Py之scikit-learn:机器学习Sklearn库的简介、安装、使用方法(ML算法如何选择)、代码实现之详细攻略

Py之scikit-learn:机器学习Sklearn库的简介、安装、使用方法、代码实现之详细攻略
目录
scikit-learn的简介
Scikit-learn项目最早由数据科学家 David Cournapeau 在 2007 年发起,需要NumPy和SciPy等其他包的支持,是Python语言中专门针对机器学习应用而发展起来的一款开源框架。
Scikit-learn依托于Numpy、Scipy等几种工具包,封装大量经典以及最新的机器学习模型。该接口最早由David Cournapeau在2007年Google夏季代码节中提出并启动。后来作为Matthieu Brucher博士工作的一部分得以延续和完善。现在已经是相对成熟的机器学习开源项目。近十年来,有超过20位计算机专家参与其代码的更新和维护工作。作为一款用于机器学习和实践的Python第只方开源程序库,Scikit-learn因其出色的接口设计和高效的学习能力,尤其受ML爱好者的欢迎。
和其他众多的开源项目一样,Scikit-learn目前主要由社区成员自发进行维护。可能是由于维护成本的限制,Scikit-learn相比其他项目要显得更为保守。这主要体现在两个方面:一是Scikit-learn从来不做除机器学习领域之外的其他扩展,二是Scikit-learn从来不采用未经广泛验证的算法。
Scikit-learn的基本功能主要被分为六大部分:
分类,回归,聚类,数据降维,模型选择和数据预处理。
- 1、分类:是指识别给定对象的所属类别,属于监督学习的范畴,最常见的应用场景包括垃圾邮件检测和图像识别等。目前Scikit-learn已经实现的算法包括:支持向量机(SVM),最近邻,逻辑回归,随机森林,决策树以及多层感知器(MLP)神经网络等等。 需要指出的是,由于Scikit-learn本身不支持深度学习,也不支持GPU加速,因此这里对于MLP的实现并不适合于处理大规模问题。有相关需求的读者可以查看同样对Python有良好支持的Keras和Theano等框架。
- 2、回归:是指预测与给定对象相关联的连续值属性,最常见的应用场景包括预测药物反应和预测股票价格等。目前Scikit-learn已经实现的算法包括:支持向量回归(SVR),脊回归,Lasso回归,弹性网络(Elastic Net),最小角回归(LARS ),贝叶斯回归,以及各种不同的鲁棒回归算法等。可以看到,这里实现的回归算法几乎涵盖了所有开发者的需求范围,而且更重要的是,Scikit-learn还针对每种算法都提供了简单明了的用例参考。
- 3、聚类:是指自动识别具有相似属性的给定对象,并将其分组为集合,属于无监督学习的范畴,最常见的应用场景包括顾客细分和试验结果分组。目前Scikit-learn已经实现的算法包括:K-均值聚类,谱聚类,均值偏移,分层聚类,DBSCAN聚类等。
- 4、数据降维:是指使用主成分分析(PCA)、非负矩阵分解(NMF)或特征选择等降维技术来减少要考虑的随机变量的个数,其主要应用场景包括可视化处理和效率提升。
- 5、模型选择
- 是指对于给定参数和模型的比较、验证和选择,其主要目的是通过参数调整来提升精度。目前Scikit-learn实现的模块包括:格点搜索,交叉验证和各种针对预测误差评估的度量函数。
- 6、数据预处理:是指数据的特征提取和归一化,是机器学习过程中的第一个也是最重要的一个环节。这里归一化是指将输入数据转换为具有零均值和单位权方差的新变量,但因为大多数时候都做不到精确等于零,因此会设置一个可接受的范围,一般都要求落在0-1之间。而特征提取是指将文本或图像数据转换为可用于机器学习的数字变量。 需要特别注意的是,这里的特征提取与上文在数据降维中提到的特征选择非常不同。特征选择是指通过去除不变、协变或其他统计上不重要的特征量来改进机器学习的一种方法。 总结来说,Scikit-learn实现了一整套用于数据降维,模型选择,特征提取和归一化的完整算法/模块,虽然缺少按步骤操作的参考教程,但Scikit-learn针对每个算法和模块都提供了丰富的参考样例和详细的说明文档。
scikit-learn的安装
- pip install scikit-learn
- pip install scikit-learn==0.23.1
- pip install scikit-learn==0.19.1

成功安装,哈哈!
scikit-learn的使用方法
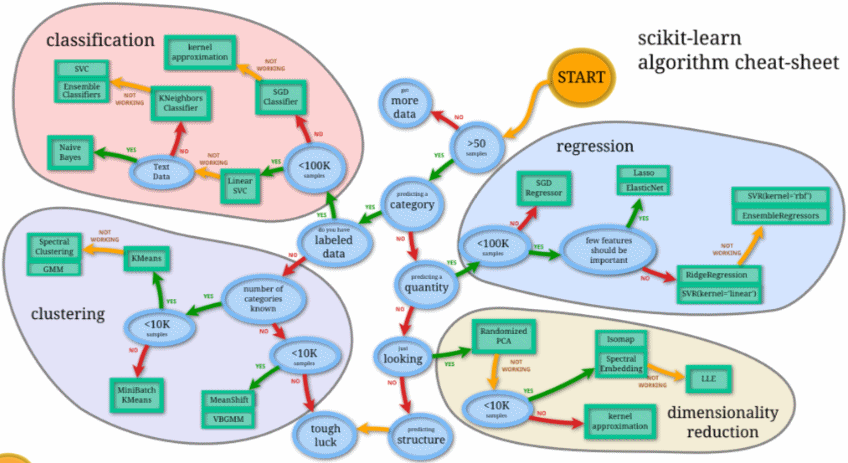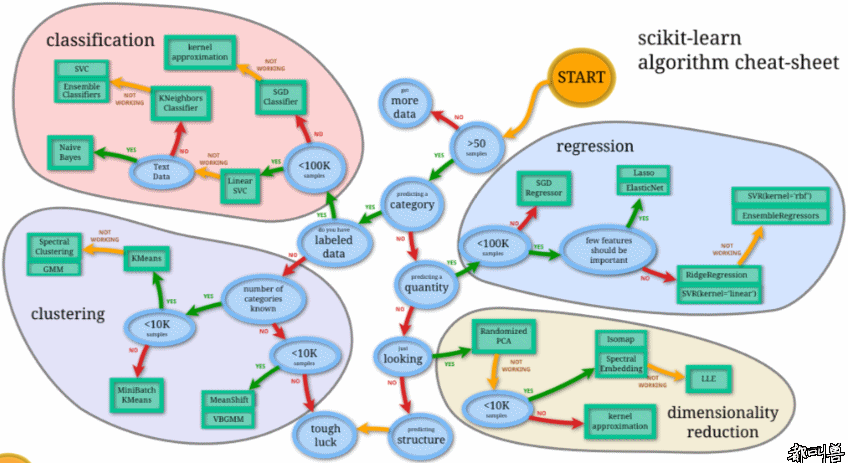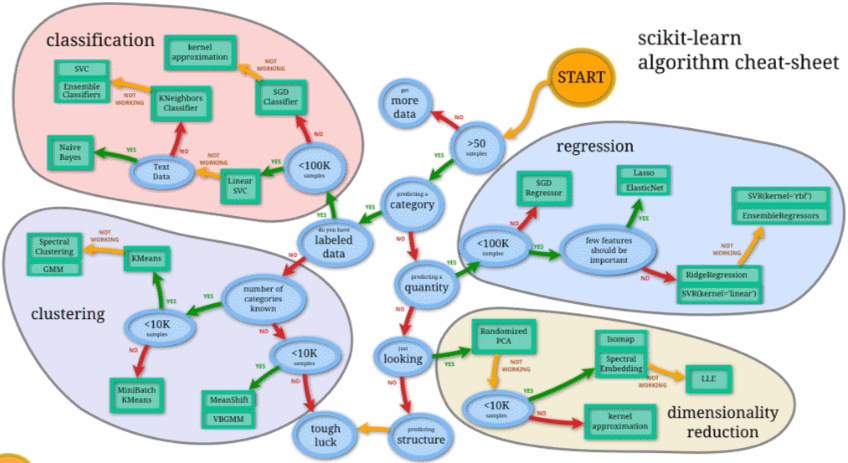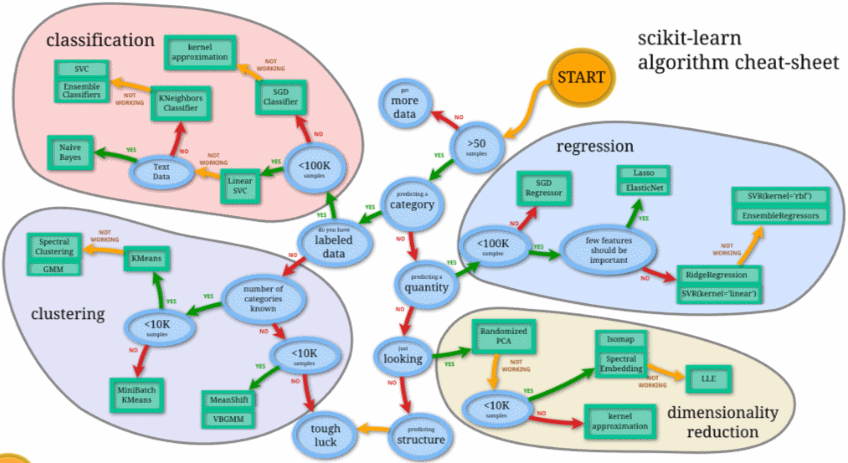
scikit-learn algorithm cheat-sheet
选择正确的估计量:解决机器学习问题的最困难的部分通常是为工作找到正确的估计量。不同的估计量更适合于不同类型的数据和不同的问题。下面的流程图旨在为用户提供一个关于如何处理问题的粗略指南,这些问题涉及到哪些评估人员要尝试您的数据。点击下表中的任何估算器查看其文档。
地址:Choosing the right estimator — scikit-learn 1.0.1 documentation

相关文章推荐
scikit-learn与机器学习的那些不可告密的七七八八事
scikit-learn与深度学习的那些不可告密的七七八八事
网站声明:如果转载,请联系本站管理员。否则一切后果自行承担。
- 上周热门
- 如何使用 StarRocks 管理和优化数据湖中的数据? 2935
- 【软件正版化】软件正版化工作要点 2854
- 统信UOS试玩黑神话:悟空 2811
- 信刻光盘安全隔离与信息交换系统 2702
- 镜舟科技与中启乘数科技达成战略合作,共筑数据服务新生态 1235
- grub引导程序无法找到指定设备和分区 1205
- 点击报名 | 京东2025校招进校行程预告 162
- 华为全联接大会2024丨软通动力分论坛精彩议程抢先看! 160
- 2024海洋能源产业融合发展论坛暨博览会同期活动-海洋能源与数字化智能化论坛成功举办 156
- 华为纯血鸿蒙正式版9月底见!但Mate 70的内情还得接着挖... 154
- 本周热议
- 我的信创开放社区兼职赚钱历程 40
- 今天你签到了吗? 27
- 信创开放社区邀请他人注册的具体步骤如下 15
- 如何玩转信创开放社区—从小白进阶到专家 15
- 方德桌面操作系统 14
- 我有15积分有什么用? 13
- 用抖音玩法闯信创开放社区——用平台宣传企业产品服务 13
- 如何让你先人一步获得悬赏问题信息?(创作者必看) 12
- 2024中国信创产业发展大会暨中国信息科技创新与应用博览会 9
- 中央国家机关政府采购中心:应当将CPU、操作系统符合安全可靠测评要求纳入采购需求 8
