大数据基准 TPC-DS 研究(4) - 商业模型设计

TPC-DS 的目标是提供一个公平/诚实的业务和数据模型,以评估决策支持系统(主要指数据库管理系统)的整体性能表现.
主要特点
- 采用星型、雪花型等多维数据模式: 它包含7张事实表,17张纬度表平均每张表含有18列
- 其工作负载包含99个SQL查询,覆盖SQL99和2003的核心部分以及OLAP (不再限制被测系统做特殊处理, 比如关闭物化视图等), 测试场景包含四大场景: 对大数据集的统计报表生成、即席查询、迭代式查询、数据挖掘.
- 测试用的数据和值是有倾斜的,与真实场景非常相似
- 对数据的维护操作(提取、转换和加载)有对应的测试负载
商业模型
TPC 对任何需要管理/销售/分销产品的行业(比如食品, 家具, 玩具等)进行建模, 可以理解为一家全国连锁的大型零售公司, 并且除了实体店外, 该公司还通过目录和网络这两种渠道进行销售. 同时这家公司还有一个仓库系统和一个促销活动系统. 以下是一些可能的数据处理需求:
- 对三个渠道分别追踪顾客的购买和退货
- 根据促销活动修改商品价格
- 管理维护仓库
- 生成动态网页
- 维护顾客信息 (顾客关系管理)
目录销售:
消费者通过查阅“目录购物商场”定期发行的购物目录,拨打“商场”话务中心的电话订购,再由专业快递公司提供快捷优质的送货上门服务,后付款的购物方式。
可以理解为互联网电商的早期形态.
数据模型与访问假设
- TPC-DS 在数据查询时可以假设数据是静止的. (允许长时间查询, 或分几步查询的情况)
- TPC-DS 通过数据维护函数可以跟进 DSS 的状态(可能有延迟)
- TPC-DS 是雪花模型, 由多个事实表和维度表组成. 维度表可以被分类为:
- 静态: 加载后不再变化
- 历史型: 通过新增加一行(时间字段更新)来表示对历史数据的修改.
- 非历史型: 通过覆盖的方式来表示对历史数据的修改.
- 允许系统管理员一次性的设置锁级别(以配置在满足一致性要求下达到最好的性能表现)
- 可以提供不同规模的被测试数据尺寸 (可以通过规模因子控制)
用户查询模型假设
TPC-DS 认为用户的查询语句目标都是为了解决复杂的业务问题, 主要包含如下四大类:
- 报表查询
- 周期性的执行固化的查询
- 重点关注业务的财务和运营情况
- 虽然查询内容相对固化, 但是每次可能会有微调, 比如变更日期范围/地理位置等
- Ad-hoc 查询
- 临时的一次性的查询
- 重点关注需要立即被回答的一些具体商业问题
- 和报表相比, 最重要的区别是对查询模式事先无法预知
- 迭代式 OLAP 查询
- 一次会话中为特定场景执行的一系列的查询
- 重点关注商业数据分析以探索新的有意义的模式或趋势
- 和 Ad-hoc 类似, 区别是多次查询(包含简单和复杂)是基于特定场景迭代的
- 数据挖掘
- 基于大量数据来筛选出数据内容的关联关系
- 重点关注未来趋势, 为商业决策提供前瞻性的支持
- 查询中通常包含大量的跨表/聚合, 返回结果集一般较大
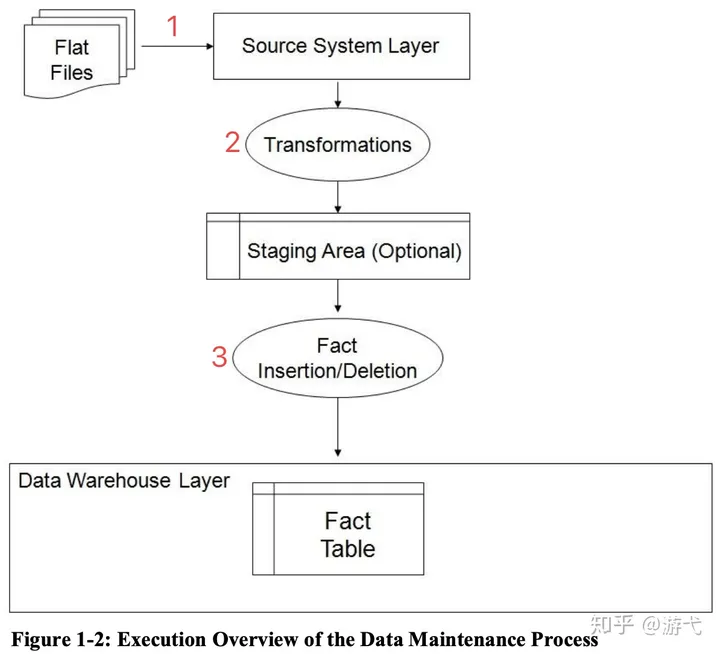
数据维护模型假设
DSS系统的数据一般来说是来自 OLTP 系统, 将数据从 OLTP 系统迁移到 DSS 的过程很重要, 但是对于不同的业务场景来说这个迁移的过程的差异性非常大. 一般来说主要分为 ETL 三步:
- 数据抽取(Extraction):
- 从生产 OLTP 数据库或其它的数据源中将相关的数据抽取出来.
- 针对不同的源数据, 方法差异很大, 因此 TPC-DS 并未对此步骤建模.
- TPC-DS 的数据维护都是从平铺的文件开始的 (这些文件可被认为是数据抽取进程的结果)
- 数据转换(Transformation):
- 此步骤将抽取出来的数据进行清洗和格式转换, 以适应 DSS 的格式需求.
- 数据加载(Load):
- 对 DSS 中的数据进行插入/修改/删除操作
TPC-DS 的数据维护包含如下任务:
- 加载起新的数据集, 包含新增/删除/修改的数据
- 将新的数据集插入 DDS 中, 并应用数据转换
- 数据反范式化(由第三范式到雪花型), 源表:目标表为1:1, 1:多, 多:1 都可以.
- 按语法进行数据清洗
- 插入新的事实表记录, 根据日期删除旧的记录
网站声明:如果转载,请联系本站管理员。否则一切后果自行承担。
赞同 0
评论 0 条
- 上周热门
- WPS City Talk · 校招西安站来了! 3757
- 服贸会|范渊荣获年度创新领军人物!王欣分享安恒信息“AI+安全”探索 3683
- 有在找工作的IT人吗? 3646
- 字节跳动“安全范儿”高校挑战赛来袭!三大赛道,赢 80 万专项基金! 3604
- 阿B秋招线下宣讲行程来啦,速速报名! 3599
- 字节跳动校招 | 电商业务 2025 校园招聘进行中!五大职类热招,等你来投! 3590
- 麒麟天御安全域管平台升级!为企业管理保驾护航 3575
- 烽火通信2025届校园招聘宣讲行程发布!! 3411
- 2024海洋能源产业融合发展论坛暨博览会同期活动-海洋能源与数字化智能化论坛成功举办 3372
- 华为全联接大会2024丨软通动力分论坛精彩议程抢先看! 3343
- 本周热议
- 我的信创开放社区兼职赚钱历程 40
- 今天你签到了吗? 27
- 如何玩转信创开放社区—从小白进阶到专家 15
- 信创开放社区邀请他人注册的具体步骤如下 15
- 方德桌面操作系统 14
- 我有15积分有什么用? 13
- 用抖音玩法闯信创开放社区——用平台宣传企业产品服务 13
- 如何让你先人一步获得悬赏问题信息?(创作者必看) 12
- 2024中国信创产业发展大会暨中国信息科技创新与应用博览会 9
- 中央国家机关政府采购中心:应当将CPU、操作系统符合安全可靠测评要求纳入采购需求 8
热门标签更多
