RabbitMQ和Kafka到底怎么选?

前言
开源社区有好多优秀的队列中间件,比如RabbitMQ和Kafka,每个队列都貌似有其特性,在进行工程选择时,往往眼花缭乱,不知所措。对于RabbitMQ和Kafka,到底应该选哪个?
RabbitMQ架构
RabbitMQ是一个分布式系统,这里面有几个抽象概念。
- broker:每个节点运行的服务程序,功能为维护该节点的队列的增删以及转发队列操作请求。
- master queue:每个队列都分为一个主队列和若干个镜像队列。
- mirror queue:镜像队列,作为master queue的备份。在master queue所在节点挂掉之后,系统把mirror queue提升为master queue,负责处理客户端队列操作请求。注意,mirror queue只做镜像,设计目的不是为了承担客户端读写压力。
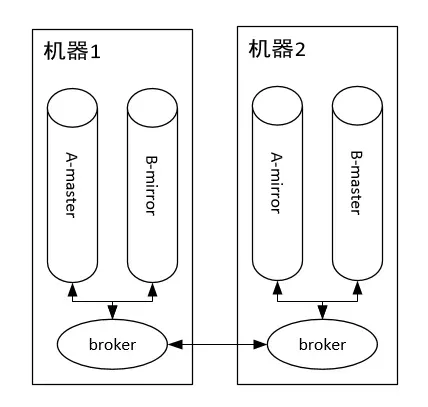
如上图所示,集群中有两个节点,每个节点上有一个broker,每个broker负责本机上队列的维护,并且borker之间可以互相通信。集群中有两个队列A和B,每个队列都分为master queue和mirror queue(备份)。那么队列上的生产消费怎么实现的呢?
队列消费
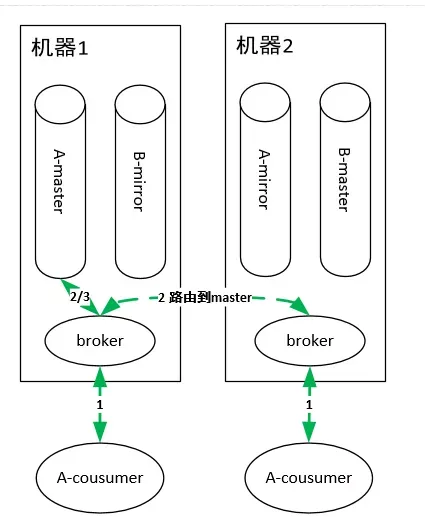
如上图有两个consumer消费队列A,这两个consumer连在了集群的不同机器上。RabbitMQ集群中的任何一个节点都拥有集群上所有队列的元信息,所以连接到集群中的任何一个节点都可以,主要区别在于有的consumer连在master queue所在节点,有的连在非master queue节点上。
因为mirror queue要和master queue保持一致,故需要同步机制,正因为一致性的限制,导致所有的读写操作都必须都操作在master queue上(想想,为啥读也要从master queue中读?和数据库读写分离是不一样的。),然后由master节点同步操作到mirror queue所在的节点。即使consumer连接到了非master queue节点,该consumer的操作也会被路由到master queue所在的节点上,这样才能进行消费。
队列生产
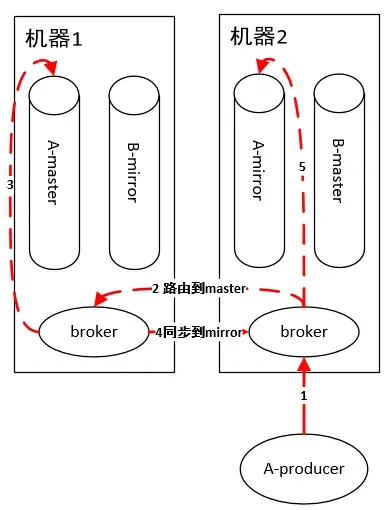
原理和消费一样,如果连接到非 master queue 节点,则路由过去。
所以,到这里小伙伴们就可以看到 RabbitMQ的不足:由于master queue单节点,导致性能瓶颈,吞吐量受限。虽然为了提高性能,内部使用了Erlang这个语言实现,但是终究摆脱不了架构设计上的致命缺陷。
Kafka
说实话,Kafka我觉得就是看到了RabbitMQ这个缺陷才设计出的一个改进版,改进的点就是:把一个队列的单一master变成多个master,即一台机器扛不住qps,那么我就用多台机器扛qps,把一个队列的流量均匀分散在多台机器上不就可以了么?注意,多个master之间的数据没有交集,即一条消息要么发送到这个master queue,要么发送到另外一个master queue。
这里面的每个master queue 在Kafka中叫做Partition,即一个分片。一个队列有多个主分片,每个主分片又有若干副分片做备份,同步机制类似于RabbitMQ。
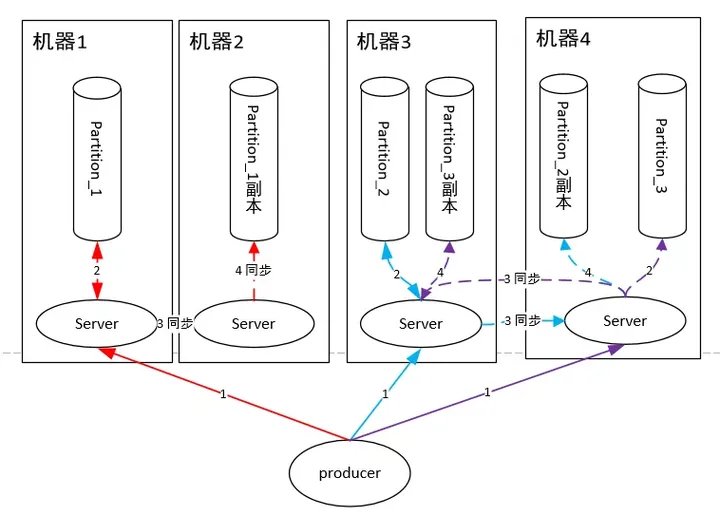
如上图,我们省略了不同的queue,假设集群上只有一个queue(Kafka中叫Topic)。每个生产者随机把消息发送到主分片上,之后主分片再同步给副分片。
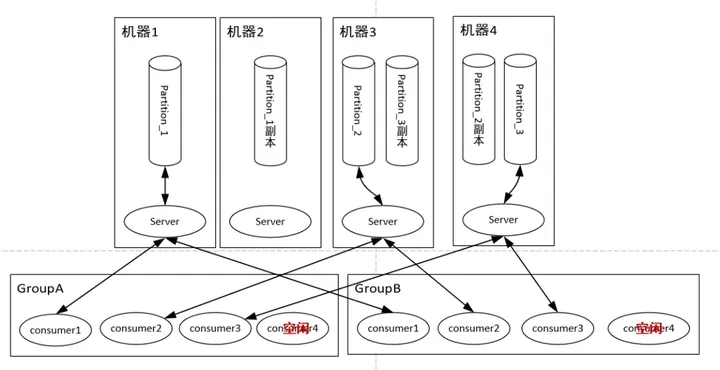
队列读取的时候虚拟出一个Group的概念,一个Topic内部的消息,只会路由到同Group内的一个consumer上,同一个Group中的consumer消费的消息是不一样的;Group之间共享一个Topic,看起来就是一个队列的多个拷贝。
所以,为了达到多个Group共享一个Topic数据,Kafka并不会像RabbitMQ那样消息消费完毕立马删除,而是必须在后台配置保存日期,即只保存最近一段时间的消息,超过这个时间的消息就会从磁盘删除,这样就保证了在一个时间段内,Topic数据对所有Group可见(这个特性使得Kafka非常适合做一个公司的数据总线)。
队列读同样是读主分片,并且为了优化性能,消费者与主分片有一一的对应关系,如果消费者数目大于分片数,则存在某些消费者得不到消息。
由此可见,Kafka绝对是为了高吞吐量设计的,比如设置分片数为100,那么就有100台机器去扛一个Topic的流量,当然比RabbitMQ的单机性能好。
总结
本文只做了Kafka和RabbitMQ的对比,但是开源队列岂止这两个,ZeroMQ,RocketMQ,JMQ等等,时间有限也就没有细看,故不在本文比较范围之内。
所以,别再被这些五花八门的队列迷惑了,从架构上找出关键差别,并结合自己的实际需求(比如本文就只单单从吞吐量一个需求来考察)轻轻松松搞定选型。最后总结如下:
- 吞吐量较低:Kafka和RabbitMQ都可以。
- 吞吐量高:Kafka。
本文内容参考自RabbitMQ和KafKa官方文档,所以真要搞懂一个中间件的原理最好去看官方文档,文档里面有详细的设计方案,我们可以自己进行设计方案的对比,从而找出符合自己实际情况的中间件。
网站声明:如果转载,请联系本站管理员。否则一切后果自行承担。
- 上周热门
- 如何使用 StarRocks 管理和优化数据湖中的数据? 2959
- 【软件正版化】软件正版化工作要点 2878
- 统信UOS试玩黑神话:悟空 2843
- 信刻光盘安全隔离与信息交换系统 2737
- 镜舟科技与中启乘数科技达成战略合作,共筑数据服务新生态 1270
- grub引导程序无法找到指定设备和分区 1235
- 华为全联接大会2024丨软通动力分论坛精彩议程抢先看! 165
- 点击报名 | 京东2025校招进校行程预告 164
- 2024海洋能源产业融合发展论坛暨博览会同期活动-海洋能源与数字化智能化论坛成功举办 163
- 华为纯血鸿蒙正式版9月底见!但Mate 70的内情还得接着挖... 159
- 本周热议
- 我的信创开放社区兼职赚钱历程 40
- 今天你签到了吗? 27
- 信创开放社区邀请他人注册的具体步骤如下 15
- 如何玩转信创开放社区—从小白进阶到专家 15
- 方德桌面操作系统 14
- 我有15积分有什么用? 13
- 用抖音玩法闯信创开放社区——用平台宣传企业产品服务 13
- 如何让你先人一步获得悬赏问题信息?(创作者必看) 12
- 2024中国信创产业发展大会暨中国信息科技创新与应用博览会 9
- 中央国家机关政府采购中心:应当将CPU、操作系统符合安全可靠测评要求纳入采购需求 8
