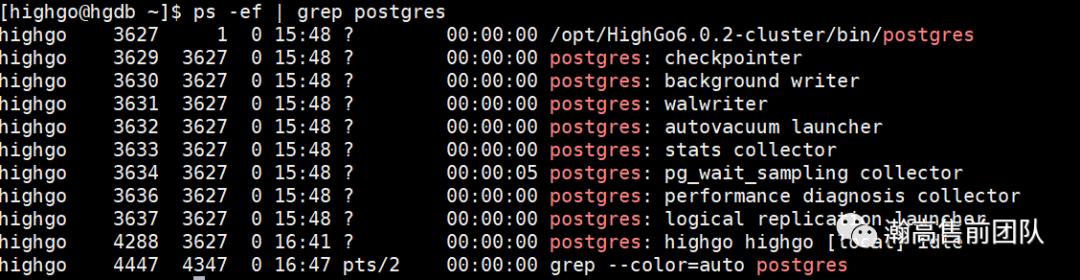
2、配置pdr
通过修改postgresql.conf中pdr相关参数,可以对pdr进行配置。
pg_pdr.naptime = 60 # 快照的产生间隔,单位为分钟,默认为60分钟产生一次快照。naptime=0时,代表不启用PDR功能。pg_pdr.naplife = 7 # 快照的保存时间,单位为天,默认保存最近7天的快照。超过naplife的快照,会自动删除。pg_pdr.napdb = 'highgo' # 用于保存PDR快照数据表的数据库,默认设置为highgo数据库。
3、使用pdr
初次安装和使用pdr时,采集的第一个快照id是0,用户可以用于生成性能分析报告的快照id是从1开始的。每采集一次快照,snap_id加1。生成快照的时机有两种。
(1)自动快照:
在数据库启动1分钟后自动产生一次快照,然后根据配置文件中的pg_pdr.naptime自动产生后续快照,无需操作。
(2)手动快照:
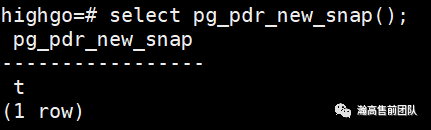
在psql中输入select pg_pdr_new_snap() 即可立即产生一次快照。
psql返回t,表示生成快照成功。
psql返回f,表示生成快照失败。
4、生成报告
使用pdr_report命令,可以生成性能分析报告。pdr生成的快照存储在napdb配置的数据库中,快照包含整个数据集簇中所有数据库的性能信息。
按照提示,依次输入数据库用户名、用户密码、快照存储数据库名、报告目标数据库名、开始快照id、结束快照id、报告文件名后即可生成报告。
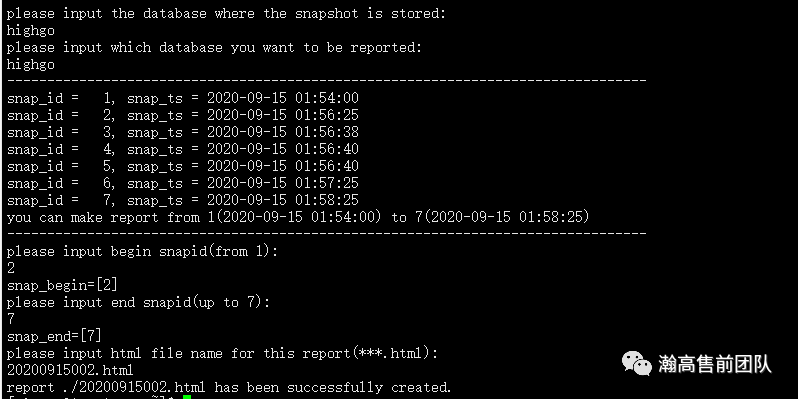
性能分析报告为html网页格式,可在浏览器中打开和使用。
4、阅读pdr报告
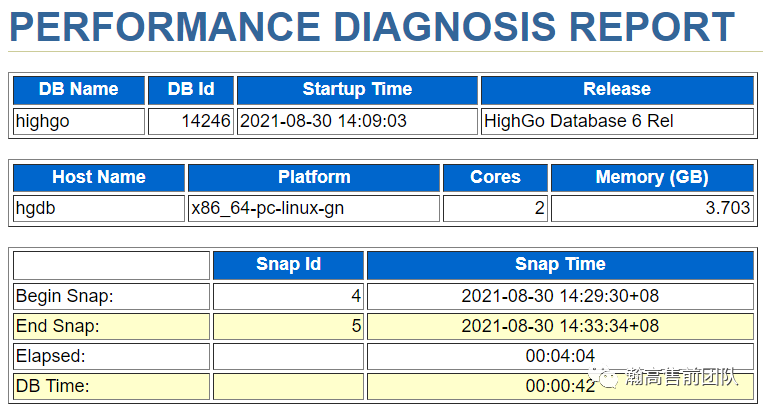
(1)基本信息部分,包括数据库、硬件环境、报告生成时间等基础信息。
(2)负载概要,主要显示数据库的主要负载情况。
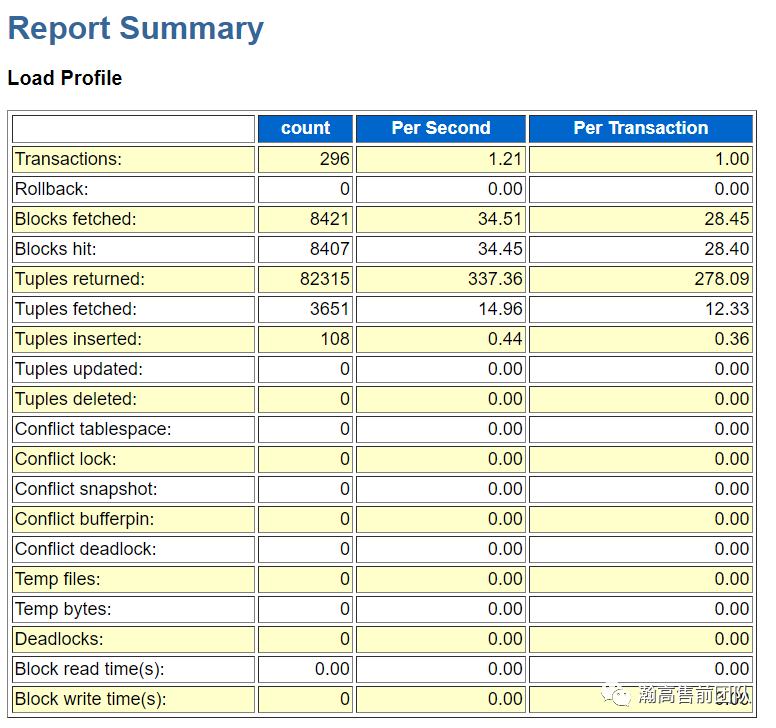
此外在摘要部分我们还看到前台事件等待top 10 的情况。

(3)等待状态
首先是HGDB的三种锁spinlock,lwlock和lock的等待情况。
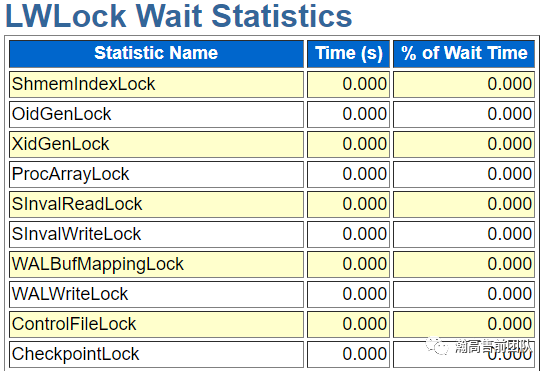
LWLock是一种基于spinlock机制实现的轻量级的锁,有互斥、共享、WAIT UNTIL FREE三种锁模式;
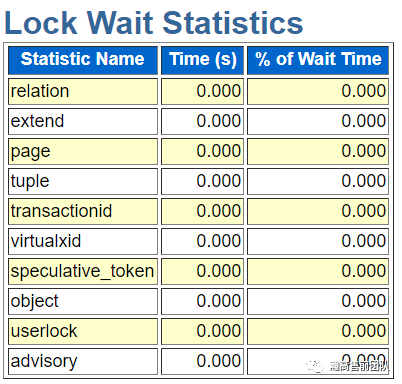
Lock是和Oracle enqueue类似的普通锁,用于操作HGDB中的数据对象的。从Lock锁的等待情况中可以分析HGDB的锁的争用情况,从而用于优化HGDB配置与应用程序。
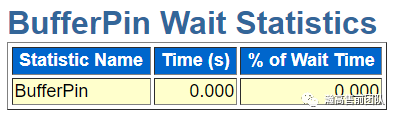
BufferPin wait状态可以用于辅助分析热块争用与缓冲池的效率,该锁是保护内存结构用的(和Oraclelatch类似),采用硬件和操作系统提供的test and set原子操作来实现。
接下来是client、extension、IPC三个等待状态。客户端等待状态可以用于分析客户端或者应用的性能与负载情况,extension等待可以用于分析数据文件的扩展情况。IPC Wait可以用于分析数据库中的进程间通讯是否正常。
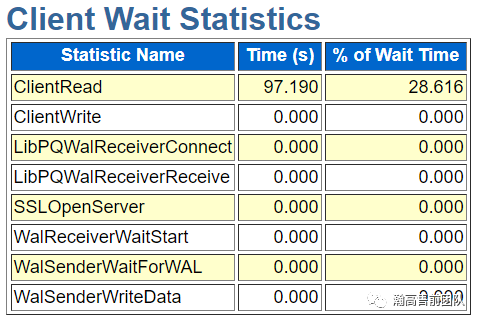
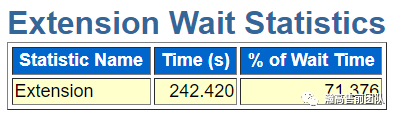
然后是用于分析数据库中的超时以及IO等待统计。
(4)实例统计信息
(5)SQL统计,统计了耗时SQL以及5类top SQL:CPU占用、IO占用、缓存命中、物理读和执行次数。
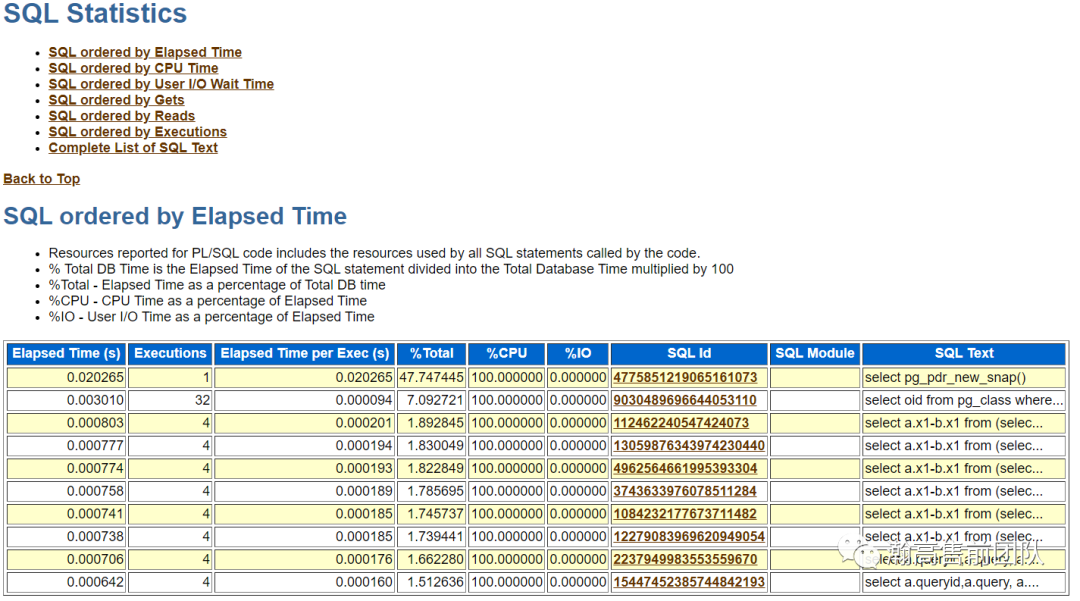
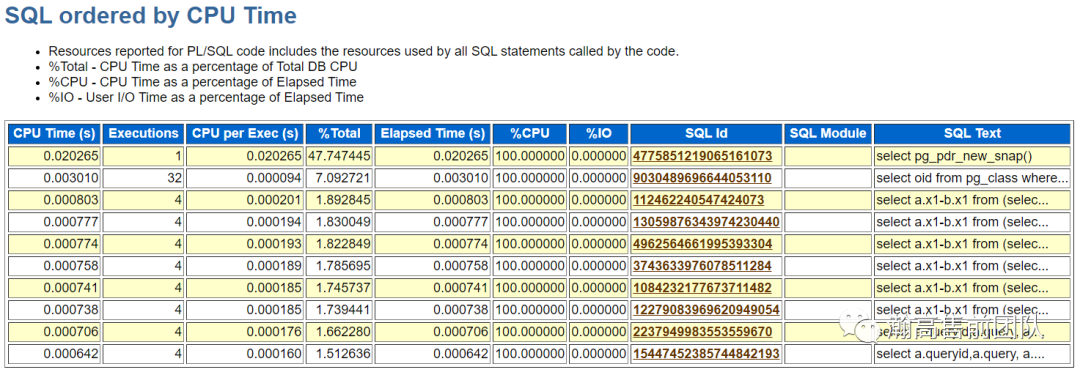
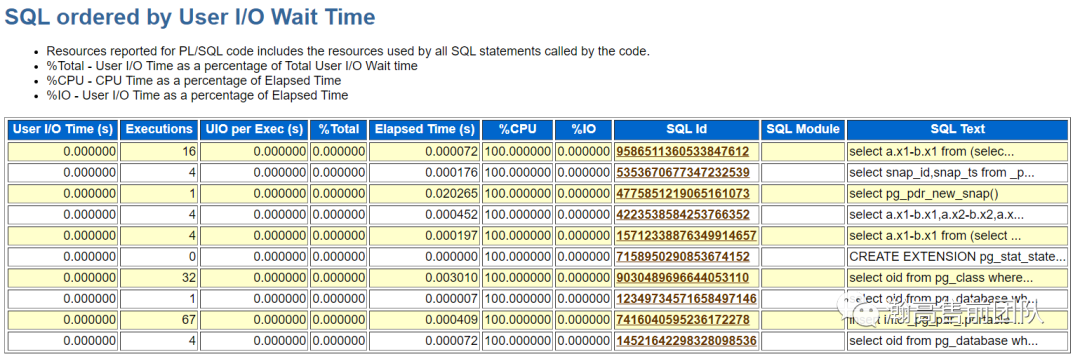
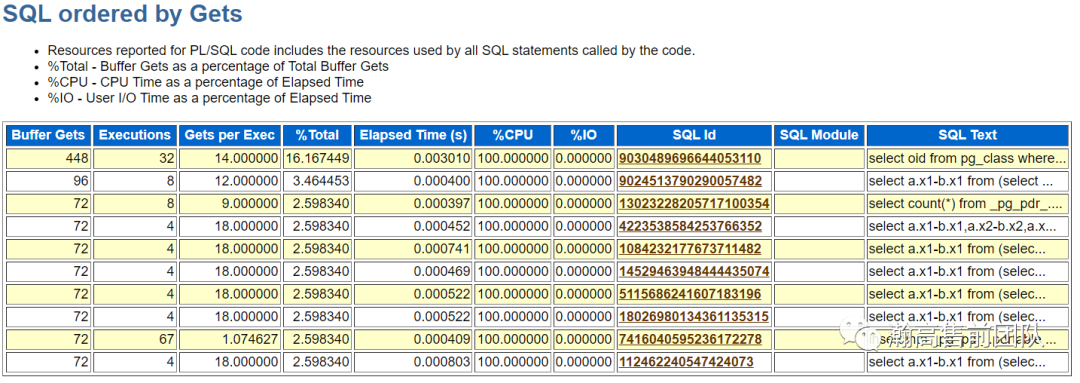


接下来的信息显示了top sql语句的完整的文本内容。
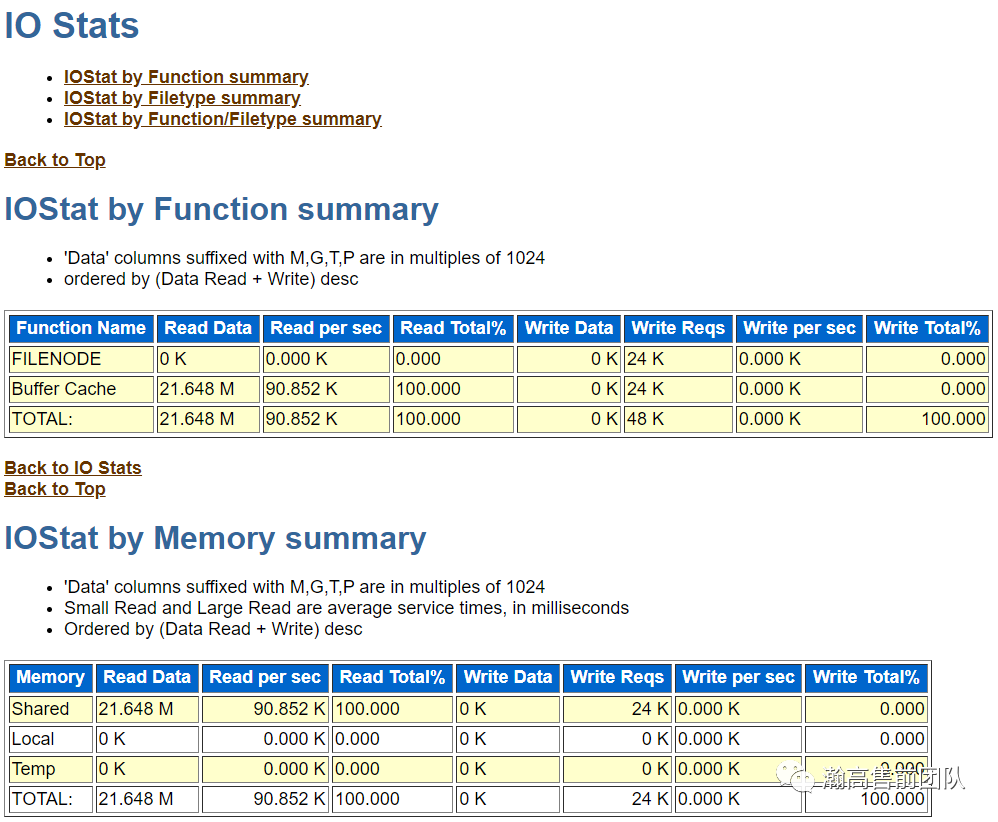
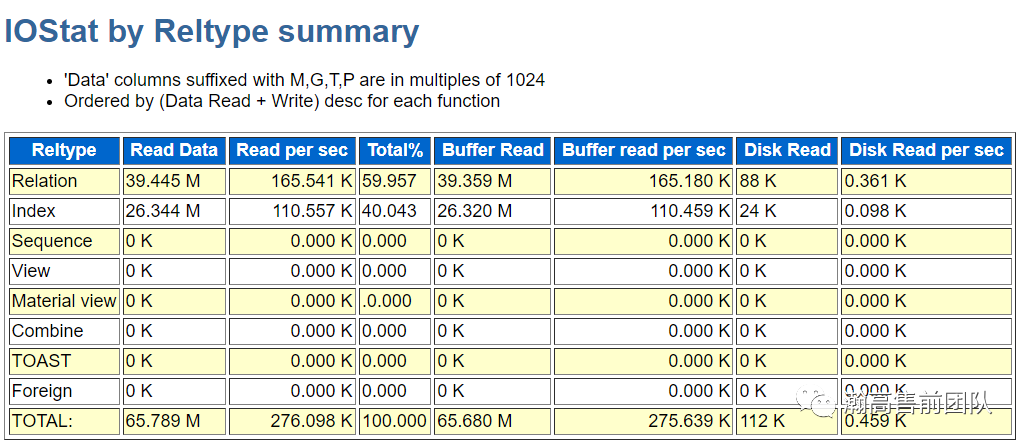
(6)IO统计信息,分别按照功能、缓冲区、对象进行统计。
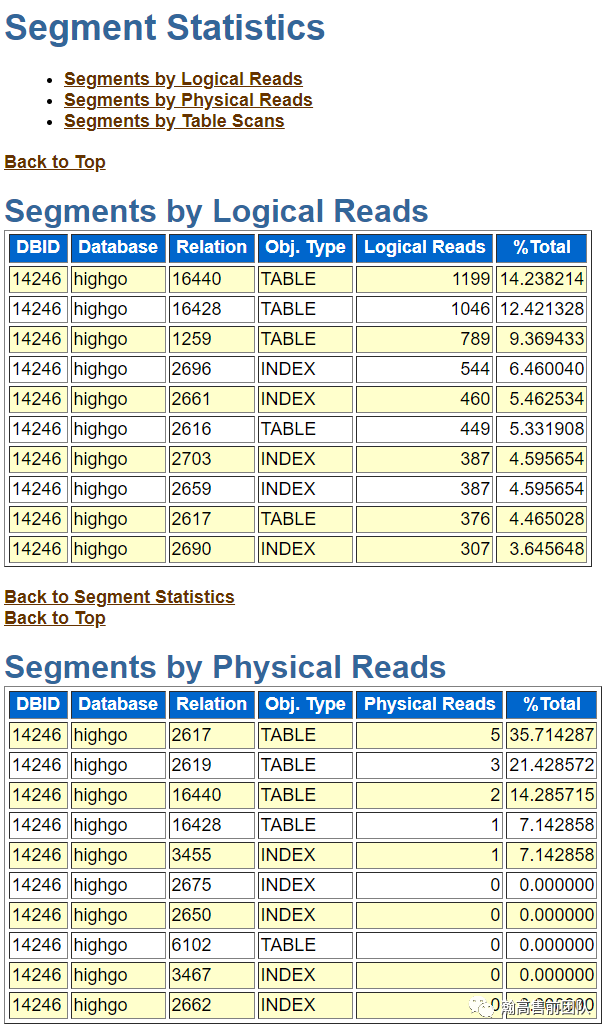
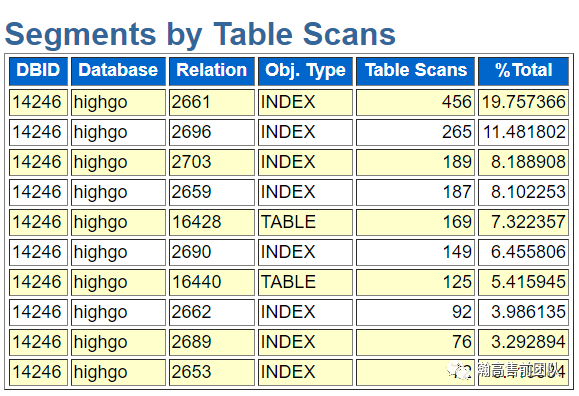
(7)Segment统计,分别按照逻辑读、物理读、全表扫描进行统计。
四、pdr总结
HGDB的pdr功能主要作用是收集数据库和操作系统相关信息,为HGDB在运行过程中产生的性能问题提供诊断信息。
如果您发现该资源为电子书等存在侵权的资源或对该资源描述不正确等,可点击“私信”按钮向作者进行反馈;如作者无回复可进行平台仲裁,我们会在第一时间进行处理!
- 最近热门资源
- 银河麒麟桌面操作系统备份用户数据 132
- 统信桌面专业版【全盘安装UOS系统】介绍 132
- 银河麒麟桌面操作系统安装佳能打印机驱动方法 122
- 银河麒麟桌面操作系统 V10-SP1用户密码修改 111
- 麒麟系统连接打印机常见问题及解决方法 35
- 最近下载排行榜
- 银河麒麟桌面操作系统备份用户数据 0
- 统信桌面专业版【全盘安装UOS系统】介绍 0
- 银河麒麟桌面操作系统安装佳能打印机驱动方法 0
- 银河麒麟桌面操作系统 V10-SP1用户密码修改 0
- 麒麟系统连接打印机常见问题及解决方法 0

prtyaa 收益393.62元

zlj141319 收益218元

1843880570 收益214.2元

IT-feng 收益210.13元

风晓 收益208.24元

777 收益172.71元

Fhawking 收益106.6元

信创来了 收益105.84元

克里斯蒂亚诺诺 收益91.08元

技术-小陈 收益79.5元
