Redis和Mysql如何保证数据一致?面试可以这样说自己的看法

Redis 和 MySQL 搭配使用在什么地方?
缓存量大但又不常变化的数据
也就是说,当我们在使用 Redis 和 MySQL 的时候,搭配使用的地方就是,数据量比较大,但是这个数据不会经常的变换的位置,比如说,某些商品信息的评论数据,也就是让 Redis 充当 MySQL 的缓存服务器,而要实现的目标也是比较简单的,当客户要查询数据的时候,先访问我们的 Redis ,当 Redis 里面没有数据的时候,从 MySQL 中读取数据,并且存储到 Redis 中。
这个时候 Redis 和 MySQL 的交互就是两部分:
第一部分:同步MySQL数据到Redis
第二部分:同步Redis到MySql
这两部分的内容,实际上就是在一组业务操作中完成的,商品评论信息写入 Redis,如果没有,从 MySQL 中读取,然后写入 Redis。
而接下来的问题就比较严重了,Redis 和 MySQL 数据库数据如何保持一致性?
Redis 和 MySQL 数据库数据如何保持一致性?
为什么会存在这样的一个问题呢?阿粉用网上拿过来的图给大家分析一波。
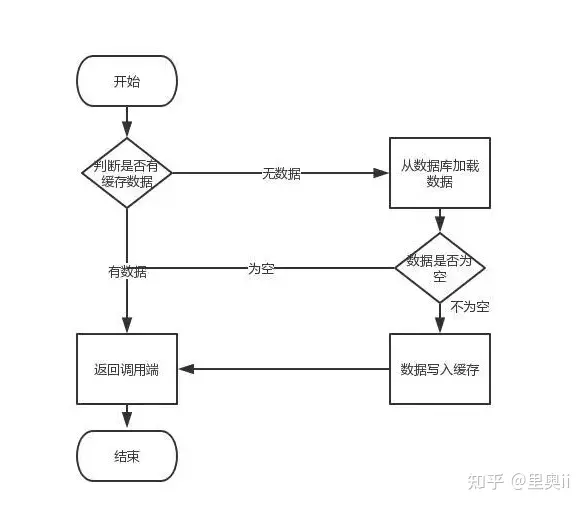
首先,当我们请求发送到服务器的时候,这个时候,我们先去缓存里面拿我们需要的数据,如果没有的话,我们就去数据库加载数据,加载完成之后,然后再把数据写入到缓存里面。
接下来问题来了,如果你的读和写存在并发的时候,会出现什么样子的问题呢?这个时候,我们就比较尴尬了,压根就没办法保证读和写的顺序,这时候就出现了 Redis 和 MySQL 数据不一致的问题了。
我们准备多种不同的方案来进行不同的分析。
1.先更新数据库,再更新缓存
为什么不考虑这种使用方案呢?
假设我们现在有两个请求 一个是 A 一个是 B ,假设 A 这时候进行请求,A 先更新数据库,接着 B 请求来了, B 更新数据库,结果 B 请求快,B 直接先更新了缓存,这时候缓存更新的内容为 B 更新的,也就是 b ,然后 A 这时候更新完数据库之后,又要更新缓存,这时候 A 更新了缓存,结果最后,缓存里面保存的数据是 a 。
也就是这样的
A ---> 更新数据库 ----> 更新缓存为a 我更新数据库慢,我存了个a
B ---> 更新数据库 ----> 更新缓存为b 我更新数据库快,我存了个b
本来应该最后更新完成之后的缓存中应该是 b ,结果最后出现了 a ,如果出现这种问题的时候,领导来看的时候,通常挨整的还是程序员自己呀。
这时候,在缓存里面存在的就应该算是脏数据了,所以,这种方案不推荐。

- 先更新缓存,再更新数据库
同样的 A B 两个请求,比如说这时候,A请求要进行一个写的操作,而 B 请求要进行一个读取的操作,这时候,A 肯定要删除缓存,就这这个时候,B 来了,我要读取,结果,缓存里面数据不存在,就直接去读数据库,然后把数据库的内容写入到缓存里面了,而这个时候的数据是 A 还没有进行过修改的数据,也就是一个老数据,等读完了之后,A进行了修改,这时候,你的缓存和你数据库中的数据就会出现不一样的情况了。
因为写和读是并发的,没法保证顺序,就会出现缓存和数据库的数据不一致的问题,这种方案,同样不可行。
那么我们应该怎么样去保证 Redis 和 MySQL 数据一致性呢?
如何保证 Redis 和 MySQL 数据一致性。
这时候就会有两个在面试的时候,说分布式很容易给自己挖了个大坑的地方,那就是最终一致性和强一致性,而数据库和缓存双写,就必然会存在不一致的问题。
这个命题就会有很感人的地方,你要做出一个选择,如果你选择强一致性,那就不能放缓存,所以,我们也就是仅仅能够保证最终的一致性,而如果选择强一致性,那算了,你别用缓存了。
而且我们说的这个,只是说降低概率发生,而不能完全的避免,但是我们还是要说。
延时双删策略
在写库前后都进行 Redis 的删除操作,并且第二次删除通过延迟的方式进行
那么应该是什么样子的实现逻辑呢?
- 第一步:先删除缓存
- 第二步:再写入数据库
- 第三步:休眠xxx毫秒(根据具体的业务时间来定)
- 第四步:再次删除缓存。
中间的休眠时间,根据自己的业务时间来进行定夺,这个双删策略实际上就是为了解决你在读数据的时候,生成的过期的数据被第二次写的操作给删除掉。
总有面试官喜欢问为什么要双删,因为第一次删除的是还没更新前的数据,第二次删除则是因为读取的并发性导致的缓存重新写入数据出现的垃圾数据。
这时候总有杠精面试官会问:如果你们的删缓存失败了,怎么办?那不是还是会出现缓存和数据库不一致的情况么?
比如一个写数据请求,然后写入数据库了,删缓存失败了,这会就出现不一致的情况了。
这时候我们就需要一个中间件的无私配合了,那就是使用消息来进行重试机制。
步骤:
- 业务代码去更新数据库
- 数据库的操作进行记录日志。
- 订阅程序提取出所需要的数据以及key
- 获得该信息尝试删除缓存,发现删除失败的时候,发送消息到消息队列
- 继续重试删除缓存的操作,直到删除缓存成功。
其实这个方法和另外一个地方很像,分布式事务的处理方式,就是保证数据的最终一致性,而在分布式事务中,则称之为这种为最大努力通知。
而为什么说是很像,实际上最大努力通知采用的实际上也是 MQ ,但是采用的是 MQ 的 ack 确认机制来进行完成的。
那么最大努力通知又是什么样的流程呢?
- 业务方把通知发送给 MQ
- 接收通知方监听 MQ
- 接收通知方接收消息,业务处理完成回应ack
- 接收通知方若没有回应ack则MQ会重复通知,MQ 按照间隔时间从短到长的方式逐步拉大通知间隔,直到达到通知要求的时间上限,比如24小时之后不再进行通知。
- 接收通知方可通过消息校对接口来校对消息的一致性
而为什么叫最大努力通知呢,实际上也很容易理解,他并没有从本质上解决问题,只是把问题数目从100 变成了 10 ,毕竟有些内容第一次没处理,第二次就可能会被处理掉。也就是说降低了这种有问题情况的发生,毕竟保证的都是最终一致性。
你面试的时候知道怎么和面试官 Battle 了么?
网站声明:如果转载,请联系本站管理员。否则一切后果自行承担。
- 上周热门
- 如何使用 StarRocks 管理和优化数据湖中的数据? 2996
- 【软件正版化】软件正版化工作要点 2916
- 统信UOS试玩黑神话:悟空 2893
- 信刻光盘安全隔离与信息交换系统 2774
- 镜舟科技与中启乘数科技达成战略合作,共筑数据服务新生态 1306
- grub引导程序无法找到指定设备和分区 1282
- 2024海洋能源产业融合发展论坛暨博览会同期活动-海洋能源与数字化智能化论坛成功举办 172
- 华为全联接大会2024丨软通动力分论坛精彩议程抢先看! 172
- 点击报名 | 京东2025校招进校行程预告 167
- 华为纯血鸿蒙正式版9月底见!但Mate 70的内情还得接着挖... 165
- 本周热议
- 我的信创开放社区兼职赚钱历程 40
- 今天你签到了吗? 27
- 信创开放社区邀请他人注册的具体步骤如下 15
- 如何玩转信创开放社区—从小白进阶到专家 15
- 方德桌面操作系统 14
- 用抖音玩法闯信创开放社区——用平台宣传企业产品服务 13
- 我有15积分有什么用? 13
- 如何让你先人一步获得悬赏问题信息?(创作者必看) 12
- 2024中国信创产业发展大会暨中国信息科技创新与应用博览会 9
- 信创再发力!中央国家机关台式计算机、便携式计算机批量集中采购配置标准的通知 8
