柏睿数据 & 统信UOS,构建AI大模型时代的向量计算引擎
随着移动互联网和大数据的兴起,向量数据库开始得到关注,主要是为了解决高维度数据的存储和查询问题,支持向量之间的相似度计算、向量索引和快速检索等基本功能。
近年来,随着人工智能和机器学习的发展,对向量计算的要求也在不断提高。正如当下火热的AI大模型等AI应用,要求向量数据库在处理大规模高维度向量数据时能够支持复杂相似度计算等功能,以及低时延、高并发、高可扩展等性能。
自UOS AI V1.0发布以来,受到了业界广泛关注。它实现了大模型统一管理,完成了5个主流大模型的适配,并成功接入本地模型。此外,浏览器、全局搜索、邮箱、畅写等应用全面接入UOS AI,实现了应用体验的智能化升级。
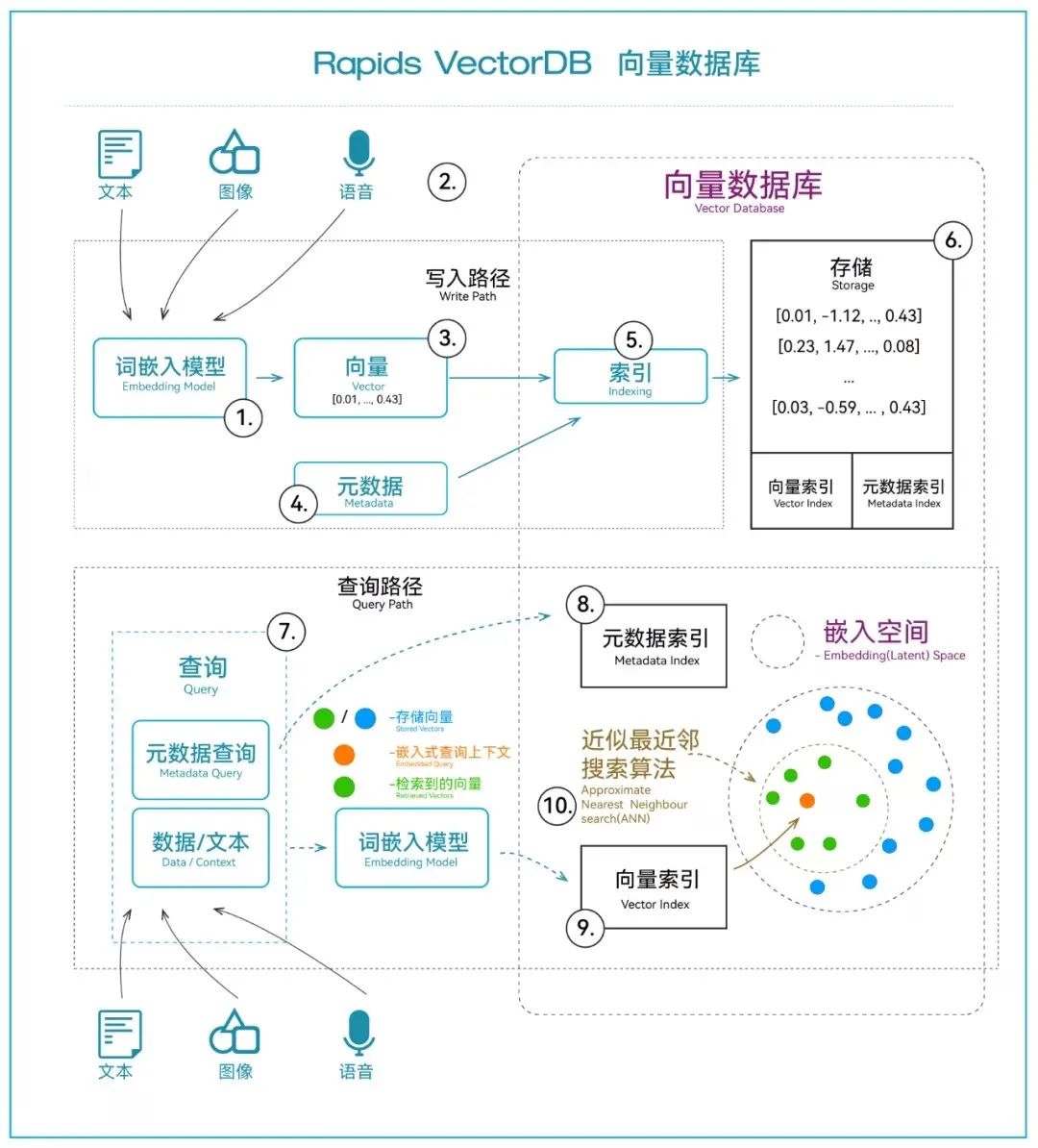
在处理文字、语音和图像等高维度数据时,如何快速而准确地进行检索查询是关键问题。高维度数据因其数据复杂度、维度灾难等特性,使得如欧氏距离或余弦相似度等传统的相似性度量方法,在高维空间中的高效精确计算变得不切实际。因此,向量数据库需要综合运用更高级的技术、更高效算法、更多的计算资源等来解决这一问题。
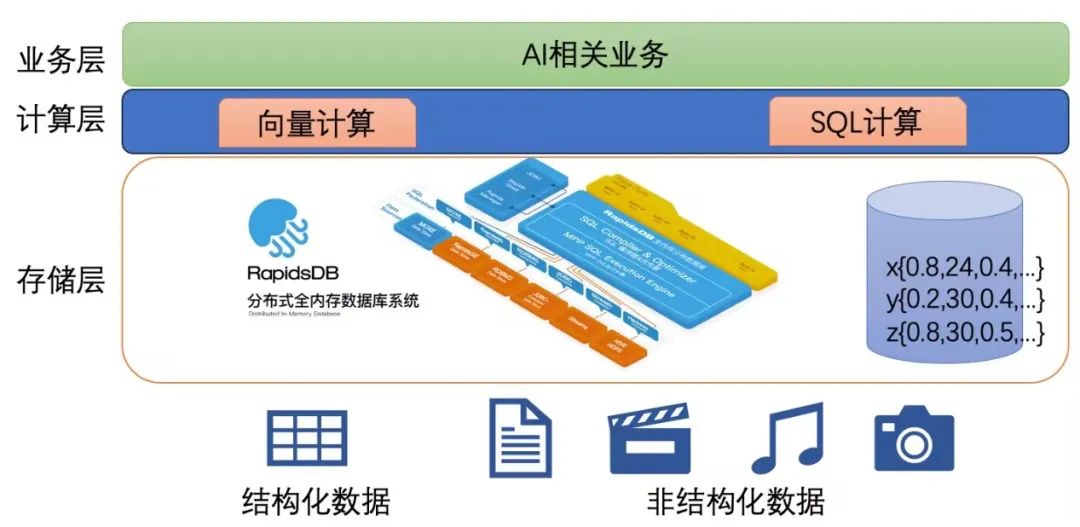
柏睿智算一体机内置的向量数据库Rapids VectorDB在柏睿分布式全内存数据库RapidsDB的基础上,基于统信UOS操作系统,开发独立向量计算模块,基于分布式架构,支持本地计算和HNSW向量相似度算法,可实现大规模向量数据查询分析秒级响应。
-
本地计算
Rapids VectorDB是一个分布式向量数据库,其向量计算模块部署在每个leaf节点,这为Rapids VectorDB进行本地计算提供可能。
通过成熟的SQL数据库技术,Rapids VectorDB将向量数据均匀分散到每个计算节点,并在本地执行向量计算。这种方式实现了离数据最近的位置进行计算,从而使得对向量数据的检索查询更加实时高效。
-
先进算法
Rapids VectorDB使用HNSW(Hierarchical Navigable Small World)向量相似度算法,提供高效、精准的向量计算。
HNSW是一种用于近似最近邻搜索的先进算法,因其在高维空间中高效的相似性搜索而被熟知。它采用多层级的数据结构,即概率跳跃列表,提高了在大规模向量数据中进行相似性搜索的效率;通过构建可导航小世界图,在保持高准确性的同时,大幅降低了搜索的时间复杂度,从而实现了更快速、更精确、更实时的查询响应能力。
同时,内置Rapids VectorDB的“智算一体机”不仅可为大规模高维度向量数据的处理提供强大的数据智能算力,并支持包括向量数据在内的海量多模态数据高效管理与实时分析,全面满足行业AI大模型等人工智能应用、云计算、边缘计算、高性能计算等多样化算力应用需求。
生态共建旨在与各行业、各领域的合作伙伴携手共同打造AI应用场景。通过与柏睿数据紧密合作,统信UOS AI可以更好地了解行业需求和应用场景,从而为用户提供更加精准、高效、智能的AI服务。同时,通过生态共建,统信UOS AI还可以不断拓展自身的技术能力和应用范围,为用户提供更加全面、丰富的AI应用场景。
统信UOS AI的新版本、新战略和新趋势展示了其在信息技术领域的全面进化。操作系统与AI的融合是未来发展的重要趋势,统信软件将继续与生态伙伴紧密合作,持续推动中国操作系统产业高质量发展。
如果您发现该资源为电子书等存在侵权的资源或对该资源描述不正确等,可点击“私信”按钮向作者进行反馈;如作者无回复可进行平台仲裁,我们会在第一时间进行处理!
- 最近热门资源
- 银河麒麟桌面操作系统备份用户数据 125
- 统信桌面专业版【全盘安装UOS系统】介绍 120
- 银河麒麟桌面操作系统安装佳能打印机驱动方法 112
- 银河麒麟桌面操作系统 V10-SP1用户密码修改 105
- 最近下载排行榜
- 银河麒麟桌面操作系统备份用户数据 0
- 统信桌面专业版【全盘安装UOS系统】介绍 0
- 银河麒麟桌面操作系统安装佳能打印机驱动方法 0
- 银河麒麟桌面操作系统 V10-SP1用户密码修改 0

prtyaa 收益393.62元

zlj141319 收益218元

1843880570 收益214.2元

IT-feng 收益209.03元

风晓 收益208.24元

777 收益172.71元

Fhawking 收益106.6元

信创来了 收益105.84元

克里斯蒂亚诺诺 收益91.08元

技术-小陈 收益79.5元
