理解Java对象:要从内存布局及底层机制说起,话说….

前言
大家好,又见面了,今天是JVM专题的第二篇文章,在上一篇文章中我们说了Java的类和对象在JVM中的存储方式,并使用HSDB进行佐证,没有看过上一篇文章的小伙伴可以点这里:《类和对象在JVM中是如何存储的,竟然有一半人回答不上来!》
这篇文章主要会对Java对象进行详细分析,基于上一篇文章,对Java对象的布局及其底层的一些机制进行解读,相信这些会对后期JVM调优有很大的帮助。
对象的内存布局
在上篇文章中我们提到,对象在JVM中是由一个Oop进行描述的。回顾一下,Oop由对象头(_mark、_metadata)以及实例数据区组成,而对象头中存在一个_metadata,其内部存在一个指针,指向类的元数据信息,就是下面这张图:

而今天要说的对象的内存布局,其底层实际上就是来自于这张图。
了解过对象组成的同学应该明白,对象由三部分构成,分别是:对象头、实例数据、对齐填充组成,而对象头和示例数据,对应的就是Oop对象中的两大部分,而对齐填充实际上是一个只在逻辑中存在的部分。
对象头
我们可以对这三个部分分别进行更深入的了解,首先是对象头:
对象头分为MarkWord和类型指针,MarkWord就是Oop对象中的_mark,其内部用于存储对象自身运行时的数据,例如:HashCode、GC分代年龄、锁状态标志、持有锁的线程、偏向线程Id、偏向时间戳等。
这是笔者在网上找的关于对象头的内存布局(64位操作系统,无指针压缩):
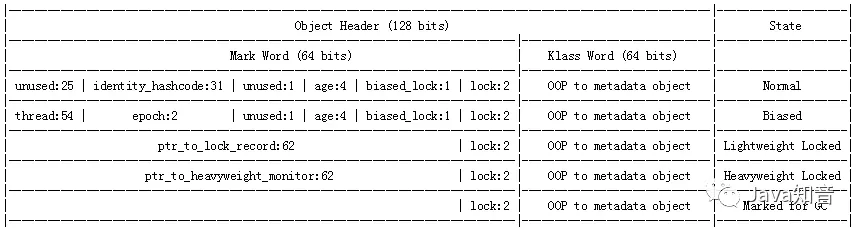
对象头占用128位,也就是16字节,其中MarkWord占8字节,Klass Point(类型指针)占8字节,MarkWord中所存储的信息,是这个对象最基本的一些信息,例如GC分代年龄,可以让JVM判断当前对象是否应该进入老年代,锁状态标志,在处理并发的过程中,可以判断当前要以什么级别的手段来保证线程安全,从而优化同步操作的性能,其他的相信大家都比较了解,这里就暂时先不一一列举了。当然,对象头在之后的并发专题依旧会有所提及。
而对象头的另外8字节,是KlassPoint,类型指针,在上一篇文章的Oop模型中,提到类型指针指向Klass对象,用于在运行时获取对象所属的类的元信息。
实例数据
何为实例数据,顾名思义,就是对象中的字段,用更严谨一点的话来说,类的非静态属性,在生成对象后,就是实例数据,而实例数据这部分的大小,就是实实在在的多个属性所占的空间的和,例如有下面这样一个类:
public class Test{
private int a;
private double b;
private boolean c;
}
那么在new Test()操作之后,这个对象的实例数据区所占的空间就是4+8+1 = 13字节,以此类推。
而在Java中,基本数据类型都有其大小:
boolean --- 1B
byte --- 1B
short --- 2B
char --- 2B
int --- 4B
float --- 4B
double --- 8B
long --- 8B
除了上述的八个基本数据类型以外,类中还可以包含引用类型对象,那么这部分如何计算呢?
这里需要分情况讨论,由于还没有说到指针压缩,那么大家就先记下好了:
如果是32位机器,那么引用类型占4字节。
如果是64位机器,那么引用类型占8字节。
如果是64位机器,且开启了指针压缩,那么引用类型占4字节。
如果对象的实例数据区,存在别的引用类型对象,实际上只是保存了这个对象的地址,理解了这个概念,就可以对这三种情况进行理解性记忆了。
为什么32位机器的引用类型占4个字节,而64位机器引用类型占8字节?
这里就要提到一个寻址的概念,既然保存了内存地址,那就是为了日后方便寻址,而32位机器的含义就是,其地址是由32个Bit位组成的,所以要记录其内存地址,需要使用4字节,64位同理,需要8字节。
对齐填充
我们提到对象是由三部分构成,但是上文只涉及了两部分,还有一部分就是对齐填充,这个是比较特殊的一个部分,只存在于逻辑中,这里需要科普一下,JVM中的对象都有一个特性,那就是8字节对齐,什么叫8字节对齐呢,就是一个对象的大小,只能是8的整数倍,如果一个对象不满8的整数倍,则会对其进行填充。
看到这里可能有同学就会心存疑惑,那假设一个对象的内容只占20字节,那么根据8字节对齐特性,这个对象不就会变成24字节吗?那岂不是浪费空间了?根据8字节对其的逻辑,这个问题的答案是肯定的,假设一个对象只有20字节,那么就会填充变成24字节,而多出的这四个字节,就是我们所说的对齐填充,笔者在这里画一张图来描述一下:
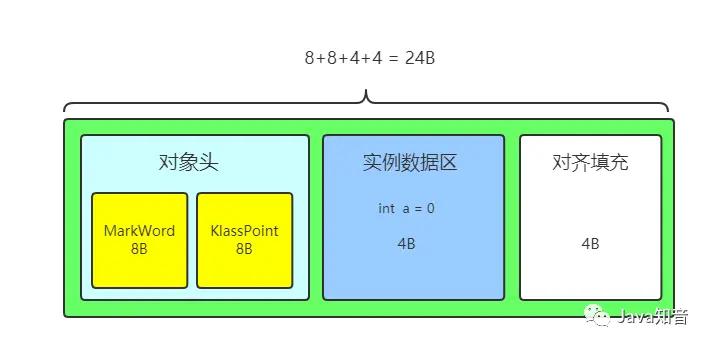
对象头在不考虑指针压缩的情况下,占用16个字节,实例数据区,我们假设是一个int类型的数据,占用4个字节,那么这里一共是20字节,那么由于8字节对齐特性,对象就会填充到24字节。
那么为什么要这么去设计呢?,刚开始笔者也有这样的疑惑,这样设计会有很多白白浪费掉的空间,毕竟填充进来的数据,在逻辑上是没有任何意义的,但是如果站在一个设计者的角度上看,这样的设计在日后的维护中是最为方便的。假设对象没有8字节对齐,而是随机大小分布在内存中,由于这种不规律,会造成设计者的代码逻辑变得异常复杂,因为设计者根本不知道你这个对象到底有多大,从而没有办法完整地取出一整个对象,还有可能在这种不确定中,取到其它对象的数据,造成系统混乱。
当然,有些同学觉得设计上的问题总能克服,这点原因还不足以让我们浪费内存,这就是我理解的第二点原因,这么设计还会有一种好处,就是提升性能,假设对象是不等长的,那么为了获取一个完整的对象,就必须一个字节一个字节地去读,直到读到结束符,但是如果8字节对齐后,获取对象就可以以8个字节为单位进行读取,快速获取到一个对象,也不失为一种以空间换时间的设计方案。
那么又有同学要问了,那既然8字节可以提升性能,那为什么不16字节对齐呢,这样岂不是性能更高吗?答案是:没有必要,有两个原因,第一,我们对象头最大是16字节,而实例数据区最大的数据类型是8个字节,所以如果选择16字节对齐,假设有一个18字节的对象,那么我们需要将其填充成为一个32字节的对象,而选择8字节填充则只需要填充到24字节即可,这样不会造成更大的空间浪费。第二个原因,允许我在这里卖一下关子,在之后的指针压缩中,我们再详细进行说明。
关于对象内存布局的证明方式
证明方式有两种,一种是使用代码的方式,还有一种就是使用上一篇文章中我们提到的,使用HSDB,可以直接了当地查看对象的组成,由于HSDB在上一篇文章中已经说过了,所以这里只说第一种方式。
首先,我们需要引入一个maven依赖:
<!-- https://mvnrepository.com/artifact/org.openjdk.jol/jol-core -->
<dependency>
<groupId>org.openjdk.jol</groupId>
<artifactId>jol-core</artifactId>
<version>0.10</version>
</dependency>
引入这个依赖之后,我们就可以在控制台中查看对象的内存布局了,代码如下:
public class Blog {
public static void main(String[] args) {
Blog blog = new Blog();
System.out.println(ClassLayout.parseInstance(blog).toPrintable());
}
}
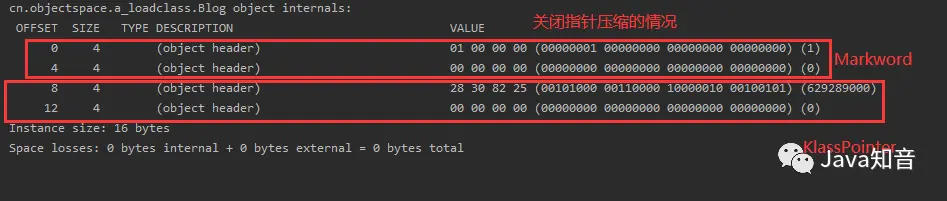
首先是关闭指针压缩的情况,对齐填充为0字节,对象大小为16字节:
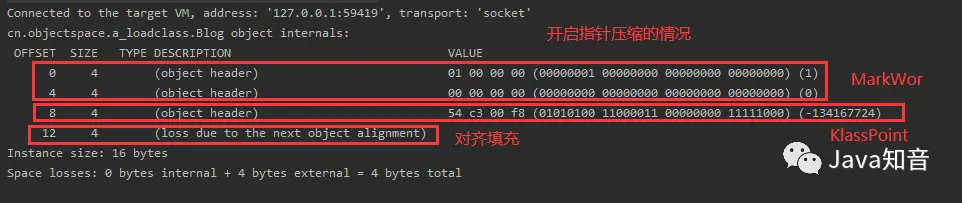
然后是开启指针压缩的情况,对齐填充为4字节,对象大小依旧为16字节:
解释一下为什么两种情况都是16字节:
开启指针压缩,对象大小(16字节) = MarkWord(8字节)+ KlassPointer(4字节)+ 数组长度(0字节) + 实例数据(0字节)+ 对齐填充(4字节) 关闭指针压缩,对象大小(16字节)= MarkWord(8字节)+ KlassPointer(8字节)+ 数组长度(0字节)+ 实例数据(0字节) + 对齐填充(0字节)
如何计算对象的内存占用
在第一节中我们已经详细阐述了对象在内存中的布局,主要分为三部分,对象头、实例数据、对齐填充,并且进行了证明。这一节中来带大家计算对象的内存占用。
实际上在刚才对内存布局的阐述中,应该有很多同学都对如何计算对象内存占用有了初步的了解,其实这也并不难,无非就是把三个区域的占用求和,但是上文中我们只是说了几种简单的情况,所以这里主要来说说我们上文中没有考虑到的,我们将分情况进行讨论并证明。
对象中只存在基本数据类型
public class Blog {
private int a = 10;
private long b = 20;
private double c = 0.0;
private float d = 0.0f;
public static void main(String[] args) {
Blog blog = new Blog();
System.out.println(ClassLayout.parseInstance(blog).toPrintable());
}
}
这种情况是除了空对象以外的最简单的一种情况,假设对象中存在的属性全都是Java八种基本类型中的某一种或某几种类型,对象的大小如何计算?
不妨先来看看结果:
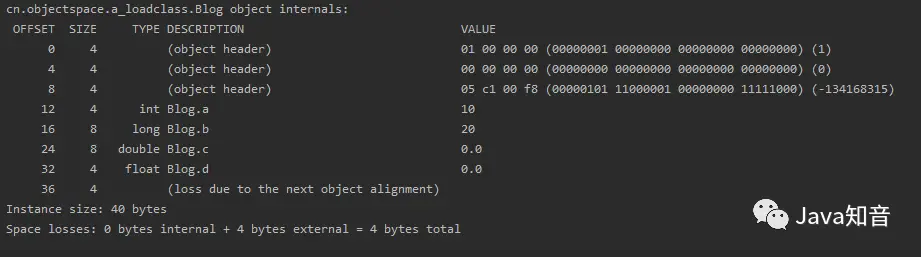
对于这种情况,我们只需要简单地将对象头+示例数据+对齐填充即可,由于我们在对象中存在四个属性,分别为int(4字节)+long(8字节)+double(8字节)+float(4字节),可以得出实例数据为24字节,而对象头为12字节(指针压缩开启),那么一共就是36字节,但是由于Java中的对象必须得是8字节对齐,所以对齐填充会为其补上4字节,所以整个对象就是:
对象头(12字节)+实例数据(24字节)+对齐填充(4字节) = 40字节
对象中存在引用类型(关闭指针压缩)
那么对象中存在引用类型,该如何计算?这里涉及到开启指针压缩和关闭指针压缩两种情况,我们先来看看关闭指针压缩的情况,究竟有何不同。
public class Blog {
Map<String,Object> objMap = new HashMap<>(16);
public static void main(String[] args) {
Blog blog = new Blog();
System.out.println(ClassLayout.parseInstance(blog).toPrintable());
}
}
同样,先看结果:
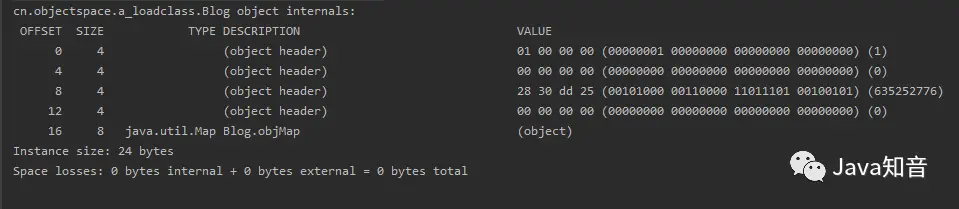
可以看到,对象的实例数据区存在一个引用类型属性,就像第一节中说的,只是保存了指向这个属性的指针,这个指针在关闭指针压缩的情况下,占用8字节,不妨也计算一下它的大小:
对象头(关闭指针压缩,占用16字节)+实例数据(1个对象指针8字节)+ 对齐填充(无需进行填充)=24字节
对象中存在引用类型(开启指针压缩)
那么如果是开启指针压缩的情况呢?

如果是开启指针压缩的情况,类型指针和实例数据区的指针都仅占用4字节,所以其内存大小为:
MarkWord(8B)+KlassPointer(4B)+实例数据区(4B)+对齐填充(0B) = 16B
数组类型(关闭指针压缩)
如果是数组类型的对象呢?由于在上文中已经形成的定向思维,大家可能已经开始使用原先的套路开始计算数组对象的大小了,但是这里的情况就相对比普通对象要复杂很多,出现的一些现象可能要让大家大跌眼镜了。
我们这里枚举三种情况:
public class Blog {
private int a = 10;
private int b = 10;
public static void main(String[] args) {
//对象中无属性的数组
Object[] objArray = new Object[3];
//对象中存在两个int型属性的数组
Blog[] blogArray = new Blog[3];
//基本类型数组
int[] intArray = new int[1];
System.out.println(ClassLayout.parseInstance(blogArray).toPrintable());
System.out.println(ClassLayout.parseInstance(objArray).toPrintable());
System.out.println(ClassLayout.parseInstance(intArray).toPrintable());
}
}
依旧是先看结果:
首先是第一种情况:对象中无属性的数组:
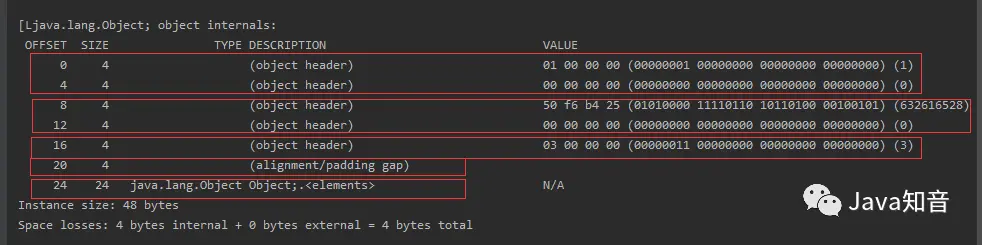
同样的一个打印对象操作,除了MarkWord、KlassPointer、实例数据对齐填充以外,多了一篇空间,我们可以发现,原先在普通对象的算法,已经不适用于数组的算法了,因为在数组中出现了一个很诡异而我们从没有提到过的东西,那就是对象头的第三部分——数组长度。
数组长度究竟为何物?
如果对象是一个数组,它的内部除了我们刚才说的那些以外,还会存在一个数组长度属性,用于记录这个数组的大小,数组长度为32个Bit,也就是4个字节,这里也可以关联上一个基础知识,就是Java中数组最大可以设置为多大?跟计算内存地址的表示方式类似,由于其占4个字节,所以数组的长度最大为2^32。
我们再来看看实例数据区的情况,由于其存放了三个对象,而我们在对象中存在引用类型这个情况中阐述过,即使存在对象,我们也只是保存了指向其内存地址的指针,这里由于关闭了指针压缩,所以每个指针占用8个字节,一共24字节。
再回到图上,在前几个案例中,对齐填充都在实例数据区之后,但是这里对齐填充是处于对象头的第四部分。在实例数据区之前,也就是在数组对象中,出现了第二段的对齐填充,那么数组对象的内存布局就应该变成下图这样:

我们可以在另外两种情况中验证这个想法:
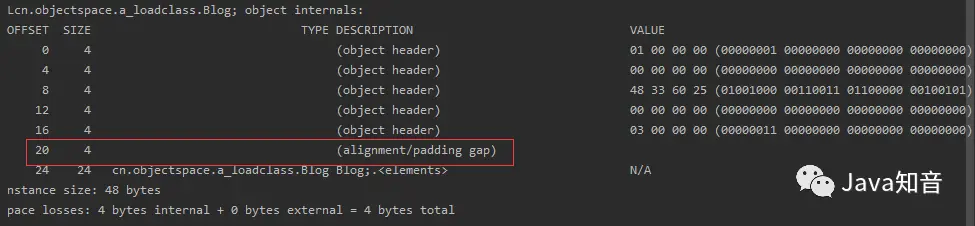
对象中存在两个int型属性的数组:
基本数据类型数组:
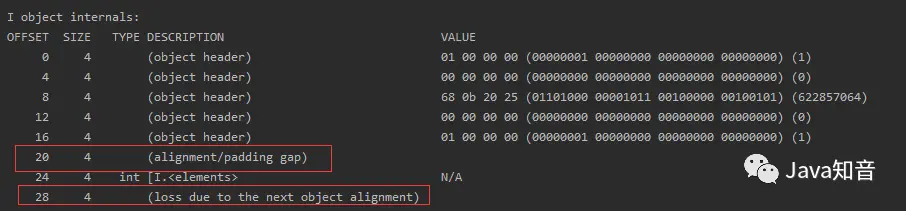
我们可以看到,即使对象中存在两个int类型的数组,依旧保存其内存地址指针,所以依旧是4字节,而在基本类型的数组中,其保存的是实例数据的大小,也就是int类型的长度4字节,如果数组长度是3,这里的实例数据就是12字节,以此类推,而这种情况下,同样出现了两段填充的现象,由于我们代码中的数组长度设置为1,所以这里的对象大小为:
MarkWord(8B)+KlassPointer(8B)+数组长度(4B)+第一段对齐填充(4B)+实例数据区(4B)+第二段对齐填充(4B) = 32B
数组类型(开启指针压缩)
那么如果开启指针压缩又会是什么样的状况呢?有了上面的基础,大家可以先考虑一下,我这里就直接上图了。
长度为1的基本类型数组:
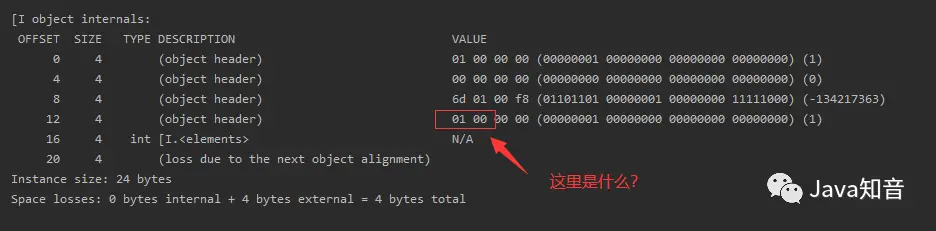
在对象中存在引用类型(开启指针压缩)中我说过只要开启了指针压缩,我们的类型指针就是占用4个字节,由于是数组,对象头中依旧多了一个存放对象的指针,但是对象头中的对齐填充消失了,所以其大小为:
MarkWord(8B)+KlassPointer(4B)+数组长度(4B)+实例数据区(4B)+对齐填充(4B) = 24B
仅存在静态变量
最后一种情况,假设类中仅存在一个静态变量(开启指针压缩):
public class Blog {
private static Map<String,Object> mapObj = new HashMap<>(16);
public static void main(String[] args) {
Blog blog = new Blog();
int[] intArray = new int[1];
System.out.println(ClassLayout.parseInstance(blog).toPrintable());
}
}

可以看到其内部并没有实例数据区,原因很简单,我们也说过,大家要记住,只有类的非静态属性,在生成对象后,才是实例数据,而静态变量不在其列。
总结
关于如何对象的大小,其实很简单,我们首先关注是否是开启了指针压缩,然后关注其是普通对象还是数组对象,这里做个总结。
如果是普通对象,那么只需要计算:MarkWord+KlassPointer(8B)+实例数据+对齐填充。
如果是数组对象,则需要分两种情况,如果是开启指针压缩的情况,那么分为五段:MarkWord+KlassPointer(4B)+第一段对齐填充+实例数据+第二段对齐填充。
如果对象中存在引用类型数据,则保存的只是指向这个数据的指针,在开启指针压缩的情况下,为4字节,关闭指针压缩为8字节。
如果对象中存在基本数据类型,那么保存的就是其实体,这就需要按照8中基本数据类型的大小来灵活计算了。
指针压缩
在本篇文章中我们和指针压缩打过多次交道,那么究竟是什么指针压缩?
简单来说,指针压缩就是一种节约内存的技术,并且可以增强内存寻址的效率,由于在64位系统中,对象中的指针占用8字节,也就是64Bit,我们再来回顾一下,8字节指针可以表示的内存大小是多少?
2^64 = 18446744073709552000Bit = 2147483648GB
很显然,站在内存的角度,首先,在当前的硬件条件下,我们几乎不可能达到这种内存级别。其次,64位对象引用需要占用更多的对空间,留给其他数据的空间将会减少,从而加快GC的发生。站在CPU的角度,对象引用变大了,CPU能缓存的对象也就少了,每次使用时都需要去内存中取,降低了CPU的效率。所以,在设计时,就引入了指针压缩的概念。
指针压缩原理
我们都知道,指针压缩会将原先的8字节指针,压缩到4字节,那么4字节能表示的内存大小是多少?
2^32 = 4GB
这个内存级别,在当前64位机器的大环境下,在大多数的生产环境下已经是不够用了,需要更大的寻址范围,但是刚才我们看到,指针压缩之后,对象指针的大小就是4个字节,那么我们需要了解的就是,JVM是如何在指针压缩的条件下,提升寻址范围的呢?
需要注意的一点是:由于32位操作系统,能够识别的最大内存地址就是4GB,所以指针压缩后也依旧够用,所以32位操作系统不在这个讨论范畴内,这里只针对64位操作系统进行讨论。
首先我们来看看,指针压缩之后,对象的内存地址存在何种规律:
假设这里有三个对象,分别是对象A 8字节,对象B 16字节,对象C 24字节。
那么其内存地址(假设从00000000)开始,就是:
A:00000000 00000000 00000000 00000000 0x00000000
B:00000000 00000000 00000000 00001000 0x00000008
C:00000000 00000000 00000000 00010000 0x00000010
由于Java中对象存在8字节对齐的特性,所以所有对象的内存地址,后三位永远是0。那么这里就是JVM在设计上解决这个问题的精妙之处。
首先,在存储的时候,JVM会将对象内存地址的后三位的0抹去(右移3位),在使用的时候,将对象的内存地址后三位补0(左移3位),这样做有什么好处呢。
按照这种逻辑,在存储的时候,假设有一个对象,所在的内存地址已经达到了8GB,超出了4GB,那么其内存地址就是:**00000010 00000000 00000000 00000000 00000000 **
很显然,这已经超出了32位(4字节)能表示的最大范围,那么依照上文中的逻辑,在存储的时候,JVM将对象地址右移三位,变成01000000 00000000 00000000 00000000,而在使用的时候,在后三位补0(左移3位),这样就又回到了最开始的样子:**00000010 00000000 00000000 00000000 00000000 **,就又可以在内存中找到对象,并加载到寄存器中进行使用了。
由于8字节对齐,内存地址后三位永远是0这一特殊的规律,JVM使用这一巧妙地设计,将仅占有32位的对象指针,变成实际上可以使用35位,也就是最大可以表示32GB的内存地址,这一精妙绝伦的设计,笔者叹为观止。
当然,这里只是说JVM在开启指针压缩下的寻址能力,而实际上64位操作系统的寻址能力是很强大的,如果JVM被分配的内存大于32GB,那么会自动关闭指针压缩,使用8字节的指针进行寻址。
解答遗留问题:为什么不使用16字节对齐
第一节的遗留问题,为什么不用16字节对齐的第二个原因,其实学习完指针压缩之后,答案已经很明了了,我们在使用8字节对齐时并开启指针压缩的情况下,最大的内存表示范围已经达到了32GB,如果大于32GB,关闭指针压缩,就可以获取到非常强大的寻址能力。
当然,如果假设JVM中没有指针压缩,而是开始就设定了对象指针只有8字节,那么此时如果需要又超过32GB的内存寻址能力,那么就需要使用16字节对齐,原理和上面说的相同,如果是16字节对齐,那么对象的内存地址后4位一定为0,那么我们在存储和读取的时候分别左移右移4位,就可以仅用32位的指针,获取到36位的寻址能力,寻址能力也就可以达到64GB了。
结语
本篇文章是JVM系列的第二篇,主要基于上一篇的《类和对象在JVM中是如何存储的,竟然有一半人回答不上来!》来解构Java对象,主要阐述了Java对象的内存布局,对其进行了分情况讨论,并在代码中进行佐证,最后深入浅出地谈了谈关于指针压缩技术的技术场景及实现原理。
那么JVM在宏观上,究竟是一种怎样的结构,由什么区域构成,以及JVM在运行时是如何调度这些对象的,这些内容笔者会在下一篇文章中进行阐述。
网站声明:如果转载,请联系本站管理员。否则一切后果自行承担。
- 上周热门
- 银河麒麟添加网络打印机时,出现“client-error-not-possible”错误提示 1487
- 银河麒麟打印带有图像的文档时出错 1405
- 银河麒麟添加打印机时,出现“server-error-internal-error” 1194
- 统信操作系统各版本介绍 1116
- 统信桌面专业版【如何查询系统安装时间】 1114
- 统信桌面专业版【全盘安装UOS系统】介绍 1069
- 麒麟系统也能完整体验微信啦! 1026
- 统信【启动盘制作工具】使用介绍 672
- 统信桌面专业版【一个U盘做多个系统启动盘】的方法 616
- 信刻全自动档案蓝光光盘检测一体机 526
- 本周热议
- 我的信创开放社区兼职赚钱历程 40
- 今天你签到了吗? 27
- 信创开放社区邀请他人注册的具体步骤如下 15
- 如何玩转信创开放社区—从小白进阶到专家 15
- 方德桌面操作系统 14
- 我有15积分有什么用? 13
- 用抖音玩法闯信创开放社区——用平台宣传企业产品服务 13
- 如何让你先人一步获得悬赏问题信息?(创作者必看) 12
- 2024中国信创产业发展大会暨中国信息科技创新与应用博览会 9
- 中央国家机关政府采购中心:应当将CPU、操作系统符合安全可靠测评要求纳入采购需求 8
