零散的MySQL基础总是记不住?看这一篇就够了!

前言
在日常开发中,一些不常用且又比较基础的知识,过了一段时间之后,总是容易忘记或者变得有点模棱两可。本篇主要记录一些关于MySQL数据库比较基础的知识,以便日后快速查看。
SQL命令
SQL命令分可以分为四组:DDL、DML、DCL和TCL。四组中包含的命令分别如下
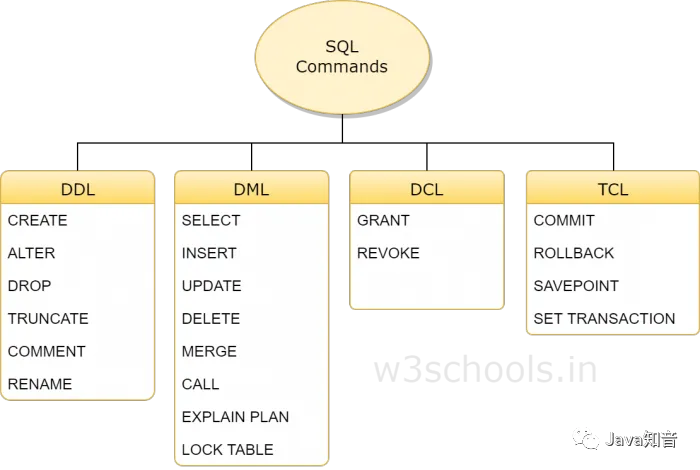
(图片来源见水印)
DDL
DDL是数据定义语言(Data Definition Language)的简称,它处理数据库schemas和描述数据应如何驻留在数据库中。
CREATE:创建数据库及其对象(如表,索引,视图,存储过程,函数和触发器)ALTER:改变现有数据库的结构DROP:从数据库中删除对象TRUNCATE:从表中删除所有记录,包括为记录分配的所有空间都将被删除COMMENT:添加注释RENAME:重命名对象
常用命令如下:
# 建表
CREATE TABLE sicimike (
id int(4) primary key auto_increment COMMENT '主键ID',
name varchar(10) unique,
age int(3) default 0,
identity_card varchar(18)
# PRIMARY KEY (id) // 也可以通过这种方式设置主键
# UNIQUE KEY (name) // 也可以通过这种方式设置唯一键
# key/index (identity_card, col1...) // 也可以通过这种方式创建索引
) ENGINE = InnoDB;
# 设置主键
alter table sicimike add primary key(id);
# 删除主键
alter table sicimike drop primary key;
# 设置唯一键
alter table sicimike add unique key(column_name);
# 删除唯一键
alter table sicimike drop index column_name;
# 创建索引
alter table sicimike add [unique/fulltext/spatial] index/key index_name (identity_card[(len)] [asc/desc])[using btree/hash]
create [unique/fulltext/spatial] index index_name on sicimike(identity_card[(len)] [asc/desc])[using btree/hash]
example: alter table sicimike add index idx_na(name, age);
# 删除索引
alter table sicimike drop key/index identity_card;
drop index index_name on sicimike;
# 查看索引
show index from sicimike;
# 查看列
desc sicimike;
# 新增列
alter table sicimike add column column_name varchar(30);
# 删除列
alter table sicimike drop column column_name;
# 修改列名
alter table sicimike change column_name new_name varchar(30);
# 修改列属性
alter table sicimike modify column_name varchar(22);
# 查看建表信息
show create table sicimike;
# 添加表注释
alter table sicimike comment '表注释';
# 添加字段注释
alter table sicimike modify column column_name varchar(10) comment '姓名';
DML
DML是数据操纵语言(Data Manipulation Language)的简称,包括最常见的SQL语句,例如SELECT,INSERT,UPDATE,DELETE等,它用于存储,修改,检索和删除数据库中的数据。
分页
-- 查询从第11条数据开始的连续5条数据
select * from sicimike limit 10, 5
group by
默认情况下,MySQL中的分组(group by)语句,不要求select返回的列,必须是分组的列或者是一个聚合函数。
如果select查询的列不是分组的列,也不是聚合函数,则会返回该分组中第一条记录的数据。对比下面两条SQL语句,第二条SQL语句中,cname既不是分组的列,也不是以聚合函数的形式出现。所以在liming这个分组中,cname取的是第一条数据。
mysql> select * from c;
+-----+-------+----------+
| CNO | CNAME | CTEACHER |
+-----+-------+----------+
| 1 | 数学 | liming |
| 2 | 语文 | liming |
| 3 | 历史 | xueyou |
| 4 | 物理 | guorong |
| 5 | 化学 | liming |
+-----+-------+----------+
5 rows in set (0.00 sec)
mysql> select cteacher, count(cteacher), cname from c group by cteacher;
+----------+-----------------+-------+
| cteacher | count(cteacher) | cname |
+----------+-----------------+-------+
| guorong | 1 | 物理 |
| liming | 3 | 数学 |
| xueyou | 1 | 历史 |
+----------+-----------------+-------+
3 rows in set (0.00 sec)
having
having关键字用于对分组后的数据进行筛选,功能相当于分组之前的where,不过要求更严格。过滤条件要么是一个聚合函数( ... having count(x) > 1),要么是出现在select后面的列(select col1, col2 ... group by x having col1 > 1)
多表更新
update tableA a inner join tableB b on a.xxx = b.xxx set a.col1 = xxx, b.col1 = xxx where ...
多表删除
delete a, b from tableA a inner join tableB b on a.xxx = b.xxx where a.col1 = xxx and b.col1 = xxx
DCL
DCL是数据控制语言(Data Control Language)的简称,它包含诸如GRANT之类的命令,并且主要涉及数据库系统的权限,权限和其他控件。
GRANT:允许用户访问数据库的权限REVOKE:撤消用户使用GRANT命令赋予的访问权限
TCL
TCL是事务控制语言(Transaction Control Language)的简称,用于处理数据库中的事务
COMMIT:提交事务ROLLBACK:在发生任何错误的情况下回滚事务
范式
数据库规范化,又称正规化、标准化,是数据库设计的一系列原理和技术,以减少数据库中数据冗余,增进数据的一致性。关系模型的发明者埃德加·科德最早提出这一概念,并于1970年代初定义了第一范式、第二范式和第三范式的概念,还与Raymond F. Boyce于1974年共同定义了第三范式的改进范式——BC范式。
除外还包括针对多值依赖的第四范式,连接依赖的第五范式、DK范式和第六范式。
现在数据库设计最多满足3NF,普遍认为范式过高,虽然具有对数据关系更好的约束性,但也导致数据关系表增加而令数据库IO更易繁忙,原来交由数据库处理的关系约束现更多在数据库使用程序中完成。
第一范式
定义:数据库中的所有字段(列)都是单一属性,不可再分的。这个单一属性由基本的数据类型所构成,如整型、浮点型、字符串等。
第一范式是为了保证列的原子性。

上表不满足第一范式,其中的地址列是可以再拆分的,可以拆分成省、市、区等

第二范式
定义:数据库中的表不存在非关键字段对任一关键字字段的部分函数依赖
部分函数依赖是指存在着组合关键字中的某一关键字决定非关键字的情况
第二范式在满足了第一范式的基础上,消除非主键列对联合主键的部分依赖

上面这张表中想要设置主键,只能是商品名称和供应商名称一起组成联合主键。但是价格和分类只依赖于商品名称,供应商电话只依赖于供应商名称,所以上面的表不满足第二范式,可以改成如下形式:
商品信息表

供应商信息表

商品-供应商关联表

第三范式
定义:所有非主键属性都只和候选键有相关性,也就是说非主键属性之间应该是独立无关的。
第三范式是在满足了第二范式的基础上,消除列与列之间的传递依赖。

在上面的表中,商品的分类描述依赖分类,而分类依赖商品名称,而不是分类描述直接依赖商品名称。这样就形成了传递依赖,所以不符合第三范式。可以改成如下形式
商品表

商品分类表

数据库设计时,遵循范式和反范式一直以来是一个颇受争议的问题。遵循范式对数据关系更好的约束性,并且减少数据冗余,可以更好地保证数据一致性。而反范式则是为了获得更好地性能。所以范式还是反范式并没有明确的标准,适合自己业务场景的才是最好的。
反范式设计时,需要考虑以下几个问题,分别是插入异常、更新异常和删除异常。
- 插入异常:如果某个实体随着另一个实体的存在而存在,即缺少某个实体是无法表示这个实体,那么这个表就存在插入异常。
- 更新异常:如果更改表所对应的某个实体实例的单独属性时,需要将多行更新,那么就说明这个表存在更新异常
- 删除异常:如果删除表的某一行来表示某实体实例失效时,导致另一个不同实体实例信息丢失,那么这个表就存在删除异常
以违反第二范式的表为例

如果可乐第二制造厂这个供应商尚未开始供货,表中就不存在第二条记录,也就无法记录供应商的电话,这样就存在插入异常;如果需要把可乐的价格提高,需要更新表中的多条记录,这样就存在更新异常;如果删除可乐第二制造厂的供货信息,那么该供应商的电话也就丢失了,这样就存在删除异常。
一般存在插入异常的表,都会存在更新异常和删除异常。
横表纵表
SQL脚本
# 横表
CREATE TABLE `table_h2z` (
`name` varchar(32) DEFAULT NULL,
`chinese` int(11) DEFAULT NULL,
`math` int(11) DEFAULT NULL,
`english` int(11) DEFAULT NULL
) ENGINE=InnoDB AUTO_INCREMENT=4 DEFAULT CHARSET=utf8;
/*Data for the table `table_h2z` */
insert into `table_h2z`(`name`,`chinese`,`math`,`english`) values
('mike',45,43,87),
('lily',53,64,88),
('lucy',57,75,75);
# 纵表
CREATE TABLE `table_z2h` (
`name` varchar(32) DEFAULT NULL,
`subject` varchar(8) NOT NULL DEFAULT '',
`score` int(11) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
/*Data for the table `table_z2h` */
insert into `table_z2h`(`name`,`subject`,`score`) values
('mike','chinese',45),
('lily','chinese',53),
('lucy','chinese',57),
('mike','math',43),
('lily','math',64),
('lucy','math',75),
('mike','english',87),
('lily','english',88),
('lucy','english',75);
横表转纵表
SELECT NAME, 'chinese' AS `subject`, chinese AS `score` FROM table_h2z
UNION ALL
SELECT NAME, 'math' AS `subject`, math AS `score` FROM table_h2z
UNION ALL
SELECT NAME, 'english' AS `subject`, english AS `score` FROM table_h2z
执行结果
+------+---------+-------+
| name | subject | score |
+------+---------+-------+
| mike | chinese | 45 |
| lily | chinese | 53 |
| lucy | chinese | 57 |
| mike | math | 43 |
| lily | math | 64 |
| lucy | math | 75 |
| mike | english | 87 |
| lily | english | 88 |
| lucy | english | 75 |
+------+---------+-------+
9 rows in set (0.00 sec)
纵表转横表
SELECT NAME,
SUM(CASE `subject` WHEN 'chinese' THEN score ELSE 0 END) AS chinese,
SUM(CASE `subject` WHEN 'math' THEN score ELSE 0 END) AS math,
SUM(CASE `subject` WHEN 'english' THEN score ELSE 0 END) AS english
FROM table_z2h
GROUP BY NAME
执行结果
+------+---------+------+---------+
| name | chinese | math | english |
+------+---------+------+---------+
| lily | 53 | 64 | 88 |
| lucy | 57 | 75 | 75 |
| mike | 45 | 43 | 87 |
+------+---------+------+---------+
3 rows in set (0.00 sec)网站声明:如果转载,请联系本站管理员。否则一切后果自行承担。
- 上周热门
- 银河麒麟添加网络打印机时,出现“client-error-not-possible”错误提示 1448
- 银河麒麟打印带有图像的文档时出错 1365
- 银河麒麟添加打印机时,出现“server-error-internal-error” 1151
- 统信桌面专业版【如何查询系统安装时间】 1073
- 统信操作系统各版本介绍 1070
- 统信桌面专业版【全盘安装UOS系统】介绍 1028
- 麒麟系统也能完整体验微信啦! 984
- 统信【启动盘制作工具】使用介绍 627
- 统信桌面专业版【一个U盘做多个系统启动盘】的方法 575
- 信刻全自动档案蓝光光盘检测一体机 484
- 本周热议
- 我的信创开放社区兼职赚钱历程 40
- 今天你签到了吗? 27
- 信创开放社区邀请他人注册的具体步骤如下 15
- 如何玩转信创开放社区—从小白进阶到专家 15
- 方德桌面操作系统 14
- 我有15积分有什么用? 13
- 用抖音玩法闯信创开放社区——用平台宣传企业产品服务 13
- 如何让你先人一步获得悬赏问题信息?(创作者必看) 12
- 2024中国信创产业发展大会暨中国信息科技创新与应用博览会 9
- 中央国家机关政府采购中心:应当将CPU、操作系统符合安全可靠测评要求纳入采购需求 8
