面试题:说说Redis的三大问题和解决方案

Redis经常用于系统中的缓存,这样可以解决目前IO设备无法满足互联网应用海量的读写请求的问题。
一、缓存穿透
缓存穿透是指缓存和数据库中都没有的数据,而用户不断发起请求,如发起id为-1的数据或者特别大的不存在的数据。有可能是黑客利用漏洞攻击从而去压垮应用的数据库。
1. 常见解决方案
对于缓存穿透问题,常见的解决方案有以下三种:
- 验证拦截:接口层进行校验,如鉴定用户权限,对ID之类的字段做基础的校验,如
id<=0的字段直接拦截; - 缓存空数据:当数据库查询到的数据为空时,也将这条数据进行缓存,但缓存的有效性设置得要较短,以免影响正常数据的缓存;
Copypublic Student getStudentsByID(Long id) {
// 从Redis中获取学生信息
Student student = redisTemplate.opsForValue()
.get(String.valueOf(id));
if (student != null) {
return student;
}
// 从数据库查询学生信息,并存入Redis
student = studentDao.selectByStudentId(id);
if (student != null) {
redisTemplate.opsForValue()
.set(String.valueOf(id), student, 60, TimeUnit.MINUTES);
} else {
// 即使不存在,也将 null 存入缓存中
redisTemplate.opsForValue()
.set(String.valueOf(id), null, 60, TimeUnit.SECONDS);
}
return student;
}
- 使用布隆过滤器:布隆过滤器是一种比较独特数据结构,有一定的误差。当它指定一个数据存在时,它不一定存在,但是当它指定一个数据不存在时,那么它一定是不存在的。
2. 布隆过滤器
布隆过滤器是一种比较特殊的数据结构,有点类似与HashMap,在业务中我们可能会通过使用HashMap来判断一个值是否存在,它可以在O(1)时间复杂度内返回结果,效率极高,但是受限于存储容量,如果可能需要去判断的值超过亿级别,那么HashMap所占的内存就很可观了。
而BloomFilter解决这个问题的方案很简单。首先用多个bit位去代替HashMap中的数组,这样的话储存空间就下来了,之后就是对 Key 进行多次哈希,将 Key 哈希后的值所对应的 bit 位置为1。
当判断一个元素是否存在时,就去判断这个值哈希出来的比特位是否都为1,如果都为1,那么可能存在,也可能不存在(如下图F)。但是如果有一个bit位不为1,那么这个Key就肯定不存在。
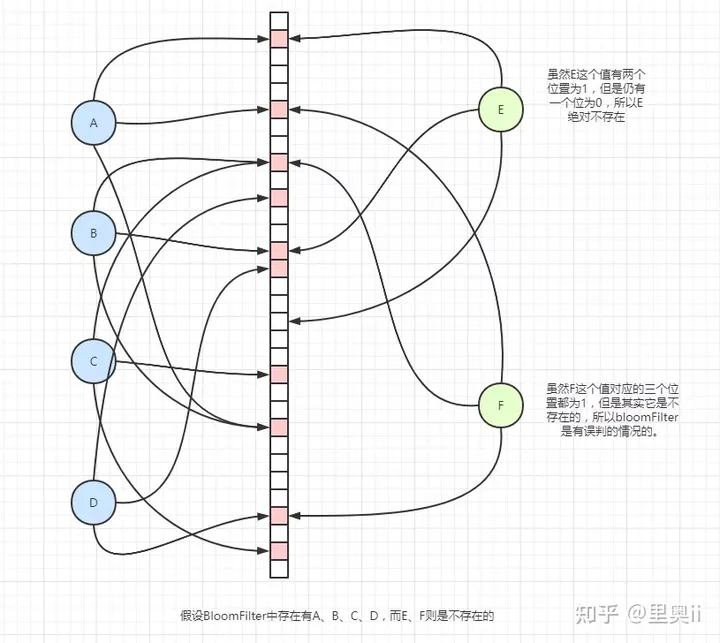
注意:BloomFilter并不支持删除操作,只支持添加操作。这一点很容易理解,因为你如果要删除数据,就得将对应的bit位置为0,但是你这个Key对应的bit位可能其他的Key也对应着。
3. 缓存空数据与布隆过滤器的比较
上面对这两种方案都进行了简单的介绍,缓存空数据与布隆过滤器都能有效解决缓存穿透问题,但使用场景有着些许不同;
- 当一些恶意攻击查询查询的key各不相同,而且数量巨多,此时缓存空数据不是一个好的解决方案。因为它需要存储所有的Key,内存空间占用高。并且在这种情况下,很多key可能只用一次,所以存储下来没有意义。所以对于这种情况而言,使用布隆过滤器是个不错的选择;
- 而对与空数据的Key数量有限、Key重复请求效率较高的场景而言,可以选择缓存空数据的方案。
二、缓存击穿
缓存击穿是指当前热点数据存储到期时,多个线程同时并发访问热点数据。因为缓存刚过期,所有并发请求都会到数据库中查询数据。
1. 解决方案
- 将热点数据设置为永不过期;
- 加互斥锁:互斥锁可以控制查询数据库的线程访问,但这种方案会导致系统的吞吐量下降,需要根据实际情况使用。
Copypublic String get(key) {
String value = redis.get(key);
if (value == null) { // 代表缓存值过期
// 设置3min的超时,防止del操作失败的时候,下次缓存过期一直不能load db
if (redis.setnx(key_mutex, 1, 3 * 60) == 1) { // 代表设置成功
value = db.get(key);
redis.set(key, value, expire_secs);
redis.del(key_mutex);
} else { // 这个时候代表同时候的其他线程已经load db并回设到缓存了,这时候重试获取缓存值即可
sleep(50);
get(key); // 重试
}
} else {
return value;
}
}三、缓存雪崩
缓存雪崩发生有几种情况,比如大量缓存集中在或者缓存同时在大范围中失效,出现了大量请求去访问数据库,从而导致CPU和内存过载,甚至停机。
一个简单的雪崩过程:
- Redis 集群产生了大面积故障;
- 缓存失败,此时仍有大量请求去访问 Redis 缓存服务器;
- 在大量 Redis 请求失败后,这些请求将会去访问数据库;
- 由于应用的设计依赖于数据库和 Redis 服务,很快就会造成服务器集群的雪崩,最终导致整个系统的瘫痪。
解决方案
- 【事前】高可用缓存:高可用缓存是防止出现整个缓存故障。即使个别节点,机器甚至机房都关闭,系统仍然可以提供服务,Redis 哨兵(Sentinel) 和 Redis 集群(Cluster) 都可以做到高可用;
- 【事中】缓存降级(临时支持):当访问次数急剧增加导致服务出现问题时,我们如何确保服务仍然可用。在国内使用比较多的是 Hystrix,它通过熔断、降级、限流三个手段来降低雪崩发生后的损失。只要确保数据库不死,系统总可以响应请求,每年的春节 12306 我们不都是这么过来的吗?只要还可以响应起码还有抢到票的机会;
- 【事后】Redis备份和快速预热:Redis数据备份和恢复、快速缓存预热。
总结
关于Redis的面试题,文中提到的三个问题,基本是必考题,没看懂的多看几遍。
网站声明:如果转载,请联系本站管理员。否则一切后果自行承担。
- 上周热门
- 如何使用 StarRocks 管理和优化数据湖中的数据? 2951
- 【软件正版化】软件正版化工作要点 2872
- 统信UOS试玩黑神话:悟空 2833
- 信刻光盘安全隔离与信息交换系统 2728
- 镜舟科技与中启乘数科技达成战略合作,共筑数据服务新生态 1261
- grub引导程序无法找到指定设备和分区 1226
- 华为全联接大会2024丨软通动力分论坛精彩议程抢先看! 165
- 2024海洋能源产业融合发展论坛暨博览会同期活动-海洋能源与数字化智能化论坛成功举办 163
- 点击报名 | 京东2025校招进校行程预告 163
- 华为纯血鸿蒙正式版9月底见!但Mate 70的内情还得接着挖... 159
- 本周热议
- 我的信创开放社区兼职赚钱历程 40
- 今天你签到了吗? 27
- 如何玩转信创开放社区—从小白进阶到专家 15
- 信创开放社区邀请他人注册的具体步骤如下 15
- 方德桌面操作系统 14
- 用抖音玩法闯信创开放社区——用平台宣传企业产品服务 13
- 我有15积分有什么用? 13
- 如何让你先人一步获得悬赏问题信息?(创作者必看) 12
- 2024中国信创产业发展大会暨中国信息科技创新与应用博览会 9
- 中央国家机关政府采购中心:应当将CPU、操作系统符合安全可靠测评要求纳入采购需求 8
