瀚高数据库的全文(中文)检索
目录
1 数据分类
2 瀚高的全文检索简介
3 瀚高全文检索分词简介
4 瀚高全文检索常见索引
4.1 GIN索引结构
4.2 RUM索引
5 基于词库的解决方案
5.1 基于SCWS分词
5.2 基于pg_jieba 分词
6 基于二元分词的解决方案
A 测试用例
【基于SCWS分词的全文检索测试用例】
【基于pg_jieba的全文检索测试用例】
【基于二元分词的全文检索测试用例】
1 数据分类
数据是数据库中存储的基本对象,凡是计算机中用来描述事物的记录都可以统称为数据,包括数字、文字、图形、图像、音频、视频、学生的档案记录等等,可以分为两类:结构化数据、非结构化数据。
结构化数据是指可以使用关系型数据库表示和存储,表现为二维形式的数据。一般特点是:数据以行为单位,一行数据表示一个实体的信息,每一行数据的属性是相同的。结构化的数据的存储和排列是很有规律的,这对查询和修改等操作很有帮助,但是它的扩展性不好。
非结构化数据是没有固定结构的数据。对于这类数据,我们一般直接整体进行存储。包括文字、文件、图片、音频和视频等。本文所涉及的专指文字,特别是一些较大的文档,例如文章、论文、新闻报道等。
|
数据分类 |
概念 |
检索方式 |
|
结构化数据 |
有固定格式或者有限长度 |
参照传统关系型数据库 |
|
非结构化数据 |
不定长或者无固定格式 |
顺序查找 |
|
全文检索 |
2 瀚高的全文检索简介
全文检索(或者文本搜索)提供了确定满足一个查询的自然语言文档的能力,并可以选择将它们按照与查询的相关度排序。最常用的搜索类型是找到所有包含给定查询词的文档并按照它们与查询的相似性顺序返回它们。为实现全文检索,第一种是全量扫描逐行匹配,另一种是通过构建索引加快查询的速度。
全文索引的创建可分为两步,第一步对文档的预处理(也可称为矢量化、分词),第二部创建索引。
预处理是指将文档解析成记号、再将记号转换成词位。把原始文档标识成多种类型的记号,例如数字、词、复杂的词、电子邮件地址等,这样它们可以被以不同的方式处理。瀚高数据库使用解析器(解析的原理包括词典分词、语义分词、词频分词、二元分词等)来执行这个步骤,并且支持创建定制的解析器。词位是一个字符串,它已经被正规化,包含了各个记号的位置信息。瀚高数据库使用词典来执行这个步骤,同样支持创建定制的词典。此外,这个步骤通常会消除停用词,它们是那些太普通的词,它们对于搜索是无用的。如下一段话:“今天我们在这里隆重集会,热烈庆祝中国共产党成立100周年”,通过预处理可以解析成“'100':7 '中国共产党':5 '庆祝':4 '成立':6 '热烈':3 '隆重':1 '集会':2”这样的字符串,各个词后的数字就是指在文档中出现的位置,类似于“我们在这里”等普通词会被过滤掉。

瀚高数据库提供了tsvector、tsquery两种数据类型用来支持全文检索。其中tsvector中存储预处理之后的数据,tsquery是用来匹配查询条件的。具体用法后续会介绍。
对文档进行预处理之后就可以对预处理之后的字符串创建索引,瀚高数据库支持创建多种索引,常见的索引包括GIN索引、RUM索引。
3 瀚高全文检索分词简介
全文索引的一个前提是对于复杂文本进行分词,即提取Key。瀚高支持多种分词系统,两种常用的分词系统:SCWS分词、pg_jieba分词、二元分词。
SCWS分词
SCWS (Simple Chinese Words Segmentation)即简易中文分词系统。这是一套基于词频词典的机械中文分词引擎,它能将一整段的汉字基本正确的切分成词。词是汉语的基本语素单位,而书写的时候不像英语会在词之间用空格分开。SCWS 采用的是自行采集的词频词典,并辅以一定程度上的专有名称、人名、地名、数字年代等规则集,切词效率高。瀚高支持zhparser和SCWS搭配使用。
pg_jieba分词
jieba号称是Python中最好的中分词库。基于前缀词典实现高效的词图扫描,生成句子中汉字所有可能词情况所构成的有向无环图;采用动态规划查找最大概率路径,找出基于词频的最大切分组合;对于未登录词,采用了基于汉字成词能力的 HMM 模型,使用了 Viterbi 算法。
二元分词
顾名思义,是将文档中的字进行前后两两结合,具体“我爱中国共产党”可以分词称为“我爱、爱中、中国、国共、共产、产党”,当然也是可以设置N元分词(N一般为1~10)。
4 瀚高全文检索常见索引
4.1 GIN索引结构
GIN索引(Generalized Inverted Index, 通用倒排索引)是一个存储对(key, posting list)集合的索引结构,其中key是一个键值,而posting list 是一组出现过key的位置。如(‘祖国', '14:2 23:4')中,表示“祖国”在14:2和23:4这两个位置出现过,在瀚高数据库中这些位置实际上就是元组的TID(行号:Data Block ID(32bit)+ Item Point(16 bit) )。表中的每一个属性,在建立索引时,都可能会被解析为多个键值,所以同一个元组的TID可能会出现在多个key的posting list中。
4.1.1逻辑结构
GIN索引在逻辑上可以看成一个relation,该relation有两种结构:
1.只索引基表的一列
|
key |
value |
|
Key1 |
Posting list( or posting tree) |
|
Key2 |
Posting list( or posting tree) |
|
… |
… |
2. 索引基表的多列(复合、多列索引)
|
column_id |
key |
value |
|
Column1 num |
Key1 |
Posting list( or posting tree) |
|
Column2 num |
Key1 |
Posting list( or posting tree) |
|
Column3 num |
Key1 |
Posting list( or posting tree) |
|
... |
... |
... |
这种结构,对于基表中不同列的相同的key,在GIN索引中也会当作不同的key来处理。
4.1.2物理结构
GIN索引在物理存储上包含如下内容:
|
Entry |
GIN索引中的一个元素,可以认为是一个词位,也可以理解为一个key |
|
Entry tree |
在Entry上构建的B树 |
|
Posting List |
一个Entry出现的物理位置(heap ctid, 堆表行号)的链表 |
|
Posting Tree |
在一个Entry出现的物理位置链表(heap ctid, 堆表行号)上构建的B树,所以posting tree的Key是ctid,而entry tree的Key是被索引的列的值 |
|
Pending List |
索引元组的临时存储链表,用于fastupdate模式的插入操作 |
从上面可以看出GIN索引主要由Entry tree和Posting Tree(or Posting List)组成,其中Entry tree是GIN索引的主结构树,Posting Tree是辅助树。Entry Tree类似于B+tree,而Posting Tree则类似于B-tree。另外,不管Entry Tree还是Posting Tree,它们都是按KEY有序组织的,如下图示。
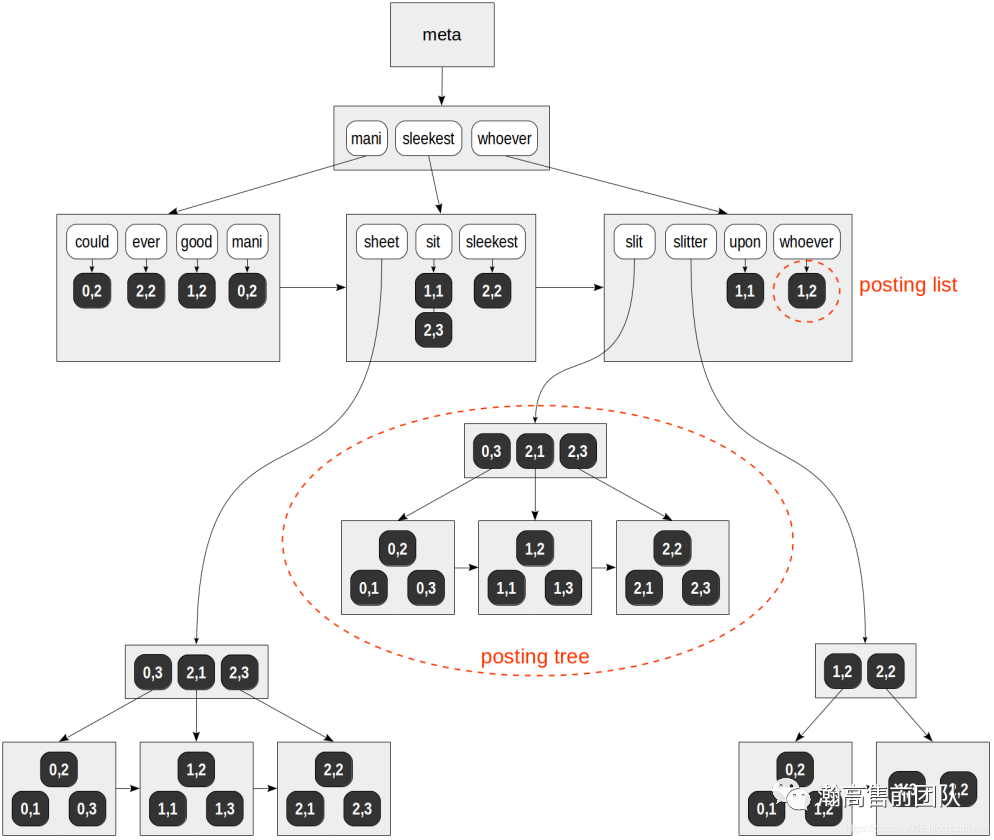
4.2 RUM索引
RUM索引与GIN类似,但是在Posting List|Tree的每一个ctid后面会追加一些属性值,例如(‘祖国', '14:2:100')表示“祖国”在14:2 这个位置出现了100次,这个频次就是一种额外的信息,在处理排序或者统计出现频次的时候,性能很优异。可以说RUM索是对GIN索引的一种加强,但是RUM索引的膨胀率要比GIN索引高,维护索引会消耗更多的性能。
5 基于词库的解决方案
5.1 基于SCWS分词
基于SCWS分词的全文索引会用到SCWS和zhparser两个插件。
5.1.1 安装SCWS
#Step1:Downloadswget http://www.xunsearch.com/scws/down/scws-1.2.3.tar.bz2#Step2:在pg的安装目录下创建文件夹swcs,解压tar xvjf scws-1.2.3.tar.bz2#Step3:安装--prefix=/usr/local/scws ; make ; make install#Step4:检查#顺利的话已经编译并安装成功到 /usr/local/scws 中了,执行下面命令看看文件是否存在ls -al /usr/local/scws/lib/libscws.la-h#scws (scws-cli/1.2.3)#Simple Chinese Word Segmentation - Command line usage.#Step5:下载解压词典cd /usr/local/scws/etcwget http://www.xunsearch.com/scws/down/scws-dict-chs-gbk.tar.bz2wget http://www.xunsearch.com/scws/down/scws-dict-chs-utf8.tar.bz2tar xvjf scws-dict-chs-gbk.tar.bz2tar xvjf scws-dict-chs-utf8.tar.bz2
5.1.2 安装zhparser
#Step1:在pg的安装目录下打开文件夹scwscd scws#Step2:把压缩包上传到该目录里面,然后解压unzip zhparser-master.zip#Step3:进入到解压的目录cd zhparser-master#Step4:进行安装SCWS_HOME=/usr/local make&&make install
5.2 基于pg_jieba 分词
#可以在瀚高的安装目录或者root/pg_jieba。#Step1:Downloadsgit clone https://github.com/jaiminpan/pg_jieba#Step2:Compilecd pg_jiebaUSE_PGXS=1 makeUSE_PGXS=1 make install# if got error when doing "USE_PGXS=1 make install"# try "sudo USE_PGXS=1 make install"
6 基于二元分词的解决方案
瀚高数据库默认支持二元分词,不需要其它插件。
6.1 使用步骤
ENSION zhfts;
CREATE TABLE test_rum(id int, message text);
CREATE INDEX rumidx ON test_rum USING rum(message rum_text_ops);
插入数据:
INSERT INTO test_rum VALUES (1,'我在青岛');
INSERT INTO test_rum VALUES (2,'我在济南大明湖');
查询数据:
set enable_seqscan=OFF;
select * from test_rum WHERE message % '青岛';
select * from test_rum WHERE message % '我在青岛';
6.2 操作符
(1) 匹配符号 %
当要在表中的某一列检索某个词时,需要使用百分号%来表示该检索。百分号前面指定一个数据列,后面指定一个查询条件。百分号后面的查询条件可以是多个词,词与词之间可以是:与关系(&),或关系(|)。例如:
select * from test_rum WHERE message % '青岛 | 济南';
select * from test_rum WHERE message % '济南 & 大明湖';
一个词不能有空格,否则语法检查会报错,查询也不会执行。如果需要查询多个词,必须使用逻辑符号( “|”,”&”)来关联多个词。
(2)相似比较 like
LIKE 的引入,主要是为了在语法上支持非索引情况下的 LIKE。
select * from test_rum WHERE message LIKE '青岛';
select * from test_rum WHERE message LIKE '%青岛';
在 zhfts 索引中,其处理方式类似于%。zhfts 把检索条件中的百分号%去掉,对剩
余的文本做二元分词,把分词的结果作为 key,检索索引。
(3)相似度和 order by <->
检索中,检索条件和某行的列数据匹配,则该行数据符合条件,会出现在检索结果中。有些情况下,需要对检索结果排序,相似度高的数据排列在前面,则需要使用:order by <->。
例如:
select * from test_rum WHERE message % '我在青岛' order by message <->'我在青岛';
其中,message <->'我在青岛',会调用内置函数,计算 2 个参数之间的相似度,返
回一个浮点数。数值越小,越相似。默认情况下,越相似的匹配就会排到前面。
A 测试用例
【基于SCWS分词的全文检索测试用例】
1.创建zhparser解析器
连接到目标数据库,创建zhparser解析器
create extension zhparser;2.将zhparser解析器作为全文检索配置项
create text search configuration chinese (PARSER = zhparser);#使用 \dFp查看解析器
\dFp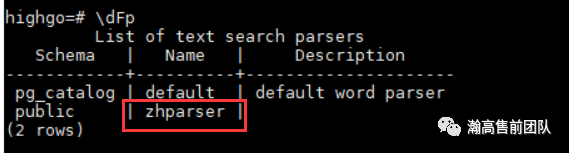
zhparser可以将中文切分成26中token
select ts_token_type('zhparser');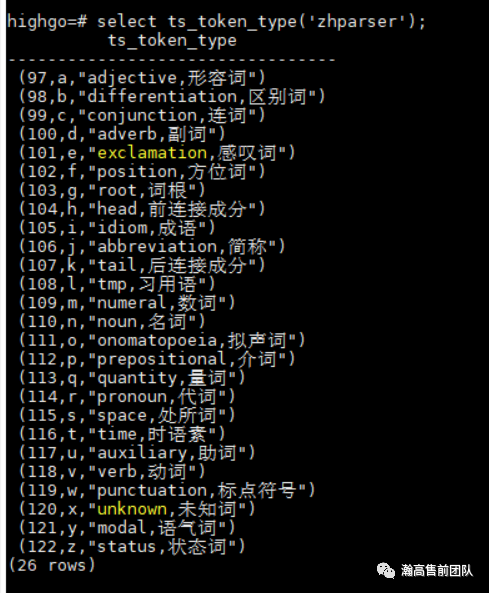
3.指定分词策略
通常情况:只需要按照名词(n),动词(v),形容词(a),成语(i),叹词(e)和习用语(l)6种方式对句子进行划分就可以
alter text search configuration chinese add mapping for n,v,a,i,e,l with simple;
4. 建表
create table gin_zhparser_test (id integer,title varchar(50),content text,primary key(id),tsv_content tsvector);
5. 插入数据
insert into gin_zhparser_test values(generate_series(1,100000),'《赤兔马之死》', '建安二十六年,公元221年,关羽走麦城,兵败遭擒,拒降,为孙权所害。其坐骑赤兔马为孙权赐予马忠。一日,马忠上表:赤兔马绝食数日,不久将亡。孙权大惊,急访江东名士伯喜。此人乃伯乐之后,人言其精通马语。马忠引伯喜回府,至槽间,但见赤兔马伏于地,哀嘶不止。众人不解,惟伯喜知之。伯喜遣散诸人,抚其背叹道:“昔日曹操作《龟虽寿》,‘老骥伏枥,志在千里。烈士暮年,壮心不已’,吾深知君念关将军之恩,欲从之于地下。然当日吕奉先白门楼殒命,亦未见君如此相依,为何今日这等轻生,岂不负君千里之志哉?”赤兔马哀嘶一声,叹道:“予尝闻,‘鸟之将死,其鸣也哀;人之将死,其言也善。’今幸遇先生,吾可将肺腑之言相告。吾生于西凉,后为董卓所获,此人飞扬跋扈,杀少帝,卧龙床,实为汉贼,吾深恨之。”伯喜点头,曰:“后闻李儒献计,将君赠予吕布,吕布乃天下第一勇将,众皆言,‘人中吕布,马中赤兔。’想来当不负君之志也。"赤兔马叹曰:“公言差矣。吕布此人最是无信,为荣华而杀丁原,为美色而刺董卓,投刘备而夺其徐州,结袁术而斩其婚使。‘人无信不立’,与此等无诚信之人齐名,实为吾平生之大耻!后吾归于曹操,其手下虽猛将如云,却无人可称英雄。吾恐今生只辱于奴隶人之手,骈死于槽枥之间。后曹操将吾赠予关将军;吾曾于虎牢关前见其武勇,白门楼上见其恩义,仰慕已久。关将军见吾亦大喜,拜谢曹操。操问何故如此,关将军答曰:‘吾知此马日行千里,今幸得之,他日若知兄长下落,可一日而得见矣。’其人诚信如此。常言道:‘鸟随鸾凤飞腾远,人伴贤良品质高。’吾敢不以死相报乎?”伯喜闻之,叹曰:“人皆言关将军乃诚信之士,今日所闻,果真如此。"赤兔马泣曰:“吾尝慕不食周粟之伯夷、叔齐之高义。玉可碎而不可损其白,竹可破而不可毁其节。士为知己而死,人因诚信而存,吾安肯食吴粟而苟活于世间?”言罢,伏地而亡。伯喜放声痛哭,曰:“物犹如此,人何以堪?”后奏于孙权。权闻之亦泣:“吾不知云长诚信如此,今此忠义之士为吾所害,吾有何面目见天下苍生?”后孙权传旨,将关羽父子并赤兔马厚葬。');
最后再插入第100001条数据,文档最后加一句话:热烈庆祝中国共产党建党一百周年。
6. 不建索引的时候查询一个like
explain analyze select * from gin_zhparser_test where content like '%热烈%中国共产党%';
7. 更新全文索引列
update gin_zhparser_testset tsv_content = to_tsvector('chinese', coalesce(content,''));
8创建索引
Create index idx_gin_test on gin_zhparser_test using gin(tsv_content);9. 查看执行计划
explain analyze select * from gin_zhparser_test where tsv_content @@ plainto_tsquery('中国共产党');
【基于pg_jieba的全文检索测试用例】
1.连接数据库创建pg_jieba的解析器
create extension pg_jieba;创建完pg_jieba解析器以后会自动就有一个jiebacfg的中文检索配置。
2.建表
create table pg_jieba_test (id integer,title varchar(50),content text,primary key(id),tsv_content tsvector);
3.插入数据
insert into pg_jieba_test values(generate_series(1,100000),'《赤兔马之死》', '建安二十六年,公元221年,关羽走麦城,兵败遭擒,拒降,为孙权所害。其坐骑赤兔马为孙权赐予马忠。一日,马忠上表:赤兔马绝食数日,不久将亡。孙权大惊,急访江东名士伯喜。此人乃伯乐之后,人言其精通马语。马忠引伯喜回府,至槽间,但见赤兔马伏于地,哀嘶不止。众人不解,惟伯喜知之。伯喜遣散诸人,抚其背叹道:“昔日曹操作《龟虽寿》,‘老骥伏枥,志在千里。烈士暮年,壮心不已’,吾深知君念关将军之恩,欲从之于地下。然当日吕奉先白门楼殒命,亦未见君如此相依,为何今日这等轻生,岂不负君千里之志哉?”赤兔马哀嘶一声,叹道:“予尝闻,‘鸟之将死,其鸣也哀;人之将死,其言也善。’今幸遇先生,吾可将肺腑之言相告。吾生于西凉,后为董卓所获,此人飞扬跋扈,杀少帝,卧龙床,实为汉贼,吾深恨之。”伯喜点头,曰:“后闻李儒献计,将君赠予吕布,吕布乃天下第一勇将,众皆言,‘人中吕布,马中赤兔。’想来当不负君之志也。"赤兔马叹曰:“公言差矣。吕布此人最是无信,为荣华而杀丁原,为美色而刺董卓,投刘备而夺其徐州,结袁术而斩其婚使。‘人无信不立’,与此等无诚信之人齐名,实为吾平生之大耻!后吾归于曹操,其手下虽猛将如云,却无人可称英雄。吾恐今生只辱于奴隶人之手,骈死于槽枥之间。后曹操将吾赠予关将军;吾曾于虎牢关前见其武勇,白门楼上见其恩义,仰慕已久。关将军见吾亦大喜,拜谢曹操。操问何故如此,关将军答曰:‘吾知此马日行千里,今幸得之,他日若知兄长下落,可一日而得见矣。’其人诚信如此。常言道:‘鸟随鸾凤飞腾远,人伴贤良品质高。’吾敢不以死相报乎?”伯喜闻之,叹曰:“人皆言关将军乃诚信之士,今日所闻,果真如此。"赤兔马泣曰:“吾尝慕不食周粟之伯夷、叔齐之高义。玉可碎而不可损其白,竹可破而不可毁其节。士为知己而死,人因诚信而存,吾安肯食吴粟而苟活于世间?”言罢,伏地而亡。伯喜放声痛哭,曰:“物犹如此,人何以堪?”后奏于孙权。权闻之亦泣:“吾不知云长诚信如此,今此忠义之士为吾所害,吾有何面目见天下苍生?”后孙权传旨,将关羽父子并赤兔马厚葬。');
最后再插入第100001条数据,文档最后加一句话:热烈庆祝中国共产党建党一百周年。
4.不见索引时候查询一个like
explain analyze select * from pg_jieba_test where content like '%热烈%中国共产党%';
5.更新全文索引列
update pg_jieba_testset tsv_content = to_tsvector(jiebacfg, coalesce(content,''));
6.创建索引
create index idx_pgjieba_test on pg_jieba_test using gin(tsv_content);
7.查看执行计划
explain analyze select * from pg_jieba_test where tsv_content @@ plainto_tsquery '中国共产党';
【基于二元分词的全文检索测试用例】
1.建表
ENSION zhfts;CREATE TABLE rum_test(id int, message text);
2.创建索引
CREATE INDEX idx_rumtest ON rum_test USING zhfts (message zhfts_text_ops);
3.插入数据:
INSERT INTO rum_test VALUES (generate_series(1,100000),'建安二十六年,公元221年,关羽走麦城,兵败遭擒,拒降,为孙权所害。其坐骑赤兔马为孙权赐予马忠。一日,马忠上表:赤兔马绝食数日,不久将亡。孙权大惊,急访江东名士伯喜。此人乃伯乐之后,人言其精通马语。马忠引伯喜回府,至槽间,但见赤兔马伏于地,哀嘶不止。众人不解,惟伯喜知之。伯喜遣散诸人,抚其背叹道:“昔日曹操作《龟虽寿》,‘老骥伏枥,志在千里。烈士暮年,壮心不已’,吾深知君念关将军之恩,欲从之于地下。然当日吕奉先白门楼殒命,亦未见君如此相依,为何今日这等轻生,岂不负君千里之志哉?”赤兔马哀嘶一声,叹道:“予尝闻,‘鸟之将死,其鸣也哀;人之将死,其言也善。’今幸遇先生,吾可将肺腑之言相告。吾生于西凉,后为董卓所获,此人飞扬跋扈,杀少帝,卧龙床,实为汉贼,吾深恨之。”伯喜点头,曰:“后闻李儒献计,将君赠予吕布,吕布乃天下第一勇将,众皆言,‘人中吕布,马中赤兔。’想来当不负君之志也。"赤兔马叹曰:“公言差矣。吕布此人最是无信,为荣华而杀丁原,为美色而刺董卓,投刘备而夺其徐州,结袁术而斩其婚使。‘人无信不立’,与此等无诚信之人齐名,实为吾平生之大耻!后吾归于曹操,其手下虽猛将如云,却无人可称英雄。吾恐今生只辱于奴隶人之手,骈死于槽枥之间。后曹操将吾赠予关将军;吾曾于虎牢关前见其武勇,白门楼上见其恩义,仰慕已久。关将军见吾亦大喜,拜谢曹操。操问何故如此,关将军答曰:‘吾知此马日行千里,今幸得之,他日若知兄长下落,可一日而得见矣。’其人诚信如此。常言道:‘鸟随鸾凤飞腾远,人伴贤良品质高。’吾敢不以死相报乎?”伯喜闻之,叹曰:“人皆言关将军乃诚信之士,今日所闻,果真如此。"赤兔马泣曰:“吾尝慕不食周粟之伯夷、叔齐之高义。玉可碎而不可损其白,竹可破而不可毁其节。士为知己而死,人因诚信而存,吾安肯食吴粟而苟活于世间?”言罢,伏地而亡。伯喜放声痛哭,曰:“物犹如此,人何以堪?”后奏于孙权。权闻之亦泣:“吾不知云长诚信如此,今此忠义之士为吾所害,吾有何面目见天下苍生?”后孙权传旨,将关羽父子并赤兔马厚葬。');
在后再插入第100001条数据,文档最后加一句话:热烈庆祝中国共产党建党一百周年。
4.不使用索引查询数据
explain analyze select * from rum_test where message like '%中国共产党%';

5.使用索引查询数据
explain analyze select * from rum_test where message % '中国共产党';
如果您发现该资源为电子书等存在侵权的资源或对该资源描述不正确等,可点击“私信”按钮向作者进行反馈;如作者无回复可进行平台仲裁,我们会在第一时间进行处理!
- 最近热门资源
- 银河麒麟桌面操作系统备份用户数据 127
- 统信桌面专业版【全盘安装UOS系统】介绍 122
- 银河麒麟桌面操作系统安装佳能打印机驱动方法 114
- 银河麒麟桌面操作系统 V10-SP1用户密码修改 105
- 最近下载排行榜
- 银河麒麟桌面操作系统备份用户数据 0
- 统信桌面专业版【全盘安装UOS系统】介绍 0
- 银河麒麟桌面操作系统安装佳能打印机驱动方法 0
- 银河麒麟桌面操作系统 V10-SP1用户密码修改 0

prtyaa 收益393.62元

zlj141319 收益218元

1843880570 收益214.2元

IT-feng 收益209.03元

风晓 收益208.24元

777 收益172.71元

Fhawking 收益106.6元

信创来了 收益105.84元

克里斯蒂亚诺诺 收益91.08元

技术-小陈 收益79.5元
