大数据工程师就业的现状和前景如何?

大数据工程师是一个热门的职业,其就业现状和前景都非常乐观。以下是一些相关信息:
1.就业现状:大数据工程师的需求量正在不断增长,尤其是在科技、金融、零售等行业。许多大型企业、中小企业、初创企业都在招聘大数据工程师。根据一些数据分析公司的数据,大数据工程师的就业市场相对紧缺,需求和供给的比例不平衡。
2.薪资待遇:大数据工程师是一个高薪职业,根据 Glassdoor 网站的数据,大数据工程师的平均年薪在美国超过12万美元。在中国的一些一线城市,大数据工程师的年薪也在30万人民币以上。
3.发展前景:大数据工程师的发展前景非常广阔。随着大数据技术的发展和普及,越来越多的企业需要大数据工程师来构建和维护其大数据平台。同时,随着人工智能、云计算、物联网等技术的发展,大数据工程师的职能也在不断扩展。未来,大数据工程师的职业前景将会更加广阔。
总之,大数据工程师是一个前景非常广阔、薪资待遇非常优厚的职业。如果您对大数据技术有兴趣,并具备相关的技能和经验,可以考虑在这个领域发展。
随着科技的发展,大家肯定会越来越重视数据的流向,包括数字化中国,都需要数据作为支撑,所以大数据方向是一个不错的选择。
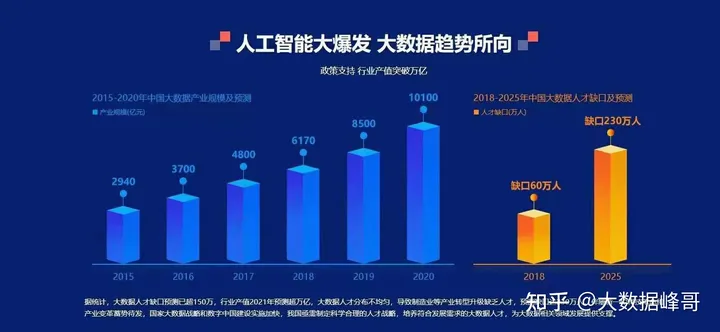
大数据目前还处于红利期,大数据人才缺口2025年将高达230万人!!!
这里推荐大家看下这份资料:一本资料读懂大数据,每个人都看得懂的大数据入门资料
本书从大数据时代的前因后果讲起,全面分析大数据时代的特征、企业实践的案例、大数据的发展方向、未来的机遇和挑战等内容,可以更好地帮你更加全面的了解大数据。
分享一位学习群的小伙伴转型经历给你参考,他毕业之后做过微商、服务员、销售、外卖小哥等,后面去培训机构培训运维,最后转的大数据开发。薪资也从最开始的个人薪资4K,到现在的年薪40W。
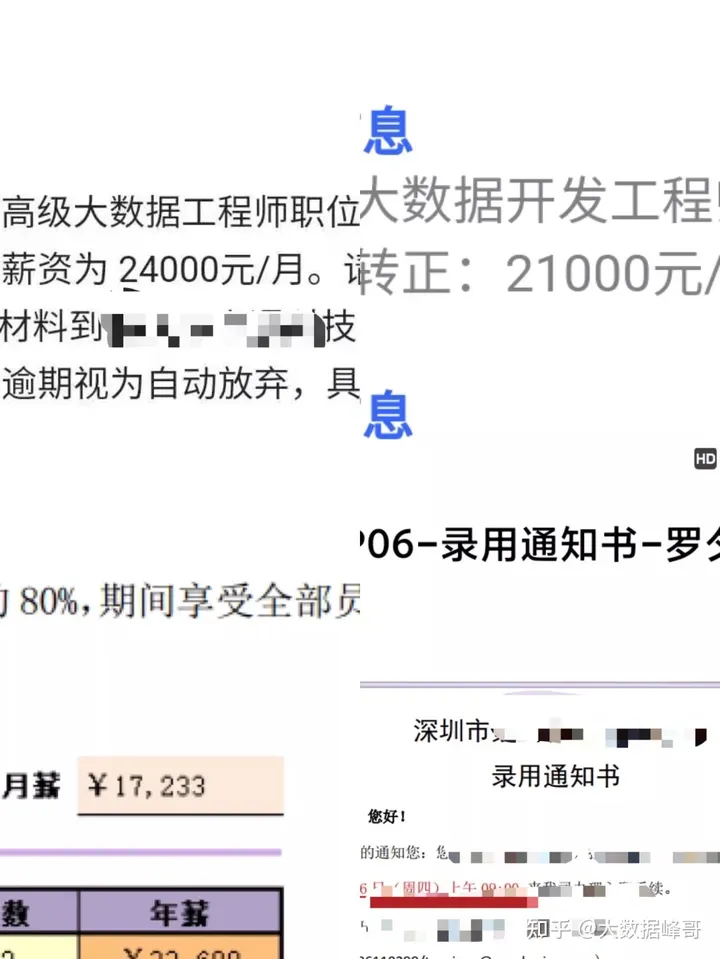
部分offer(仅代表个人收入)
一、不堪回首的奋斗往事
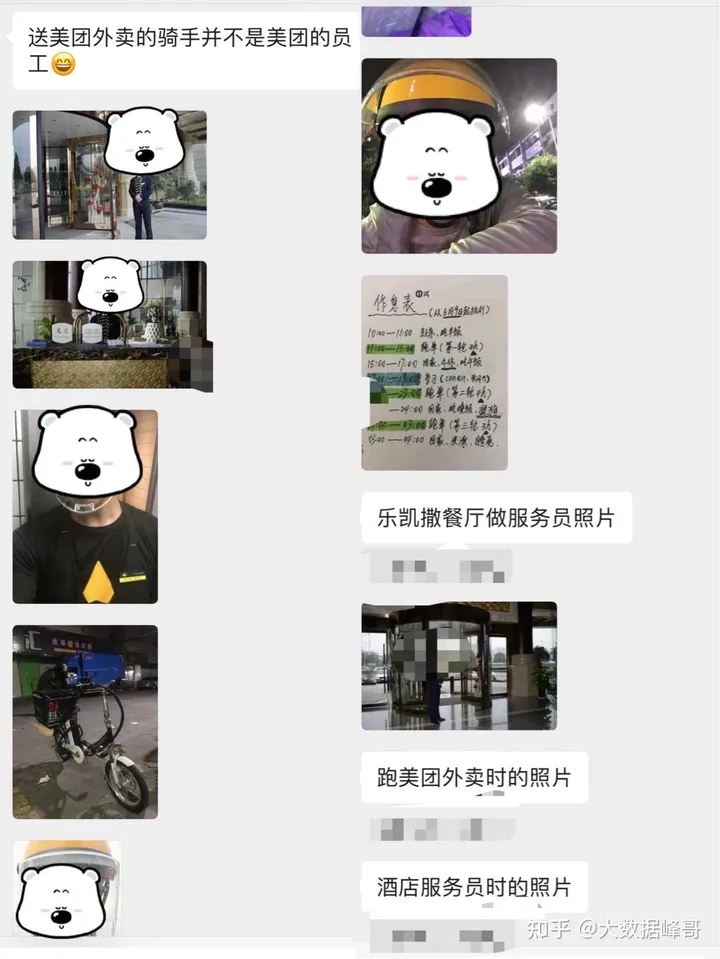
2016年6月从湖南某二本文科专业毕业之后在老家做了半年的微商
2017年2月南下深圳,先是做过维也纳酒店的前台服务员,贷款中介公司的电话销售,自如友家的服务管家,后来还去跑过美团外卖,以及在乐凯撒餐厅做过披萨,在这一年多的时间里,个人平均月收入只有4K。
2018年9月参加某机构线下Python培训半年。
2019年3月入职深圳某A公司从事Python运维工作,月薪9.7K。
2020年1月离职在家自学大数据,在此非常感谢@无精疯 峰哥当时的耐心指导和帮忙规划学习路线,三个月后成功转型大数据,入职深圳某B公司从事数据仓库开发工作,月薪17K。
2020年10月离职后入职深圳某C公司从事大数据开发工作,月薪21K
2021年4月经峰哥再次指导,成功入职深圳某世界500强企业,担任高级大数据工程师职位,月薪27K,总包40W。
二、大数据转型时期的学习路线
第一阶段:学完第一阶段就可以开始找数据仓库开发相关的岗位了(市场上40%的岗位可以投了)
1、Java基础:JavaSE
2、SQL课程:MySQL【重点】
3、Linux基础
4、Hadoop框架:HDFS、MapReduce、Yarn【重点】
5、Hive【重点】
6、HBase
7、辅助框架:Flume、Sqoop、Azkaban
这份资料涵盖了Java基础、集合、JVM多线程、Spring、微服务分布式、计算机基础(网络、操作系统)、数据库、大数据等面试知识点,对于Java或大数据岗来说完全够用,大家可以直接拿着它补缺补漏。
8、大数据项目实战(一):基于Hive的离线数仓项目【重点中的重点】
第二阶段:学完第二阶段就可以找大数据开发相关的岗位了(市场上75%的岗位都可以投了)
1、Scala基础
2、Spark框架:SparkSQL、SparkStreaming【重点】
3、Kafka消息队列
4、大数据项目实战(二):基于Spark的实时+数仓项目【重点中的重点】
第三阶段:学完第三阶段就可以找所有和数据开发相关的岗位了(市场上90%的岗位都可以投了)
1、Flink【重点】
2、Redis
3、大数据一些其它的辅助框架(Kylin、Druid、Presto、Impala、ClickHouse等)
4、大数据项目实战(三):基于Flink的实时ETL和数仓项目【重点中的重点】
第四阶段:(进一线互联网大厂必备的技能)
1、计算机基础和数据结构算法
这份笔记里面共包含作者刷LeetCode算法题后整理的数百道题,每道题均附有详细题解过程。很多人表示刷数据结构和算法题效率不高,甚是痛苦。有了这个笔记的总结,对校招和社招的算法刷题帮助之大不言而喻,果断收藏了。
2、Java底层和部分框架源码
三、企业面试真题
这份资料涵盖了Java基础、集合、JVM多线程、Spring、微服务分布式、计算机基础(网络、操作系统)、数据库、大数据等面试知识点,对于Java或大数据岗来说完全够用,大家可以直接拿着它补缺补漏。
1、请详细描述下hive中shuffle的优化?
2、hive在集群过程中怎么解决数据倾斜?
3、hive导致数据倾斜的可能性(哪些操作会导致)-->分桶 join key 分布不均匀的大量空值导致如何解决?
4、悲观锁和乐观锁的区别以及CAS乐观锁怎么实现,或者有哪些其他方式?
5、编程的设计模式举例一下,用过哪些,什么场景下使用的?
6、你对实时计算这块的理解是怎么样的?
7、Sparkstreaming突然断掉了怎么办?怎么保证数据消费至少一次和精确一次?
8、Sparkstreaming消费kafka数据怎么手动维护offset ?Offset保存到什么数据库?处理的顺序是什么?以及程序刚上线第一次从kafka消费这是怎样的流程?
9、Spark解决了哪些问题让你很有成就感?
10、Spark发生了数据倾斜你会怎么做?
11、Sparkstreaming的背压机制,除了设置背压参数为true之外还需要做什么?
12、Spark性能调优?
13、跑spark作业的时候,给到executor的个数是10个,每个executor的核数是2个,请问跑这个作业时并行度设置为多大比较合适?
14、这么做是为了避免shuffle操作,shuffle为什么会存在数据倾斜?
15、为什么会有shuffle的存在?shuffle操作的意义又是什么?
16、Java中的ArrayList的底层数据结构?LinkedList?
17、创建一个ArrayList里面的空间有多大?
18、让你设计一个容器类,比如ArrayList,你怎么去实现?
19、HashMap的数据结构是什么?为什么要这么设计?
20、数组和链表的区别是什么?
21、你们每天需要同步的数据量有多大?
22、Druid的工作原理?
23、每天集群的数据增量有多大?
24、业务数据量有多大?每日订单量有多少?
25、各大数据组件在各机器上是怎么分配的?
26、离线和实时分别是怎么分层设计的?
27、维表数据的加载和更新?
28、生产环境中Kafka要增加topic分区的时候怎么操作?
29、数仓中每层用的数据存储格式分别是什么?
30、Hive中两个大表进行join的时候有什么优化方法?
31、JVM的垃圾回收器有哪些?你们用的哪种?
32、项目架构流程图:手画+讲解
33、Druid和Kylin做一个技术选型你会考虑哪些因素?
34、现有一个n*m的方格,每个格子里有一个100以内的随机数字,现在需要从方格的最左上角走到最右下角,只能往下和往右走,如何计算出数字之和最大的一条路线?
35、流处理:用户如果在10s内,同时连续输入同样一句话超过5次,就认为是恶意刷屏,请您写出检测刷屏用户的代码?
这些都是我阅读过的优秀资料,里面涵盖了计算机大部分的知识,我也做了详细的归类,已经整理到网盘了,大家可以自行下载。
四、总结
在大学毕业之后,我花了足足3年的时间仅仅才实现月薪从4K到9.7K,而后面仅仅花了3个月的时间就实现了月薪从9.7K到17K,以及最近1年的时间已经实现从17K到27K,对此,我最想说的四句话就是:
1、选择大于努力,知识改变命运;
2、找准自己的赛道,然后努力奔跑,做到足够自律,在这个过程中你可能会很痛苦,但是不要轻言放弃;
3、想获得更快速的成功,还得需要高人的指点和贵人的相助;
网站声明:如果转载,请联系本站管理员。否则一切后果自行承担。
- 上周热门
- WPS City Talk · 校招西安站来了! 3757
- 服贸会|范渊荣获年度创新领军人物!王欣分享安恒信息“AI+安全”探索 3683
- 有在找工作的IT人吗? 3646
- 字节跳动“安全范儿”高校挑战赛来袭!三大赛道,赢 80 万专项基金! 3604
- 阿B秋招线下宣讲行程来啦,速速报名! 3599
- 字节跳动校招 | 电商业务 2025 校园招聘进行中!五大职类热招,等你来投! 3590
- 麒麟天御安全域管平台升级!为企业管理保驾护航 3575
- 烽火通信2025届校园招聘宣讲行程发布!! 3411
- 2024海洋能源产业融合发展论坛暨博览会同期活动-海洋能源与数字化智能化论坛成功举办 3372
- 华为全联接大会2024丨软通动力分论坛精彩议程抢先看! 3343
- 本周热议
- 我的信创开放社区兼职赚钱历程 40
- 今天你签到了吗? 27
- 如何玩转信创开放社区—从小白进阶到专家 15
- 信创开放社区邀请他人注册的具体步骤如下 15
- 方德桌面操作系统 14
- 我有15积分有什么用? 13
- 用抖音玩法闯信创开放社区——用平台宣传企业产品服务 13
- 如何让你先人一步获得悬赏问题信息?(创作者必看) 12
- 2024中国信创产业发展大会暨中国信息科技创新与应用博览会 9
- 中央国家机关政府采购中心:应当将CPU、操作系统符合安全可靠测评要求纳入采购需求 8
