与OpenCV联合编译
与OpenCV联合编译
自己环境中存在OpenCV的前提下,同样使用Cmake的find_package命令可以找到,为此,我们修改CmakeLists文件为:
cmake_minimum_required(VERSION 3.12 FATAL_ERROR)
project(simnet)
find_package(Torch REQUIRED) # 查找libtorch
find_package(OpenCV REQUIRED) # 查找OpenCV
if(NOT Torch_FOUND)
message(FATAL_ERROR "Pytorch Not Found!")
endif(NOT Torch_FOUND)
message(STATUS "Pytorch status:")
message(STATUS " libraries: ${TORCH_LIBRARIES}")
message(STATUS "OpenCV library status:")
message(STATUS " version: ${OpenCV_VERSION}")
message(STATUS " libraries: ${OpenCV_LIBS}")
message(STATUS " include path: ${OpenCV_INCLUDE_DIRS}")
add_executable(simnet test.cpp)
target_link_libraries(simnet ${TORCH_LIBRARIES} ${OpenCV_LIBS})
set_property(TARGET simnet PROPERTY CXX_STANDARD 11)在Cmake配置后如果正确找到后会显示以下的信息:
-- Caffe2: CUDA detected: 9.2
-- Caffe2: CUDA nvcc is: /usr/local/cuda/bin/nvcc
-- Caffe2: CUDA toolkit directory: /usr/local/cuda
-- Caffe2: Header version is: 9.2
-- Found cuDNN: v7.4.1 (include: /usr/local/cuda/include, library: /usr/local/cuda/lib64/libcudnn.so)
-- Autodetected CUDA architecture(s): 6.1;6.1
-- Added CUDA NVCC flags for: -gencode;arch=compute_61,code=sm_61
-- Pytorch status:
-- libraries: torch;caffe2_library;caffe2_gpu_library;/usr/lib/x86_64-linux-gnu/libcuda.so;/usr/local/cuda/lib64/libnvrtc.so;/usr/local/cuda/lib64/libnvToolsExt.so;/usr/local/cuda/lib64/libcudart_static.a;-lpthread;dl;/usr/lib/x86_64-linux-gnu/librt.so
-- OpenCV library status:
-- version: 4.0.0
-- libraries: opencv_calib3d;opencv_core;opencv_dnn;opencv_features2d;opencv_flann;opencv_gapi;opencv_highgui;opencv_imgcodecs;opencv_imgproc;opencv_ml;opencv_objdetect;opencv_photo;opencv_stitching;opencv_video;opencv_videoio
-- include path: /usr/local/include/opencv4
-- Configuring done
-- Generating done
-- Build files have been written to: /home/prototype/CLionProjects/simnet/cmake-build-release然后我们的C++代码为:
#include <opencv2/opencv.hpp>
#include "torch/script.h"
#include "torch/torch.h"
#include <iostream>
#include <memory>
using namespace std;
// resize并保持图像比例不变
cv::Mat resize_with_ratio(cv::Mat& img)
{
cv::Mat temImage;
int w = img.cols;
int h = img.rows;
float t = 1.;
float len = t * std::max(w, h);
int dst_w = 224, dst_h = 224;
cv::Mat image = cv::Mat(cv::Size(dst_w, dst_h), CV_8UC3, cv::Scalar(128,128,128));
cv::Mat imageROI;
if(len==w)
{
float ratio = (float)h/(float)w;
cv::resize(img,temImage,cv::Size(224,224*ratio),0,0,cv::INTER_LINEAR);
imageROI = image(cv::Rect(0, ((dst_h-224*ratio)/2), temImage.cols, temImage.rows));
temImage.copyTo(imageROI);
}
else
{
float ratio = (float)w/(float)h;
cv::resize(img,temImage,cv::Size(224*ratio,224),0,0,cv::INTER_LINEAR);
imageROI = image(cv::Rect(((dst_w-224*ratio)/2), 0, temImage.cols, temImage.rows));
temImage.copyTo(imageROI);
}
return image;
}
int main(int argc, const char* argv[])
{
if (argc != 2) {
std::cerr << "usage: example-app <path-to-exported-script-module>\n";
return -1;
}
cv::VideoCapture stream(0);
cv::namedWindow("Gesture Detect", cv::WINDOW_AUTOSIZE);
std::shared_ptr<torch::jit::script::Module> module = torch::jit::load(argv[1]);
module->to(at::kCUDA);
cv::Mat frame;
cv::Mat image;
cv::Mat input;
while(1)
{
stream>>frame;
image = resize_with_ratio(frame);
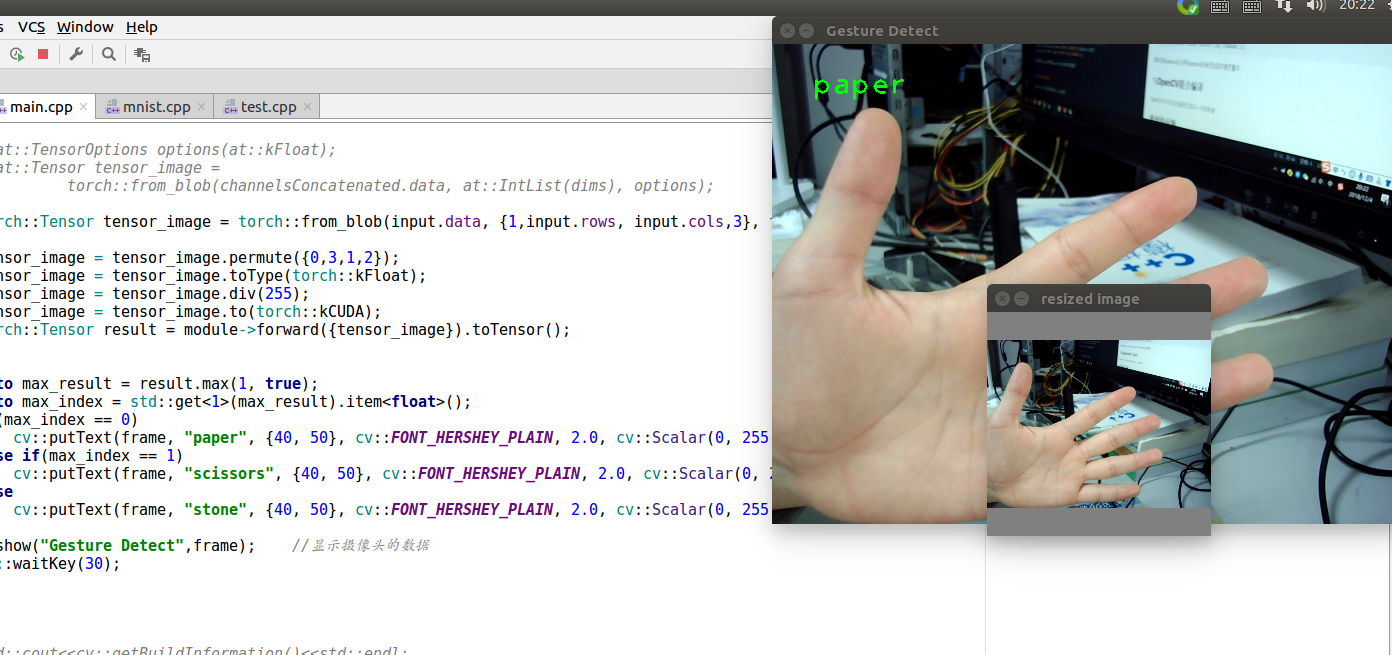
imshow("resized image",image); //显示摄像头的数据
cv::cvtColor(image, input, cv::COLOR_BGR2RGB);
// 下方的代码即将图像转化为Tensor,随后导入模型进行预测
torch::Tensor tensor_image = torch::from_blob(input.data, {1,input.rows, input.cols,3}, torch::kByte);
tensor_image = tensor_image.permute({0,3,1,2});
tensor_image = tensor_image.toType(torch::kFloat);
tensor_image = tensor_image.div(255);
tensor_image = tensor_image.to(torch::kCUDA);
torch::Tensor result = module->forward({tensor_image}).toTensor();
auto max_result = result.max(1, true);
auto max_index = std::get<1>(max_result).item<float>();
if(max_index == 0)
cv::putText(frame, "paper", {40, 50}, cv::FONT_HERSHEY_PLAIN, 2.0, cv::Scalar(0, 255, 0), 2);
else if(max_index == 1)
cv::putText(frame, "scissors", {40, 50}, cv::FONT_HERSHEY_PLAIN, 2.0, cv::Scalar(0, 255, 0), 2);
else
cv::putText(frame, "stone", {40, 50}, cv::FONT_HERSHEY_PLAIN, 2.0, cv::Scalar(0, 255, 0), 2);
imshow("Gesture Detect",frame); //显示摄像头的数据
cv::waitKey(30);
}然后在cmake时添加-DCMAKE_PREFIX_PATH=/path/to/pytorch/torch/lib/tmp_install引入libtorch路径。
这样我们的程序就可以运行了~
《利用Pytorch的C++前端(libtorch)读取预训练权重并进行预测》
关于这个libtorch-C++的API的具体讲解,因为篇幅原因没有详细写出来,会在之后的文章中进行说明。
遇到的问题
上述的编译中可能会出现这个问题,或者其他出现一大堆命名定义但显示未定义的函数:
error: undefined reference to `cv::imread(std::string const&, int)'如果你的OpenCV在单独编译使用时没有错误,但是一块编译就出现问题,那么这代表我们的libtorch库和OpenCV库冲突了,冲突原因可能是OpenCV编译OpenCV的C++-ABI版本和libtorch中的不同,所以建议OpenCV最好和libtorch在同样的环境下编译。

《利用Pytorch的C++前端(libtorch)读取预训练权重并进行预测》
网站声明:如果转载,请联系本站管理员。否则一切后果自行承担。
赞同 0
评论 0 条
- 上周热门
- 银河麒麟添加网络打印机时,出现“client-error-not-possible”错误提示 1448
- 银河麒麟打印带有图像的文档时出错 1365
- 银河麒麟添加打印机时,出现“server-error-internal-error” 1151
- 统信桌面专业版【如何查询系统安装时间】 1073
- 统信操作系统各版本介绍 1070
- 统信桌面专业版【全盘安装UOS系统】介绍 1028
- 麒麟系统也能完整体验微信啦! 984
- 统信【启动盘制作工具】使用介绍 627
- 统信桌面专业版【一个U盘做多个系统启动盘】的方法 575
- 信刻全自动档案蓝光光盘检测一体机 484
- 本周热议
- 我的信创开放社区兼职赚钱历程 40
- 今天你签到了吗? 27
- 信创开放社区邀请他人注册的具体步骤如下 15
- 如何玩转信创开放社区—从小白进阶到专家 15
- 方德桌面操作系统 14
- 我有15积分有什么用? 13
- 用抖音玩法闯信创开放社区——用平台宣传企业产品服务 13
- 如何让你先人一步获得悬赏问题信息?(创作者必看) 12
- 2024中国信创产业发展大会暨中国信息科技创新与应用博览会 9
- 中央国家机关政府采购中心:应当将CPU、操作系统符合安全可靠测评要求纳入采购需求 8
热门标签更多
