前沿|AIGC起飞!通过数据库为AI大模型注入“持久记忆”
前沿|AIGC起飞!通过数据库为AI大模型注入“持久记忆”

非结构化数据通常指没有预定义结构的数据,如图片,视频,文本等。
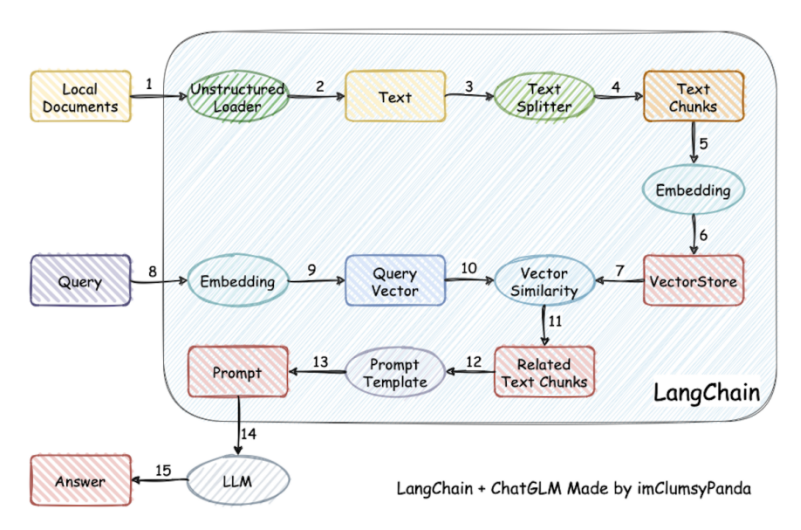
回看到过程中可选的向量数据库
用pgvector实现文本相似度检测其实相当简单
git clone --branch v0.4.4 https://github.com/pgvector/pgvector.git
cd pgvector
make
make install # may need sudo
embeddings = HuggingFaceEmbeddings(model_name='moka-ai/m3e-base',
model_kwargs={'device': 'cpu'})
from langchain.vectorstores.pgvector import PGVector
PGVECTOR_CONNECTION_STRING = PGVector.connection_string_from_db_params(
driver=os.environ.get("PGVECTOR_DRIVER", "psycopg2"),
host=os.environ.get("PGVECTOR_HOST", "localhost"),
port=int(os.environ.get("PGVECTOR_PORT", "5432")),
database=os.environ.get("PGVECTOR_DATABASE", "postgres"),
user=os.environ.get("PGVECTOR_USER", "postgres"),
password=os.environ.get("PGVECTOR_PASSWORD", "123456"),
)
data = [
"猫追老鼠",
"小猫捉啮齿动物",
"我喜欢火腿三明治",
"你使用的是什么embedding算法"
]
metadatas = [
{"answer":"老鼠可能被抓到"},
{"answer":"啮齿动物被抓到"},
{"answer":"火腿和三明治是不错的搭配"},
{"answer":"我使用的是m3e-base作为embedding算法,对中文的支持更好"}
]
PGVector.from_texts(texts = data,
embedding=embeddings,
collection_name="custom_qa",
connection_string=PGVECTOR_CONNECTION_STRING,
metadatas=metadatas
)
query = "猫捉老鼠"
print("="*80)
docs_with_score: list[tuple[Document, float]] = store.similarity_search_with_score(query)
for doc, score in docs_with_score:
print("Score:", score)
print(doc.page_content)
print(doc.metadata)
print("-"*80)
猫追老鼠
{'answer': '老鼠可能被抓到'}
-----------------------------------------------------------------
Score: 0.12241556104896034
小猫捉啮齿动物
{'answer': '啮齿动物被抓到'}
-----------------------------------------------------------------
Score: 0.33161097392725436
我喜欢火腿三明治
{'answer': '火腿和三明治是不错的搭配'}
-----------------------------------------------------------------
Score: 0.3587415090526611
你使用的是什么embedding算法
{'answer': '我使用的是m3e-base作为embedding算法,对中文的支持更好'}
-----------------------------------------------------------------
在实际使用中从向量数据库中搜索到的结果会被选出前几条,一起放到LLM中按照相关性分配权重进行归纳总结。
小 结
如果您发现该资源为电子书等存在侵权的资源或对该资源描述不正确等,可点击“私信”按钮向作者进行反馈;如作者无回复可进行平台仲裁,我们会在第一时间进行处理!
评价 0 条
- 最近热门资源
- 银河麒麟桌面操作系统备份用户数据 129
- 统信桌面专业版【全盘安装UOS系统】介绍 128
- 银河麒麟桌面操作系统安装佳能打印机驱动方法 119
- 银河麒麟桌面操作系统 V10-SP1用户密码修改 108
- 麒麟系统连接打印机常见问题及解决方法 22
- 最近下载排行榜
- 银河麒麟桌面操作系统备份用户数据 0
- 统信桌面专业版【全盘安装UOS系统】介绍 0
- 银河麒麟桌面操作系统安装佳能打印机驱动方法 0
- 银河麒麟桌面操作系统 V10-SP1用户密码修改 0
- 麒麟系统连接打印机常见问题及解决方法 0

prtyaa 收益393.62元

zlj141319 收益218元

1843880570 收益214.2元

IT-feng 收益210.13元

风晓 收益208.24元

777 收益172.71元

Fhawking 收益106.6元

信创来了 收益105.84元

克里斯蒂亚诺诺 收益91.08元

技术-小陈 收益79.5元
