运维必须知道的IT系统和网络监视工具
当你有很多主机和服务的时候,你需要知道每个主机,每个服务的运行情况
今天给大家介绍运维必须知道的IT系统和网络监视工具:Nagios
Nagios 是一个监视系统运行状态和网络信息的监视系统。Nagios 能监视所指定的本地或远程主机以及服务,同时提供异常通知功能等
github地址:
https://github.com/NagiosEnterprises/nagioscore
国内源代码:
http://www.gitpp.com/pythonking/nagioscore
Nagios 的介绍
Nagios 是一个用 C 语言编写的主机/服务/网络监控程序 ,它具有以下特点:
1. 监控网络服务:Nagios 能够监控各种网络服务,如 SMTP、POP3、HTTP、NNTP、PING 等。
2. 监控主机资源:Nagios 可以监控主机资源的利用率,如处理器负荷、磁盘利用率等。
3. 扩展性强:Nagios 具有简单的插件设计,用户可以方便地扩展自己服务的检测方法。
4. 并行服务检查机制:Nagios 支持并行服务检查,提高监控效率。
5. 网络分层结构:Nagios 具备定义网络分层结构的能力,用 "parent" 主机定义来表达网络主机间的关系,这种关系可被用来发现和明晰主机宕机或不可达状态。
6. 告警通知:当服务或主机问题产生与解决时,Nagios 会将告警发送给联系人,可通过 Email、短信、用户定义方式进行通知。
7. 处理程序定义:Nagios 允许用户定义处理程序,在服务或主机发生故障时起到预防作用。
8. 自动日志滚动:Nagios 具有自动的日志滚动功能。
9. 冗余监控:Nagios 支持对主机的冗余监控。
10. WEB 界面:Nagios 提供可选的 WEB 界面,用于查看当前的网络状态、通知和故障历史、日志文件等。
此外,Nagios 可以通过 NRPE 插件监控远程服务器资源,如存活、磁盘空间、负载、进程数、IP 连接等。NRPE 作为中间代理程序,在接受 Nagios 监测服务器发来的请求后在远程主机系统上获取指定信息。在远程主机上安装 NRPE 核心扩展插件程序,并与 Nagios 服务器进行配置,可实现对远程主机的监控。
总之,Nagios 是一个功能丰富、易于扩展的网络监控工具,适用于各种规模的企业和组织的网络管理。
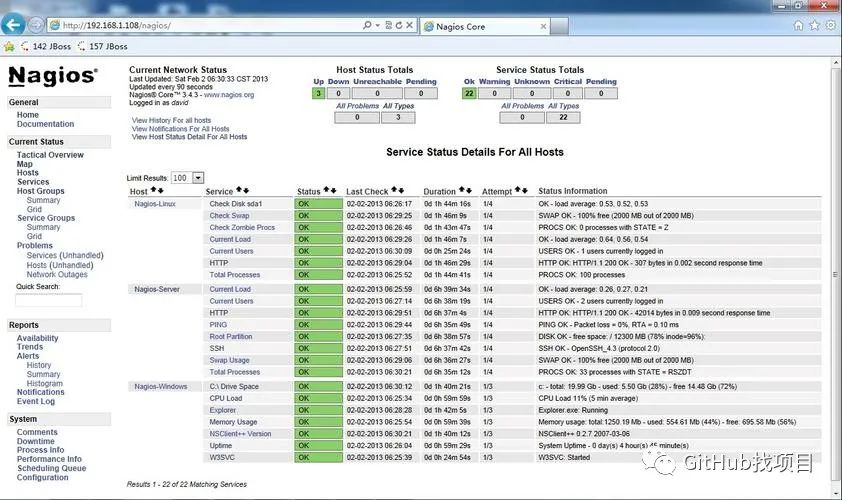
Nagios 是一个用 C 语言编写的监控程序,监控主机主要有哪些指标?
Nagios 是一个用 C 语言编写的监控程序,主要用于监控主机和网络服务。以下是 Nagios 监控主机时关注的指标:
1. 系统资源利用率:包括处理器利用率、内存利用率、磁盘空间利用率等。
2. 网络接口状态:监控网络接口的收发包情况、带宽利用率等。
3. 系统负载:实时监控系统负载情况,以便发现性能瓶颈。
4. 进程状态:检查进程运行情况,确保服务正常运行。
5. 服务响应时间:测量服务响应时间,以评估服务性能。
6. 数据库性能:监控数据库的连接数、查询响应时间等指标。
7. 磁盘空间:监控文件系统和目录的磁盘空间使用情况,预防磁盘空间不足。
8. 文件系统状态:检查文件系统是否健康,以及是否存在潜在的故障。
9. 系统日志:监控系统日志,以便发现异常事件和故障线索。
10. 安全审计:检查系统安全设置,如防火墙规则、弱密码等。
11. 硬件状态:监控硬件设备的状态,如电源、风扇、温度等。
12. 应用程序性能:监控关键应用程序的性能,如响应时间、吞吐量等。
13. 网络设备状态:监控网络设备,如交换机、路由器等,包括端口状态、带宽利用率等。
14. 打印机状态:监控网络打印机的状态,以确保打印服务正常运行。
以上指标可以帮助管理员全面了解主机和网络环境的运行状况,及时发现并解决问题,确保系统的稳定性和可用性。
Nagios 是一个监控程序,监控主机时,具体如何监控CPU?
Nagios 是一个监控程序,可以监控主机上的 CPU 资源。在监控 CPU 时,Nagios 通常关注以下指标:
1. 实时 CPU 利用率:实时监控 CPU 的使用情况,了解 CPU 负载的高低。
2. 过去 1 分钟内的平均 CPU 利用率:评估 CPU 在过去 1 分钟内的负载情况,以便发现性能瓶颈。
3. 过去 1 小时内的 CPU 利用率趋势:分析 CPU 利用率的变化趋势,预测性能问题。
4. CPU 负载高峰时段:识别 CPU 负载高峰时段,以便采取相应的措施缓解压力。
5. 长时间内 CPU 利用率:分析长时间内 CPU 的利用率,评估系统性能。
6. CPU 过载预警:当 CPU 利用率接近或达到阈值时,发出预警通知。
7. 异常情况监测:监测 CPU 运行过程中的异常情况,如崩溃、死机等。
8. 内核缓存状态:检查内核缓存状态,了解 CPU 与内存之间的数据传输效率。
为了实现对这些指标的监控,Nagios 可以使用 NRPE(Nagios Remote Plugin Execution)插件在远程主机上执行相应的命令。在 NRPE 配置文件中,可以编写监控 CPU 相关指标的命令,如:
```
command[cpu_usage]=/usr/bin/mpstat 1 5
```
这将在远程主机上执行 `mpstat` 命令,收集 CPU 利用率等信息,并将其发送回 Nagios 服务器。
此外,你还可以使用 NRPE 插件监控 CPU 核心数量、CPU 型号、操作系统等信息。这些数据可以帮助管理员全面了解 CPU 资源的状况,从而更好地进行性能优化和故障排查。

如果要用python开发一个系统监控系统,如何快速开发?
要使用 Python 快速开发一个系统监控系统,可以遵循以下步骤:
1. 选择合适的库和框架:首先,选择一些成熟的库和框架,例如 PSutil(用于获取系统性能数据)、Matplotlib(用于数据可视化)和 Python 的 web 框架(如 Flask 或 Django,用于搭建监控平台)。
2. 安装依赖库:根据所选库和框架,使用 pip 安装相应的依赖库。例如:
```
pip install psutil matplotlib flask
```
3. 编写数据获取和处理逻辑:利用 PSutil 库获取系统性能数据,如 CPU、内存、磁盘空间、网络等信息。编写数据处理逻辑,将获取到的原始数据进行整理和归类,以便后续可视化展示。
4. 数据可视化:使用 Matplotlib 库将处理后的数据可视化,生成折线图、饼图等。可以设计一些动态的图表,以便实时展示系统性能变化。
5. 搭建监控平台:利用所选 web 框架搭建一个简单的监控平台,将可视化后的数据展示在页面上。可以使用 AJAX 技术实现数据的实时刷新,提高监控的实时性。
6. 添加告警机制:根据业务需求,设置合理的阈值,当系统性能数据超过阈值时,触发告警机制,通过邮件、短信等方式通知管理员。
7. 集成第三方服务:为了提高监控系统的实用性,可以集成一些第三方服务,如数据库监控、网络设备监控等。
8. 编写用户界面:根据实际需求,编写一个用户友好的界面,使管理员可以轻松地查看和管理监控数据。
9. 测试与优化:在开发过程中,不断测试和优化监控系统,确保监控数据的准确性和实时性。
10. 部署与维护:将监控系统部署到服务器上,确保系统稳定运行。同时,持续关注系统性能,及时调整和优化监控策略。
通过以上步骤,可以快速开发一个 Python 系统监控系统。在实际开发过程中,可以根据具体需求进行调整和优化,提高监控系统的实用性和可用性。
安装指南
一旦您安装了 Nagios 并正常运行,您无疑会想要开始监视更多的内容,而不仅仅是监视本地计算机。查看以下文档,了解如何设置 Nagios Core 配置并监控更多内容......
-
监控 Windows 机器
-
监控 Linux/Unix 机器
-
监控路由器/交换机
-
监控公共可用服务(HTTP、FTP、SSH 等)
-
监控网络打印机
请访问www.nagios.org/about/了解有关 Nagios 的更多信息,包括特性、功能和技术规格。
当管理大量主机和服务时,了解它们的运行状况至关重要。这有助于确保系统稳定、高效运行,并及时发现潜在问题。以下是一些建议和方法,以帮助您监控大量主机和服务的运行情况:
1. 配置监控代理:在每台主机上安装监控代理,如 Nagios、Zabbix、Prometheus 等。这些代理可以收集主机的相关信息,如CPU、内存、磁盘使用情况、网络流量等。
2. 使用集中式监控平台:通过使用集中式监控平台,如 Grafana、Kibana 等,您可以一站式查看所有主机的监控数据。这些平台可以帮助您实时了解主机和服务的运行状况,并通过图表和报警等方式展示数据。
3. 设定阈值和报警:为关键指标设置阈值,如CPU使用率、磁盘空间等。当监控数据超过阈值时,自动触发报警通知。这有助于您及时发现潜在问题,并采取相应措施。
4. 采用自动化工具:使用自动化工具,如Ansible、Puppet等,来部署和管理主机和服务。这些工具可以确保主机和服务按照预期运行,并在出现问题时自动进行修复。
5. 定期审查日志:定期审查主机和服务的日志,以了解它们的运行状况。这可以帮助您发现异常行为,并及时解决潜在问题。
6. 编写自动化测试脚本:为关键服务编写自动化测试脚本,以确保它们在部署和升级后仍能正常运行。这有助于您确保服务的稳定性和可靠性。
7. 实施持续集成和持续部署(CI/CD):通过实施CI/CD流程,您可以自动检测代码更改并部署新版本的应用程序。这有助于确保服务始终运行在最新且经过测试的版本上。
8. 保持良好的文档:为所有主机和服务编写详细的文档,包括它们的用途、配置方法和故障排除指南。这有助于其他团队成员快速了解主机和服务的运行情况,并在需要时进行维护。
9. 定期进行性能测试:定期对主机和服务进行性能测试,以确保它们在负载高峰期仍能正常运行。这有助于您发现潜在的性能瓶颈,并采取适当措施优化系统。
10. 培训团队成员:确保团队成员熟悉主机和服务的运行情况,掌握基本的监控和故障排除方法。这将有助于提高整个团队的运维能力,降低因不知情而导致的故障风险。
通过以上方法,您可以更好地监控和管理大量主机和服务,确保它们高效、稳定地运行。同时,这有助于提高运维团队的协作和响应能力,为业务发展提供有力支持。
github地址:
https://github.com/NagiosEnterprises/nagioscore
国内源代码:
http://www.gitpp.com/pythonking/nagioscore
我们已经收集了GitHub上大量的开源项目
如果您发现该资源为电子书等存在侵权的资源或对该资源描述不正确等,可点击“私信”按钮向作者进行反馈;如作者无回复可进行平台仲裁,我们会在第一时间进行处理!
- 最近热门资源
- 银河麒麟桌面操作系统备份用户数据 123
- 统信桌面专业版【全盘安装UOS系统】介绍 117
- 银河麒麟桌面操作系统安装佳能打印机驱动方法 109
- 银河麒麟桌面操作系统 V10-SP1用户密码修改 102
- 最近下载排行榜
- 银河麒麟桌面操作系统备份用户数据 0
- 统信桌面专业版【全盘安装UOS系统】介绍 0
- 银河麒麟桌面操作系统安装佳能打印机驱动方法 0
- 银河麒麟桌面操作系统 V10-SP1用户密码修改 0

prtyaa 收益393.62元

zlj141319 收益218元

1843880570 收益214.2元

IT-feng 收益208.98元

风晓 收益208.24元

777 收益172.71元

Fhawking 收益106.6元

信创来了 收益105.84元

克里斯蒂亚诺诺 收益91.08元

技术-小陈 收益79.5元
