面试官:一个 SpringBoot 项目能处理多少请求?(二)
所以我重点带你盘一下这个 offer 方法:
org.apache.Tomcat.util.threads.TaskQueue#offer
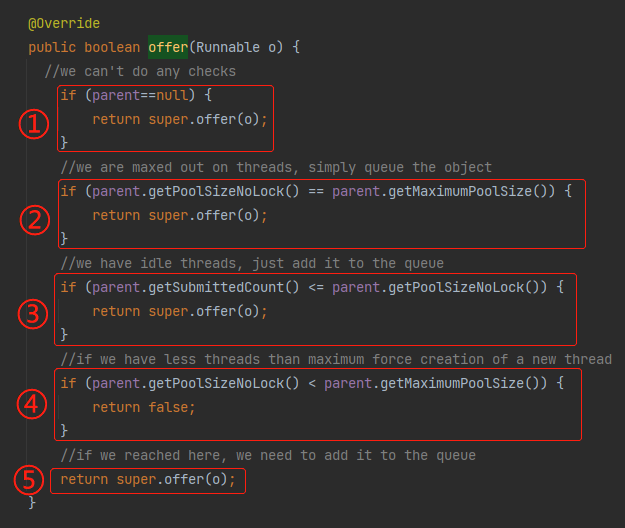
标号为 ① 的地方,判断了 parent 是否为 null,如果是则直接调用父类的 offer 方法。说明要启用这个逻辑,我们的 parent 不能为 null。
那么这个 parent 是什么玩意,从哪里来的呢?
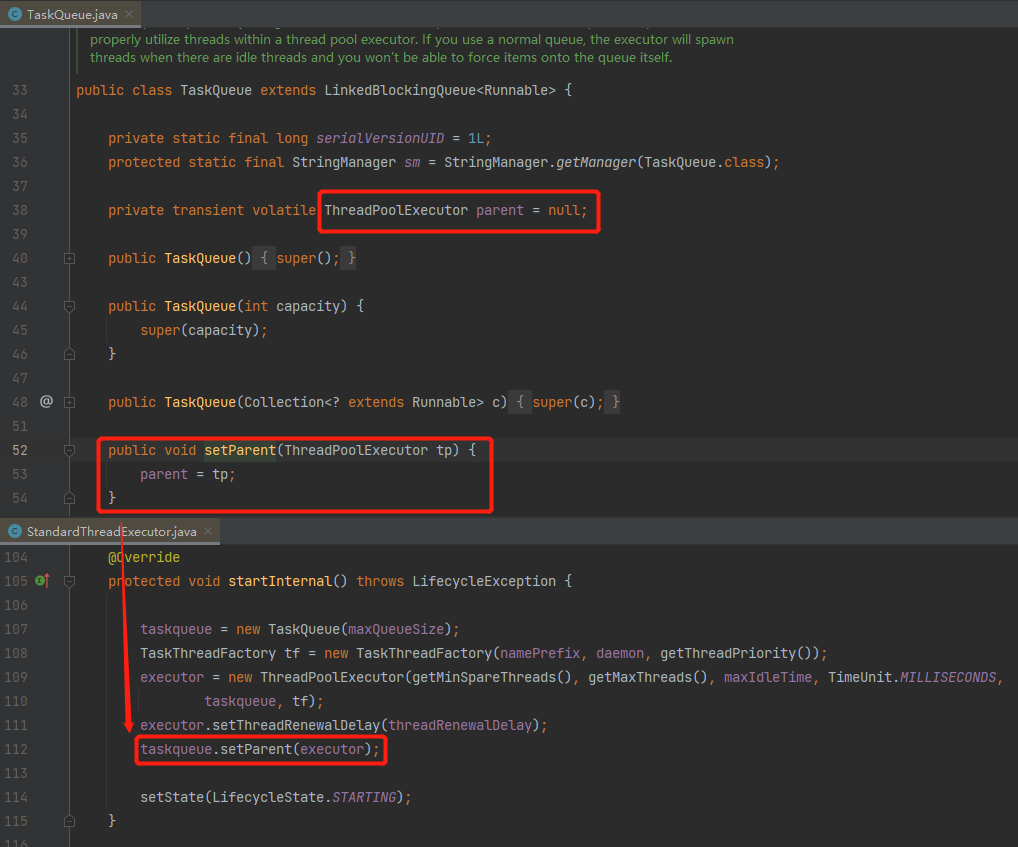
parent 就是 Tomcat 线程池,通过其 set 方法可以知道,是在线程池完成初始化之后,进行了赋值。
也就是说,你可以理解为,在 Tomcat 的场景下,parent 不会为空。
标号为 ② 的地方,调用了 getPoolSizeNoLock 方法:
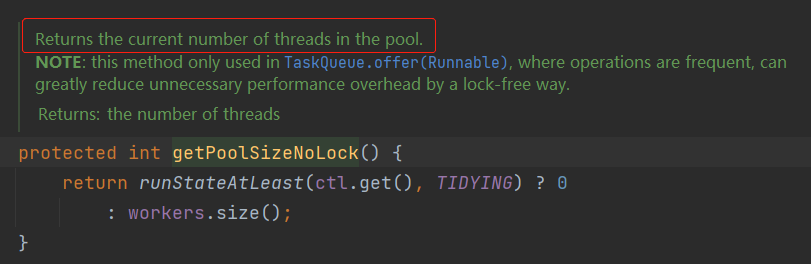
这个方法是获取当前线程池中有多个线程。
所以如果这个表达式为 true:
parent.getPoolSizeNoLock() == parent.getMaximumPoolSize()
就表明当前线程池的线程数已经是配置的最大线程数了,那就调用 offer 方法,把当前请求放到到队列里面去。
标号为 ③ 的地方,是判断已经提交到线程池里面待执行或者正在执行的任务个数,是否比当前线程池的线程数还少。
如果是,则说明当前线程池有空闲线程可以执行任务,则把任务放到队列里面去,就会被空闲线程给取走执行。
然后,关键的来了,标号为 ④ 的地方。
如果当前线程池的线程数比线程池配置的最大线程数还少,则返回 false。
前面说了,offer 方法返回 false,会出现什么情况?
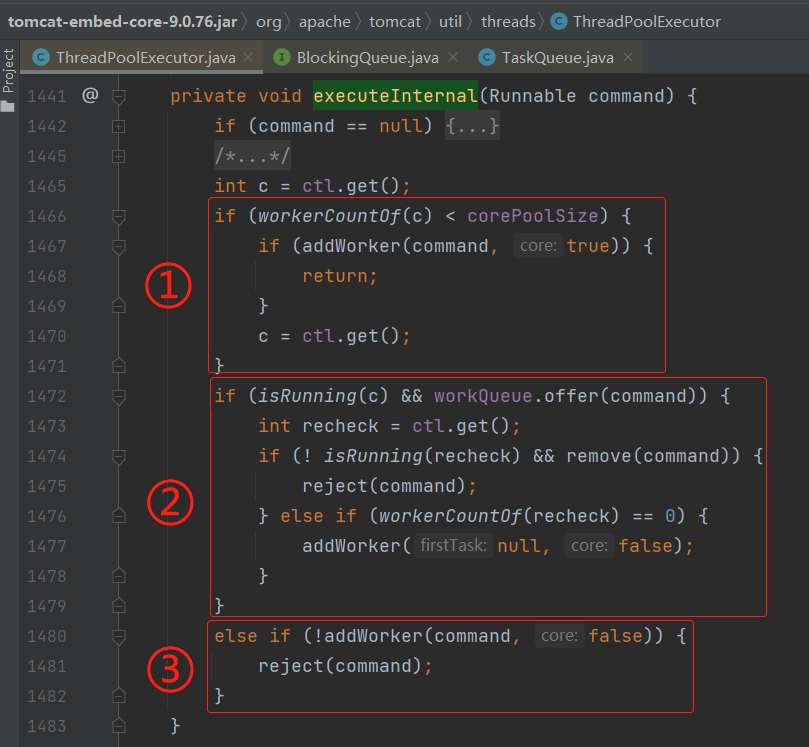
是不是直接开始到上图中标号为 ③ 的地方,去尝试添加非核心线程了?
也就是启用最大线程数这个配置了。
所以,朋友们,这个是什么情况?
这个情况确实就和我们背的线程池的八股文不一样了啊。
JDK 的线程池,是先使用核心线程数配置,接着使用队列长度,最后再使用最大线程配置。
Tomcat 的线程池,就是先使用核心线程数配置,再使用最大线程配置,最后才使用队列长度。
所以,以后当面试官给你说:我们聊聊线程池的工作机制吧?
你就先追问一句:你是说的 JDK 的线程池呢还是 Tomcat 的线程池呢,因为这两个在运行机制上有一点差异。
然后,你就看他的表情。
如果透露出一丝丝迟疑,然后轻描淡写的说一句:那就对比着说一下吧。
那么恭喜你,在这个题目上开始掌握了一点主动权。
最后,为了让你更加深刻的理解到 Tomcat 线程池和 JDK 线程池的不一样,我给你搞一个直接复制过去就能运行的代码。
当你把 taskqueue.setParent(executor) 这行代码注释掉的时候,它的运行机制就是 JDK 的线程池。
当存在这行代码的时候,它的运行机制就变成了 Tomcat 的线程池。
玩去吧。
import org.apache.tomcat.util.threads.TaskQueue;
import org.apache.tomcat.util.threads.TaskThreadFactory;
import org.apache.tomcat.util.threads.ThreadPoolExecutor;
import java.util.concurrent.TimeUnit;
public class TomcatThreadPoolExecutorTest {
public static void main(String[] args) throws InterruptedException {
String namePrefix = "歪歪歪-exec-";
boolean daemon = true;
TaskQueue taskqueue = new TaskQueue(300);
TaskThreadFactory tf = new TaskThreadFactory(namePrefix, daemon, Thread.NORM_PRIORITY);
ThreadPoolExecutor executor = new ThreadPoolExecutor(5,
150, 60000, TimeUnit.MILLISECONDS, taskqueue, tf);
taskqueue.setParent(executor);
for (int i = 0; i < 300; i++) {
try {
executor.execute(() -> {
logStatus(executor, "创建任务");
try {
TimeUnit.SECONDS.sleep(2);
} catch (InterruptedException e) {
e.printStackTrace();
}
});
} catch (Exception e) {
e.printStackTrace();
}
}
Thread.currentThread().join();
}
private static void logStatus(ThreadPoolExecutor executor, String name) {
TaskQueue queue = (TaskQueue) executor.getQueue();
System.out.println(Thread.currentThread().getName() + "-" + name + "-:" +
"核心线程数:" + executor.getCorePoolSize() +
"\t活动线程数:" + executor.getActiveCount() +
"\t最大线程数:" + executor.getMaximumPoolSize() +
"\t总任务数:" + executor.getTaskCount() +
"\t当前排队线程数:" + queue.size() +
"\t队列剩余大小:" + queue.remainingCapacity());
}
}
等等
如果你之前确实没了解过 Tomcat 线程池的工作机制,那么看到这里的时候也许你会觉得确实是有一点点收获。
但是,注意我要说但是了。
还记得最开始的时候面试官的问题吗?
面试官的原问题就是:一个 SpringBoot 项目能同时处理多少请求?
那么请问,前面我讲了这么大一坨 Tomcat 线程池运行原理,这个回答,和这个问题匹配吗?
是的,除了最开始提出的 200 这个数值之外,并不匹配,甚至在面试官的眼里完全是答非所问了。
所以,为了把这两个“并不匹配”的东西比较顺畅的链接起来,你必须要先回答面试官的问题,然后再开始扩展。
比如这样答:一个未进行任何特殊配置,全部采用默认设置的 SpringBoot 项目,这个项目同一时刻最多能同时处理多少请求,取决于我们使用的 web 容器,而 SpringBoot 默认使用的是 Tomcat。
Tomcat 的默认核心线程数是 10,最大线程数 200,队列长度是无限长。但是由于其运行机制和 JDK 线程池不一样,在核心线程数满了之后,会直接启用最大线程数。所以,在默认的配置下,同一时刻,可以处理 200 个请求。
在实际使用过程中,应该基于服务实际情况和服务器配置等相关消息,对该参数进行评估设置。
这个回答就算是差不多了。
但是,如果很不幸,如果你遇到了我,为了验证你是真的自己去摸索过,还是仅仅只是看了几篇文章,我可能还会追问一下:
那么其他什么都不动,如果我仅仅加入 server.tomcat.max-connections=10 这个配置呢,那么这个时候最多能处理多少个请求?
你可能就要猜了:10 个。
是的,我重新提交 1000 个任务过来,在控制台输出的确实是 10 个,
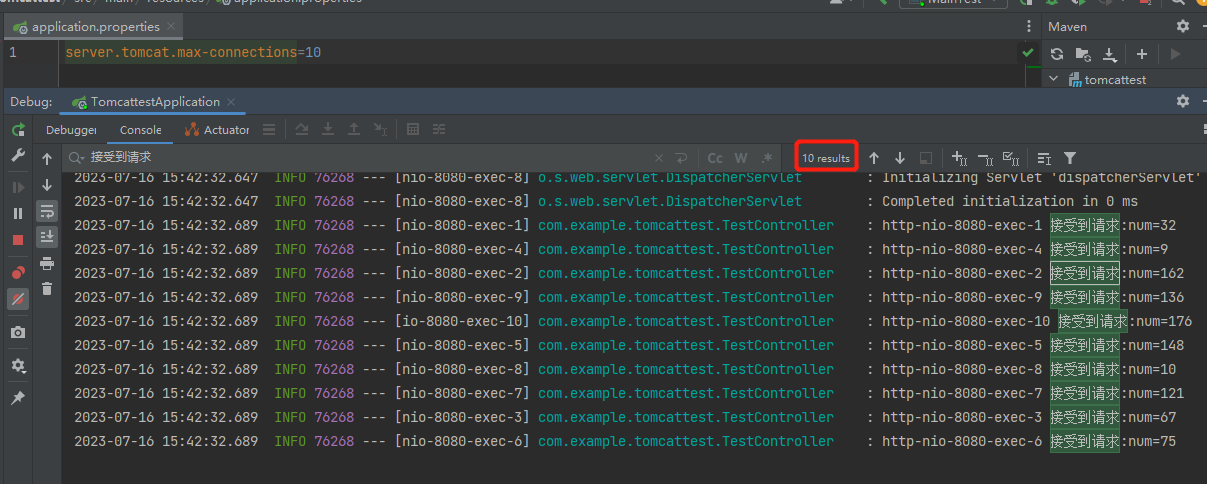
那么 max-connections 这个参数它怎么也能控制请求个数呢?
为什么在前面的分析过程中我们并没有注意到这个参数呢?
首先我们看一下它的默认值:

因为它的默认值是 8192,比最大线程数 200 大,这个参数并没有限制到我们,所以我们没有关注到它。
当我们把它调整为 10 的时候,小于最大线程数 200,它就开始变成限制项了。
那么 max-connections 这个参数到底是干啥的呢?
你先自己去摸索摸索吧。
同时,还有这样的一个参数,默认是 100:
server.tomcat.accept-count=100

它又是干什么的呢?
“和连接数有关”,我只能提示到这里了,自己去摸索吧。

再等等
通过前面的分析,我们知道了,要回答“一个 SpringBoot 项目默认能处理的任务数”,这个问题,得先明确其使用的 web 容器。
那么问题又来了:SpringBoot 内置了哪些容器呢?
Tomcat、Jetty、Netty、Undertow
前面我们都是基于 Tomcat 分析的,如果我们换一个容器呢?
比如换成 Undertow,这个玩意我只是听过,没有实际使用过,它对我来说就是一个黑盒。
管它的,先换了再说。
从 Tomcat 换成 Undertow,只需要修改 Maven 依赖即可,其他什么都不需要动:
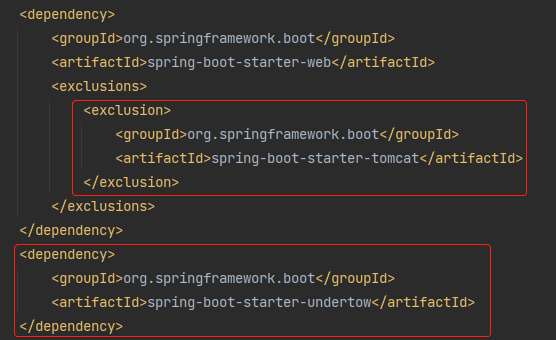
再次启动项目,从日志可以发现已经修改为了 Undertow 容器:
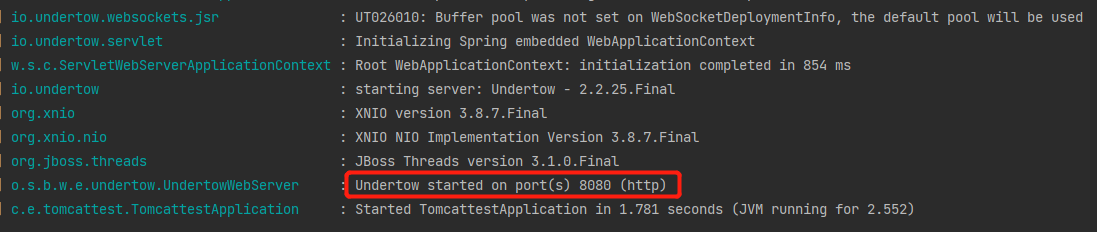
此时我再次执行 MainTest 方法,还是提交 1000 个请求:
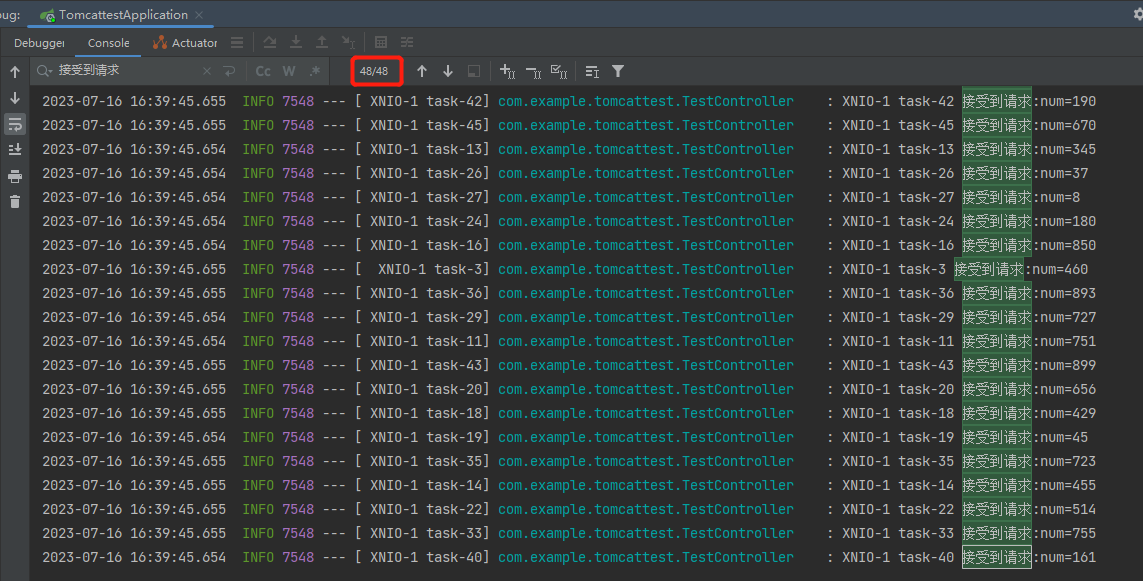
从日志来看,发现只有 48 个请求被处理了。
就很懵逼,48 是怎么回事儿,怎么都不是一个整数呢,这让强迫症很难受啊。
这个时候你的想法是什么,是不是想要看看 48 这个数字到底是从哪里来的?
怎么看?
之前找 Tomcat 的 200 的时候不是才教了你的嘛,直接往 Undertow 上套就行了嘛。
打线程 Dump,然后看堆栈消息:
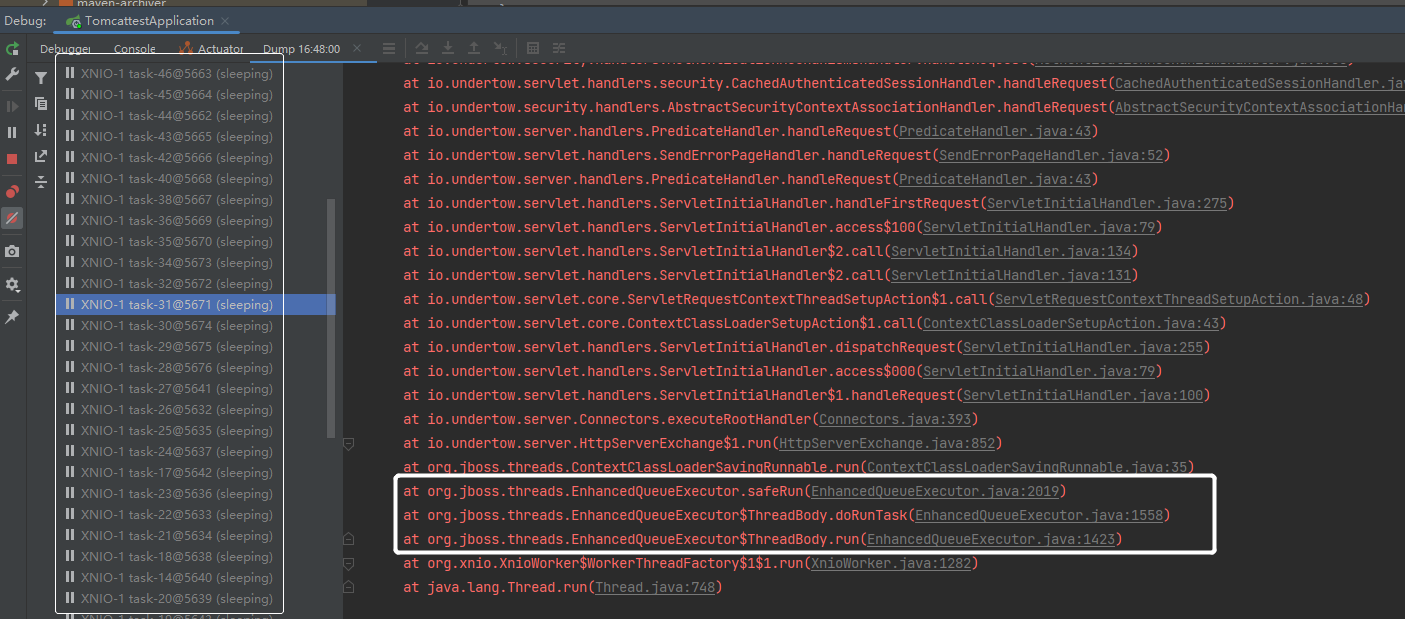
发现 EnhancedQueueExecutor 这个线程池,接着在这个类里面去找构建线程池时的参数。
很容易就找到了这个构造方法:
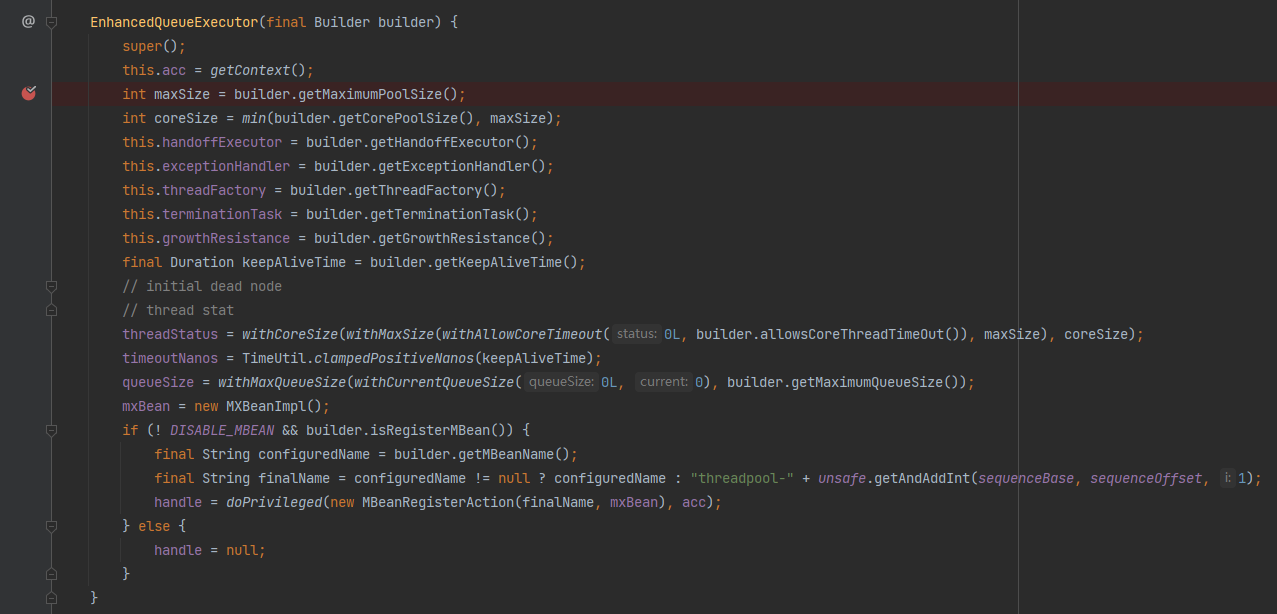
所以,在这里打上断点,重启项目。
通过 Debug 可以知道,关键参数都是从 builder 里面来的。
而 builder 里面,coreSize 和 maxSize 都是 48,队列长度是 Integer.MAX_VALUE。
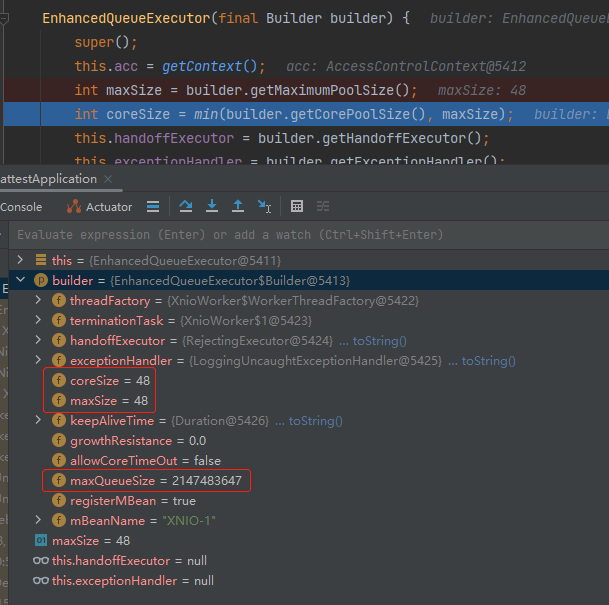
所以看一下 Builder 里面的 coreSize 是怎么来的。
点过来发现 coreSize 的默认值是 16:
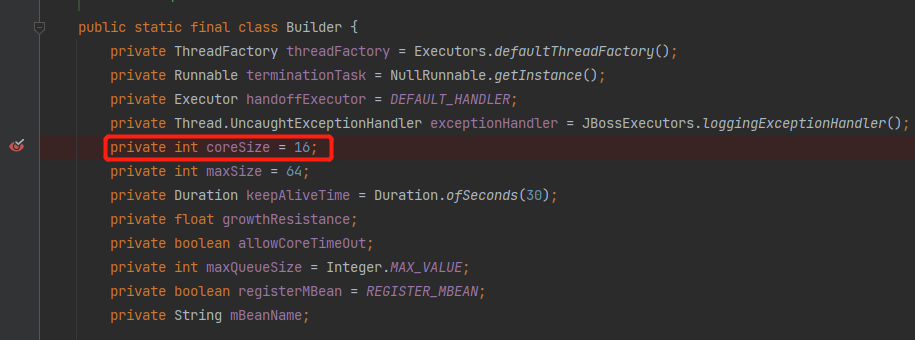
不要慌,再打断点,再重启项目。
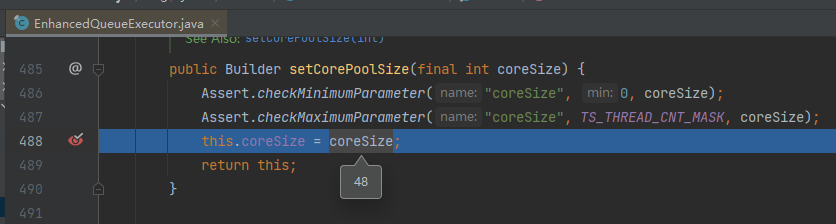
然后你会在它的 setCorePoolSize 方法处停下来,而这个方法的入参就是我们要找的 48:
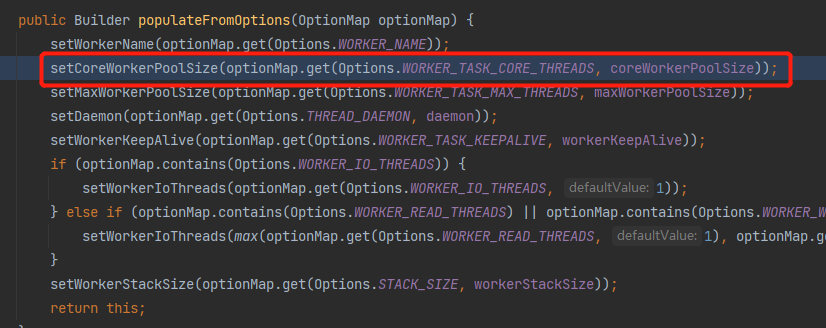
顺藤摸瓜,重复几次打断点、重启的动作之后,你会找到 48 是一个名为 WORKER_TASK_CORE_THREADS 的变量,是从这里来的:
而 WORKER_TASK_CORE_THREADS 这个变量设置的地方是这样的:
io.undertow.Undertow#start
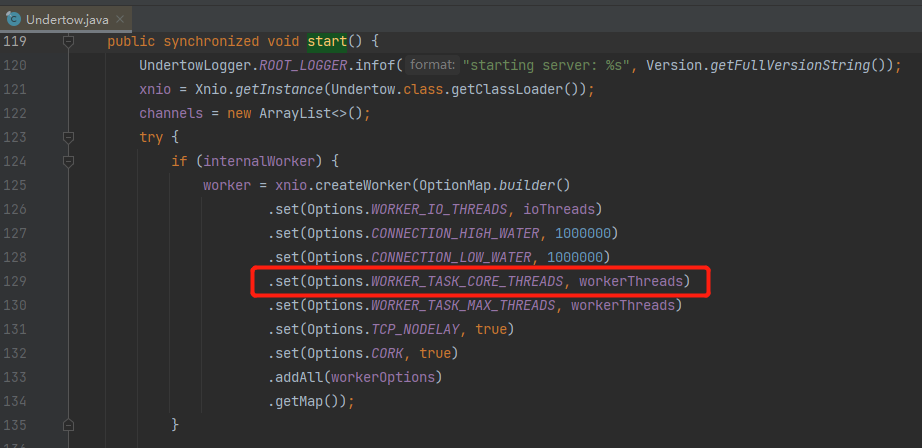
而这里的 workerThreads 取值是这样的:
io.undertow.Undertow.Builder#Builder
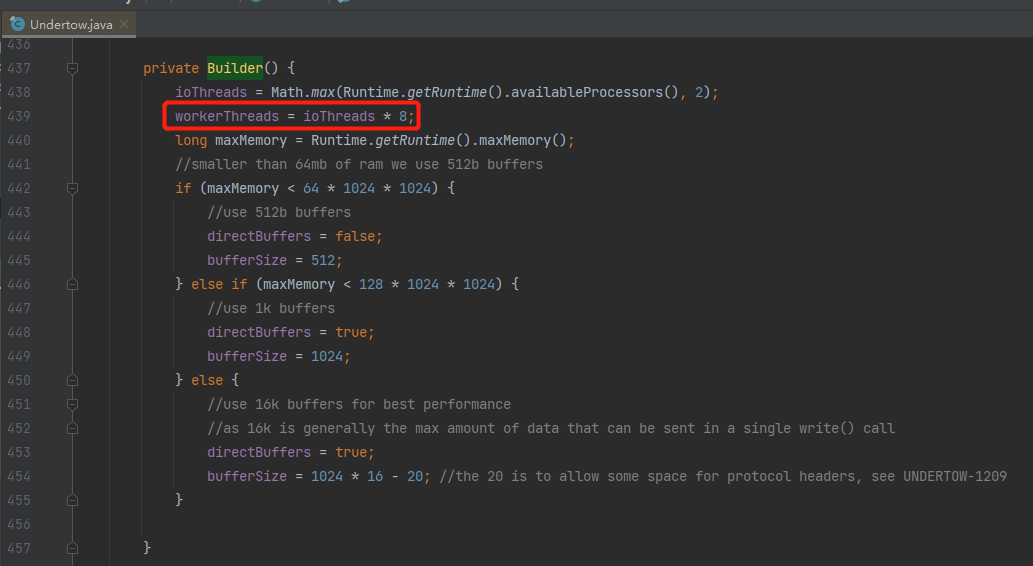
取的是机器的 CPU 个数乘以 8。
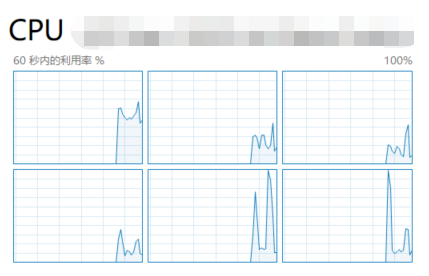
所以我这里是 6*8=48。
哦,真相大白,原来 48 是这样来的。
没意思。
确实没意思,但是既然都已经替换为 Undertow 了,那么你去研究一下它的 NIO ByteBuffer、NIO Channel、BufferPool、XNIO Worker、IO 线程池、Worker 线程池...
然后再和 Tomcat 对比着学,
就开始有点意思了。

最后再等等
这篇文章是基于“一个 SpringBoot 项目能同时处理多少请求?”这个面试题出发的。
但是经过我们前面简单的分析,你也知道,这个问题如果在没有加一些特定的前提条件的情况下,答案是各不一样的。
比如我再给你举一个例子,还是我们的 Demo,只是使用一下 @Async 注解,其他什么都不变:
再次启动项目,发起访问,日志输出变成了这样:
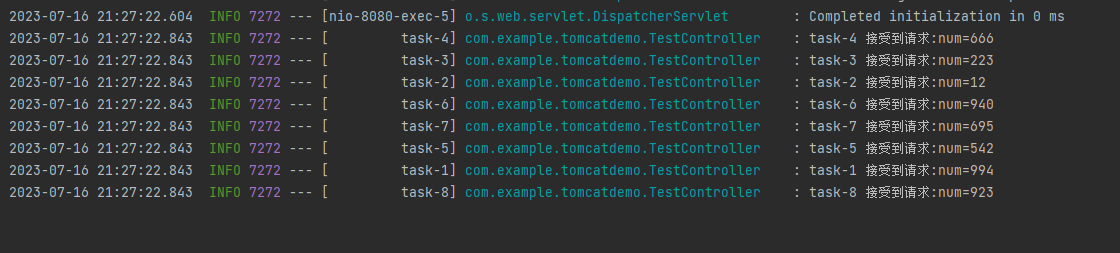
同时能处理的请求,直接从 Tomcat 的默认 200 个变成了 8 个?
因为 @Async 注解对应的线程池,默认的核心线程数是 8。
之前写过这篇文章《别问了,我真的不喜欢@Async这个注解!》分析过这个注解。
所以你看,稍微一变化,答案看起来又不一样了,同时这个请求在内部流转的过程也不一样了,又是一个可以铺开谈的点。
在面试过程中也是这样的,不要急于答题,当你觉得面试官问题描述的不清楚的地方,你可以先试探性的问一下,看看能不能挖掘出一点他没有说出来的默认条件。
当“默认条件”挖掘的越多,你的回答就会更容易被面试官接受。而这个挖掘的过程,也是面试过程中一个重要的表现环节。
而且,有时候,面试官就喜欢给出这样的“模糊”的问题,因为问题越模糊,坑就越多,当面试者跳进自己挖好的坑里面的时候,就是结束一次交锋的时候;当面试者看出来自己挖好的坑,并绕过去的时候,也是结束一轮交锋的时候。
所以,不要急于答题,多想,多问。不管是对于面试者还是面试官,一个好的面试体验,一定不是没有互动的一问一答,而是一个相互拉锯的过程。
如果您发现该资源为电子书等存在侵权的资源或对该资源描述不正确等,可点击“私信”按钮向作者进行反馈;如作者无回复可进行平台仲裁,我们会在第一时间进行处理!
- 最近热门资源
- 银河麒麟桌面操作系统备份用户数据 127
- 统信桌面专业版【全盘安装UOS系统】介绍 122
- 银河麒麟桌面操作系统安装佳能打印机驱动方法 114
- 银河麒麟桌面操作系统 V10-SP1用户密码修改 105
- 最近下载排行榜
- 银河麒麟桌面操作系统备份用户数据 0
- 统信桌面专业版【全盘安装UOS系统】介绍 0
- 银河麒麟桌面操作系统安装佳能打印机驱动方法 0
- 银河麒麟桌面操作系统 V10-SP1用户密码修改 0

prtyaa 收益393.62元

zlj141319 收益218元

1843880570 收益214.2元

IT-feng 收益209.03元

风晓 收益208.24元

777 收益172.71元

Fhawking 收益106.6元

信创来了 收益105.84元

克里斯蒂亚诺诺 收益91.08元

技术-小陈 收益79.5元
