DL之Keras:基于Keras框架建立模型实现【预测】功能的简介、设计思路、案例分析、代码实现之详细攻略(经典,建议收藏)

DL之Keras:基于Keras框架建立模型实现【预测】功能的简介、设计思路、案例分析、代码实现之详细攻略(经典,建议收藏)
目录
Keras框架使用分析
Keras框架设计思路
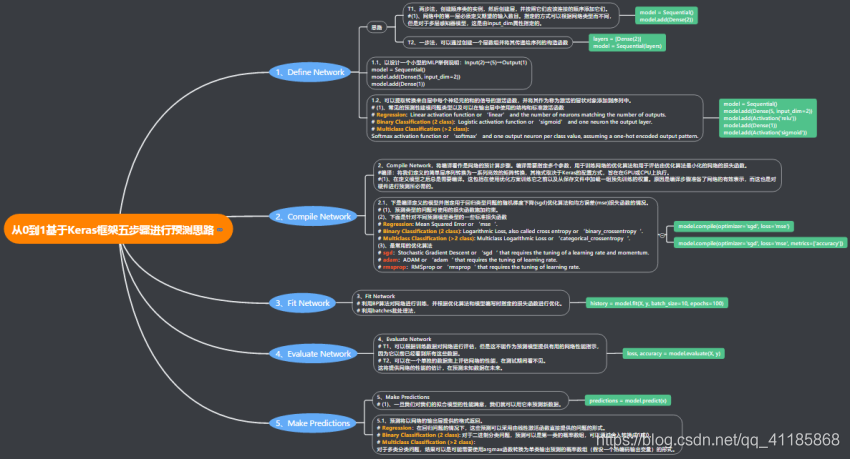
案例分析
1、实现分类预测:通过Keras建立模型,最终得到的模型能进行两种预测,一是判断出类别,二是给出属于相应类别概率。
(1)、在Keras中,可以利用predict_class()函数来完成,利用最终的模型预测新数据样本的类别。但是,这个函数仅适用于Sequential模型,不适于使用功能式API开发的模型。
对三个实例预测:
- 建立一个新的分类模型
- from keras.models import Sequential
- from keras.layers import Dense
- from sklearn.datasets.samples_generator import make_blobs
- from sklearn.preprocessing import MinMaxScaler
- 生成二分类数据集
- X, y = make_blobs(n_samples=100, centers=2, n_features=2, random_state=1)
- scalar = MinMaxScaler()
- scalar.fit(X)
- X = scalar.transform(X)
- 定义并拟合最终模型
- model = Sequential()
- model.add(Dense(4, input_dim=2, activation='relu'))
- model.add(Dense(4, activation='relu'))
- model.add(Dense(1, activation='sigmoid'))
- model.compile(loss='binary_crossentropy', optimizer='adam')
- model.fit(X, y, epochs=500, verbose=0)
- 新的未知数据实例
- Xnew, _ = make_blobs(n_samples=3, centers=2, n_features=2, random_state=1)
- Xnew = scalar.transform(Xnew)
- 作出预测
- ynew = model.predict_classes(Xnew)
- 显示输入和输出
- for i in range(len(Xnew)):
- print("X=%s, Predicted=%s" % (Xnew[i], ynew[i]))
对一个实例预测:需要将它包装变成一个数组的形式。以便传给predict_classes()函数
- from keras.models import Sequential
- from keras.layers import Dense
- from sklearn.datasets.samples_generator import make_blobs
- from sklearn.preprocessing import MinMaxScaler
- from numpy import array
- 生成一个二分类数据集
- X, y = make_blobs(n_samples=100, centers=2, n_features=2, random_state=1)
- scalar = MinMaxScaler()
- scalar.fit(X)
- X = scalar.transform(X)
- 定义并拟合最终的新模型
- model = Sequential()
- model.add(Dense(4, input_dim=2, activation='relu'))
- model.add(Dense(4, activation='relu'))
- model.add(Dense(1, activation='sigmoid'))
- model.compile(loss='binary_crossentropy', optimizer='adam')
- model.fit(X, y, epochs=500, verbose=0)
- 未知的新实例
- Xnew = array([[0.89337759, 0.65864154]])
- 作出预测
- ynew = model.predict_classes(Xnew)
- 显示输入输出
- print("X=%s, Predicted=%s" % (Xnew[0], ynew[0]))
代码实现
1、基于Keras设计的简单二分类问题开发的神经网络模型案例
- 训练一个最终分类的模型
- from keras.models import Sequential
- from keras.layers import Dense
- from sklearn.datasets.samples_generator import make_blobs
- from sklearn.preprocessing import MinMaxScaler
- 生成一个二分类问题的数据集
- X, y = make_blobs(n_samples=100, centers=2, n_features=2, random_state=1)
- scalar = MinMaxScaler()
- scalar.fit(X)
- X = scalar.transform(X)
- 定义并拟合模型
- model = Sequential()
- model.add(Dense(4, input_dim=2, activation='relu'))
- model.add(Dense(4, activation='relu'))
- model.add(Dense(1, activation='sigmoid'))
- model.compile(loss='binary_crossentropy', optimizer='adam')
- model.fit(X, y, epochs=200, verbose=0)
网站声明:如果转载,请联系本站管理员。否则一切后果自行承担。
赞同 0
评论 0 条
- 上周热门
- 如何使用 StarRocks 管理和优化数据湖中的数据? 2951
- 【软件正版化】软件正版化工作要点 2872
- 统信UOS试玩黑神话:悟空 2833
- 信刻光盘安全隔离与信息交换系统 2728
- 镜舟科技与中启乘数科技达成战略合作,共筑数据服务新生态 1261
- grub引导程序无法找到指定设备和分区 1226
- 华为全联接大会2024丨软通动力分论坛精彩议程抢先看! 165
- 2024海洋能源产业融合发展论坛暨博览会同期活动-海洋能源与数字化智能化论坛成功举办 163
- 点击报名 | 京东2025校招进校行程预告 163
- 华为纯血鸿蒙正式版9月底见!但Mate 70的内情还得接着挖... 159
- 本周热议
- 我的信创开放社区兼职赚钱历程 40
- 今天你签到了吗? 27
- 如何玩转信创开放社区—从小白进阶到专家 15
- 信创开放社区邀请他人注册的具体步骤如下 15
- 方德桌面操作系统 14
- 用抖音玩法闯信创开放社区——用平台宣传企业产品服务 13
- 我有15积分有什么用? 13
- 如何让你先人一步获得悬赏问题信息?(创作者必看) 12
- 2024中国信创产业发展大会暨中国信息科技创新与应用博览会 9
- 中央国家机关政府采购中心:应当将CPU、操作系统符合安全可靠测评要求纳入采购需求 8
热门标签更多
