
ChatIE本质上是将零样本IE任务转变为一个两阶段框架的多轮问答问题(使用的ChatGPT,也可以修改为ChatGLM2),问题是第一阶段和第二阶段如何设计?本质上还是Prompt的设计。接下来都是以RE(关系抽取)为例进行说明,NER(命名实体识别)和EE(事件抽取)以此类推。下面看一个例子,如下所示: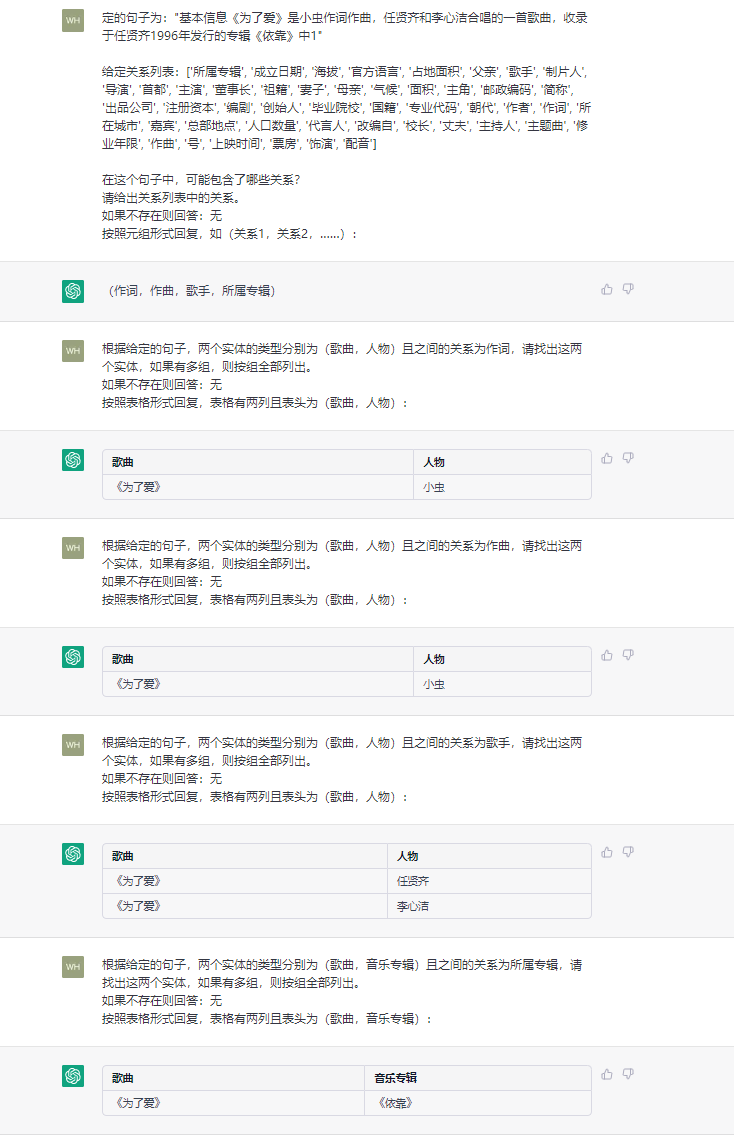
df_ret = {
'chinese': {'所属专辑': ['歌曲', '音乐专辑'], '成立日期': ['机构', 'Date'], '海拔': ['地点', 'Number'], '官方语言': ['国家', '语言'], '占地面积': ['机构', 'Number'], '父亲': ['人物', '人物'],
'歌手': ['歌曲', '人物'], '制片人': ['影视作品', '人物'], '导演': ['影视作品', '人物'], '首都': ['国家', '城市'], '主演': ['影视作品', '人物'], '董事长': ['企业', '人物'], '祖籍': ['人物', '地点'],
'妻子': ['人物', '人物'], '母亲': ['人物', '人物'], '气候': ['行政区', '气候'], '面积': ['行政区', 'Number'], '主角': ['文学作品', '人物'], '邮政编码': ['行政区', 'Text'], '简称': ['机构', 'Text'],
'出品公司': ['影视作品', '企业'], '注册资本': ['企业', 'Number'], '编剧': ['影视作品', '人物'], '创始人': ['企业', '人物'], '毕业院校': ['人物', '学校'], '国籍': ['人物', '国家'],
'专业代码': ['学科专业', 'Text'], '朝代': ['历史人物', 'Text'], '作者': ['图书作品', '人物'], '作词': ['歌曲', '人物'], '所在城市': ['景点', '城市'], '嘉宾': ['电视综艺', '人物'], '总部地点': ['企业', '地点'],
'人口数量': ['行政区', 'Number'], '代言人': ['企业/品牌', '人物'], '改编自': ['影视作品', '作品'], '校长': ['学校', '人物'], '丈夫': ['人物', '人物'], '主持人': ['电视综艺', '人物'], '主题曲': ['影视作品', '歌曲'],
'修业年限': ['学科专业', 'Number'], '作曲': ['歌曲', '人物'], '号': ['历史人物', 'Text'], '上映时间': ['影视作品', 'Date'], '票房': ['影视作品', 'Number'], '饰演': ['娱乐人物', '人物'], '配音': ['娱乐人物', '人物'], '获奖': ['娱乐人物', '奖项']
}
}
1.第一阶段
第一阶段的模板,如下所示:
re_s1_p = {
'chinese': '''给定的句子为:"{}"\n\n给定关系列表:{}\n\n在这个句子中,可能包含了哪些关系?\n请给出关系列表中的关系。\n如果不存在则回答:无\n按照元组形式回复,如 (关系1, 关系2, ……):''',
}
2.第二阶段
第二段的模板,如下所示:
re_s2_p = {
'chinese': '''根据给定的句子,两个实体的类型分别为({},{})且之间的关系为{},请找出这两个实体,如果有多组,则按组全部列出。\n如果不存在则回答:无\n按照表格形式回复,表格有两列且表头为({},{}):''',
}
ChatIE通过两阶段的ChatGPT多轮问答来解决Zero-Shot信息抽取构建知识图谱。但有个问题是可能或一定会出现错误关系抽取,这该如何办呢?工程有个解决方案就是引入多个裁判,比如ChatGPT是一个裁判,文心一言是一个裁判,BERT实体关系抽取是一个裁判,规则实体关系抽取是一个裁判。可根据知识精度要求,比如4个裁判都一致了,才会自动更新到知识库中,否则需要人工来审核实体关系抽取是否正确。知识图谱自动化更新是一个工程活,需要一个人工审核的功能,来确保模型识别不一致时的最终审核。
3.测试效果
ChatIE在不同任务(RE、NER和EE)和不同数据集上的测试效果,如下所示: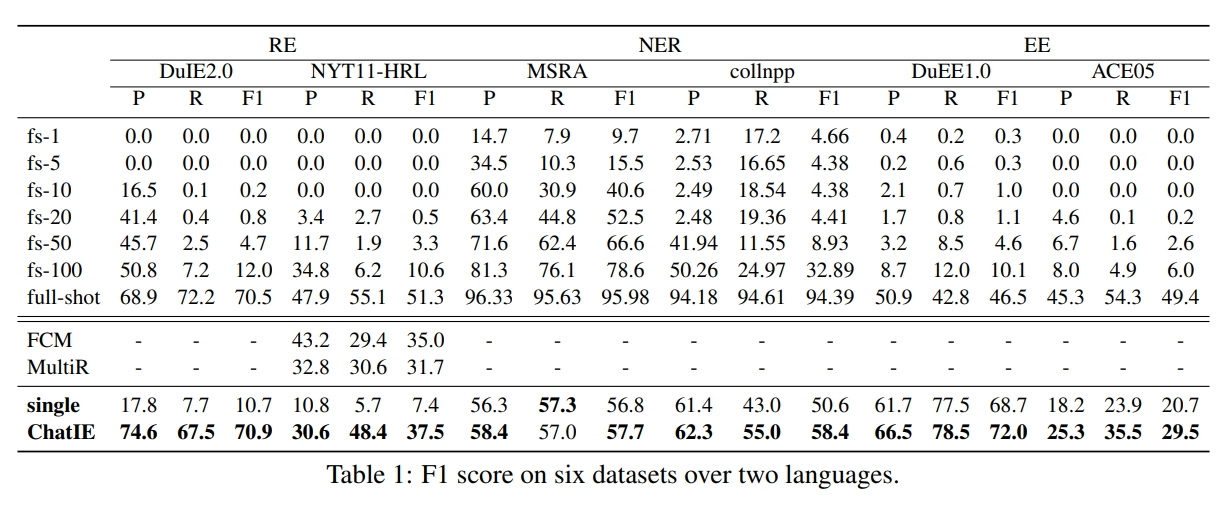
二.使用ChatGLM2来信息抽取[1]
这部分替换ChatGPT为ChatGLM2来做多轮问答。ChatGLM2进行金融知识抽取实践中,在ChatGLM前置了两轮对话达到了较好的效果,具体代码实现参考[9]。基本思路是加载ChatGLM2模型,然后初始化Prompt(分类和信息抽取),最后根据输入和模型完成推理过程。简单理解,整体思路是通过Few-Shot信息抽取构建知识图谱。
(1)加载ChatGLM2模型
tokenizer = AutoTokenizer.from_pretrained(r"L:/20230713_HuggingFaceModel/chatglm2-6b", trust_remote_code=True) # 指定使用的tokenizer
model = AutoModel.from_pretrained(r"L:/20230713_HuggingFaceModel/chatglm2-6b", trust_remote_code=True).half().cuda() # 指定使用的model
model = model.eval() # 指定model为eval模式
(2)初始化Prompt
def init_prompts():
"""
初始化前置prompt,便于模型做 incontext learning。
"""
class_list = list(class_examples.keys()) # 获取分类的类别,class_list = ['基金', '股票']
cls_pre_history = [
(
f'现在你是一个文本分类器,你需要按照要求将我给你的句子分类到:{class_list}类别中。',
f'好的。'
)
]
for _type, exmpale in class_examples.items(): # 遍历分类的类别和例子
cls_pre_history.append((f'“{exmpale}”是 {class_list} 里的什么类别?', _type)) # 拼接前置prompt
ie_pre_history = [
(
"现在你需要帮助我完成信息抽取任务,当我给你一个句子时,你需要帮我抽取出句子中三元组,并按照JSON的格式输出,上述句子中没有的信息用['原文中未提及']来表示,多个值之间用','分隔。",
'好的,请输入您的句子。'
)
]
for _type, example_list in ie_examples.items(): # 遍历分类的类别和例子
for example in example_list: # 遍历例子
sentence = example['content'] # 获取句子
properties_str = ', '.join(schema[_type]) # 拼接schema
schema_str_list = f'“{_type}”({properties_str})' # 拼接schema
sentence_with_prompt = IE_PATTERN.format(sentence, schema_str_list) # 拼接前置prompt
ie_pre_history.append(( # 拼接前置prompt
f'{sentence_with_prompt}',
f"{json.dumps(example['answers'], ensure_ascii=False)}"
))
return {'ie_pre_history': ie_pre_history, 'cls_pre_history': cls_pre_history} # 返回前置prompt
custom_settings数据结构中的内容如下所示: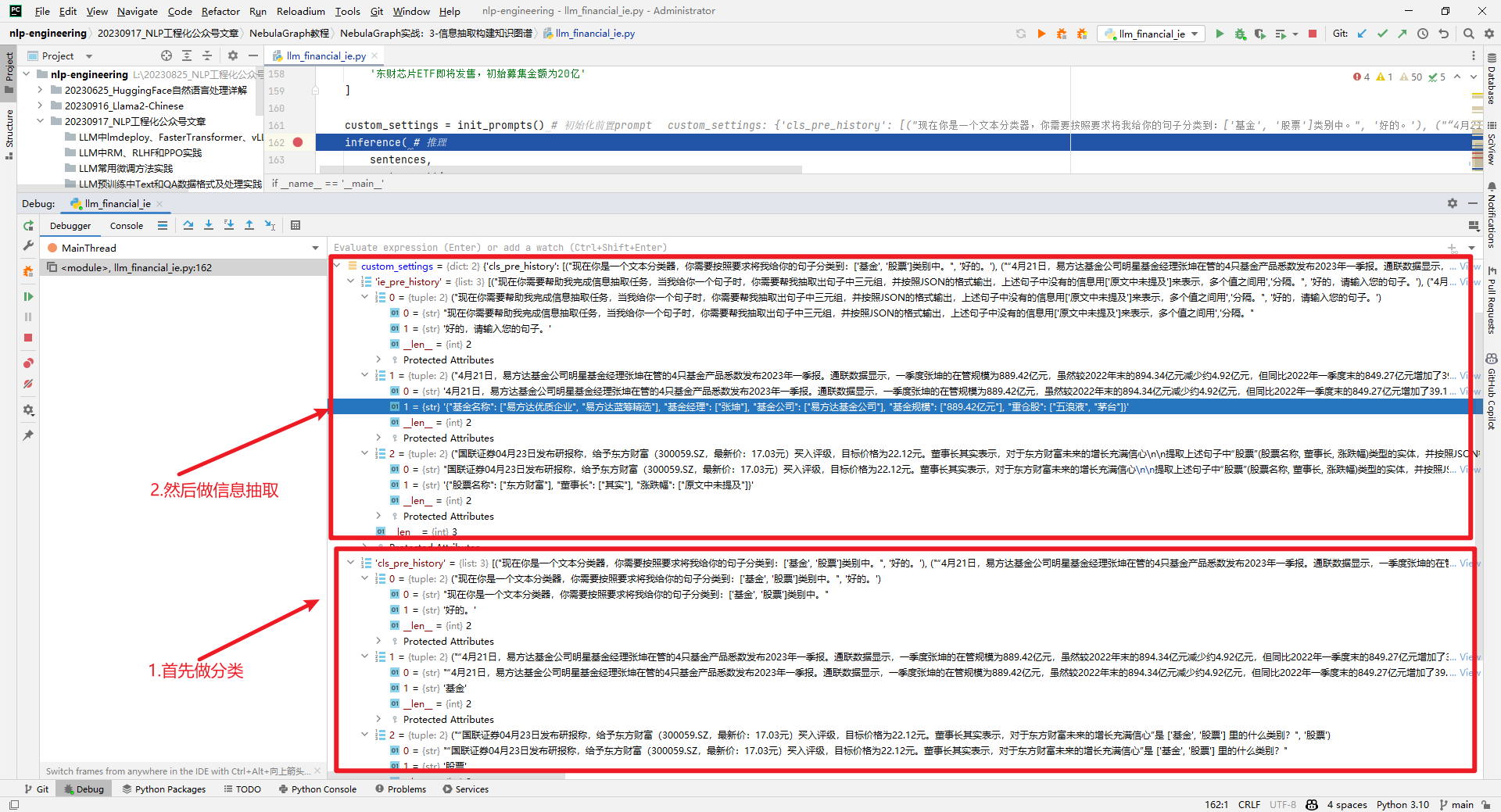 (3)根据输入和模型完成推理过程
(3)根据输入和模型完成推理过程
def inference(
sentences: list,
custom_settings: dict
):
"""
推理函数。
Args:
sentences (List[str]): 待抽取的句子。
custom_settings (dict): 初始设定,包含人为给定的few-shot example。
"""
for sentence in sentences: # 遍历句子
with console.status("[bold bright_green] Model Inference..."): # 显示推理中
sentence_with_cls_prompt = CLS_PATTERN.format(sentence) # 拼接前置prompt
cls_res, _ = model.chat(tokenizer, sentence_with_cls_prompt, history=custom_settings['cls_pre_history']) # 推理
if cls_res not in schema: # 如果推理结果不在schema中,报错并退出
print(f'The type model inferenced {cls_res} which is not in schema dict, exited.')
exit()
properties_str = ', '.join(schema[cls_res]) # 拼接schema
schema_str_list = f'“{cls_res}”({properties_str})' # 拼接schema
sentence_with_ie_prompt = IE_PATTERN.format(sentence, schema_str_list) # 拼接前置prompt
ie_res, _ = model.chat(tokenizer, sentence_with_ie_prompt, history=custom_settings['ie_pre_history']) # 推理
ie_res = clean_response(ie_res) # 后处理
print(f'>>> [bold bright_red]sentence: {sentence}') # 打印句子
print(f'>>> [bold bright_green]inference answer: ') # 打印推理结果
print(ie_res) # 打印推理结果
如果实体关系抽取搞定了,那么自动更新到NebulaGraph就比较简单了。









