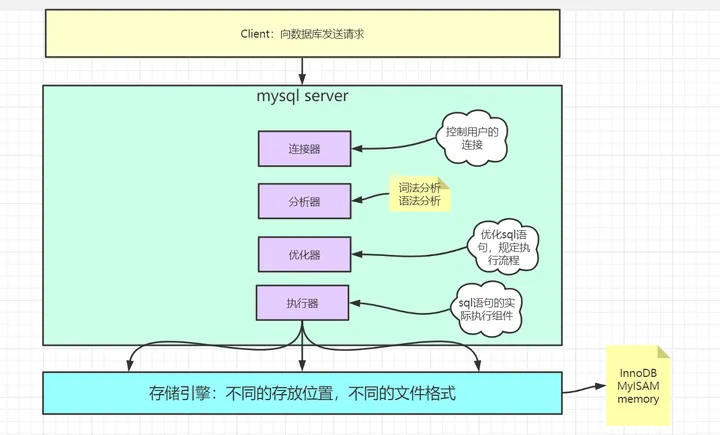
Mysql索引

索引为什么能加快查询?
数据库中最常见的慢查询优化方式是什么?
为什么加索引能优化慢查询?
哪些数据结构可以提高查询速度?
既然这些数据结构能优化查询速度,mysql为什么选择使用B+树?
索引放在哪?磁盘or内存?:
磁盘,只不过sql查询的时候需要把磁盘里的索引加载到内存。
索引是什么?
索引是帮助Mysql高效获取数据的数据结构
索引存储在文件系统中
索引的文件存储形式与存储引擎有关
innoDB:磁盘作为存储介质
MyISAM:磁盘作为存储介质
memory:内存作为存储介质
不同的文件格式指的是:不同的存储引擎下,数据文件和索引文件存放的位置是不同的;因此有了分类:
聚簇索引:数据文件和索引文件放在一起:InnoDB
非聚簇索引:数据文件和索引文件不放在一起,各自单独:MyISAM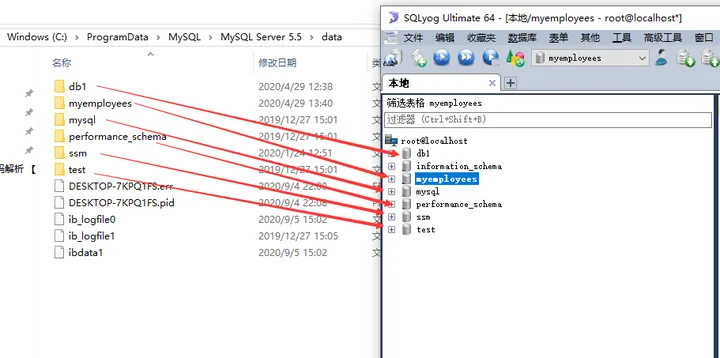
打开这个ssm文件夹,ssm是一个数据库。
我现在是innodb存储引擎:

.frm文件存放的是数据库里的表结构
.ibd存放的是数据文件和索引文件。
但是截图里并没有 .ibd文件
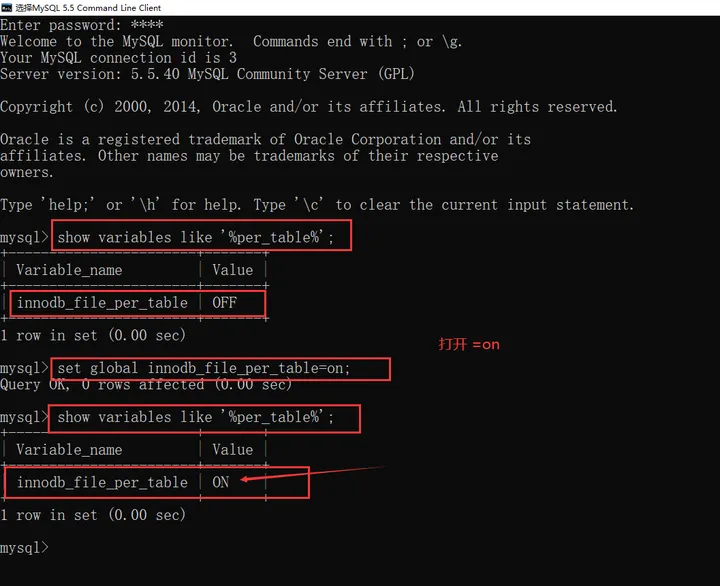
不急,打开mysql客户端,window下。默认是false,打开就是on
在sqlyog里的ssm库里创建一个xxoo表:就可以看到ssm文件夹里多出来一个xxoo.frm和xxoo.ibd,ibd文件出现了。
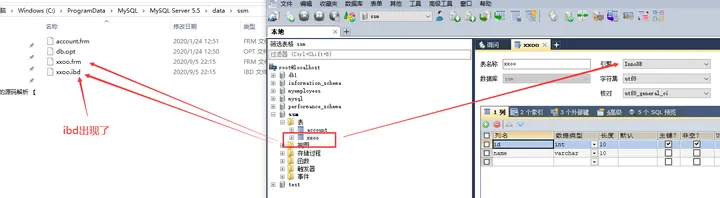
所以mysql的innodb存储引擎默认情况下会把所有的数据文件放到表空间中,不会为每一个单独的表保存一份数据文件,如果需要将每一个表单独使用文件保存,设置set global 上上图。
所以只有设置了,才能把数据文件和索引文件单独存放到 .ibd 文件中。

索引文件的结构:hash,二叉树,B树,B+树
hash表可以完成索引的存储,每次在给某个字段添加索引的时候,都要计算该列的hash值,取模运算后计算出下标,将元素插入下标位置即可;
适合的场景:等值查询,不适合区间查询。
表中的数据是无序数据,范围查找比较浪费时间,需要挨个进行遍历操作
hash表在使用的时候,需要将全部的数据加载到内存,比较耗费内存的空间。
树:多叉树,二叉树,AVL树(平衡二叉树),红黑树。
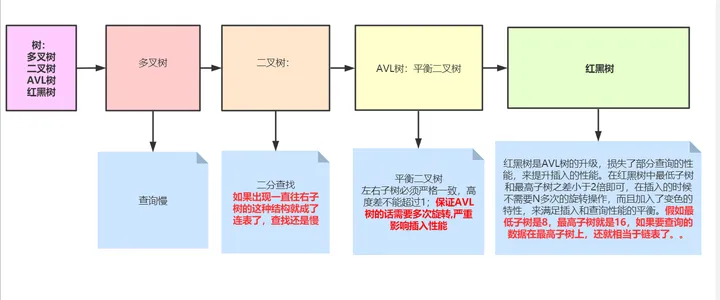

最适合的还是多叉树,多叉树就是B树。B树又名:B-树,B-Tree

B树的图:一个磁盘块4K大小的话
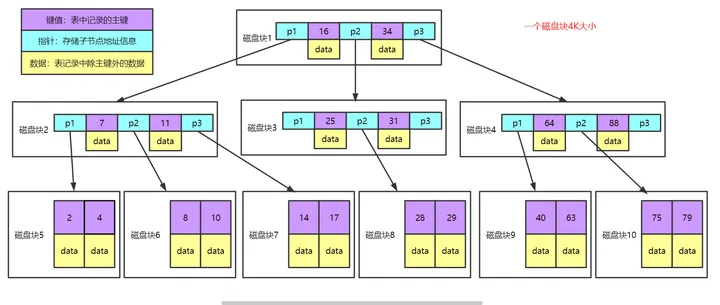
索引存储在磁盘,磁盘预读一个页的整数倍,假如正好是4K,那么对应上图就是每次读一个磁盘块。可以看到一个磁盘快里有指针(p1,p2,p3)指针指向其他的磁盘块,除了指针还有16 ,34(第一个磁盘块)16和34指着的建索引的时候列的值,还有个data。假如找id=16这条数据,那么刚好从读第一个磁盘块就找到了16对应的data。
如果现在找id=28,那么就先读磁盘块1,磁盘块3,磁盘块8。就刚好找到了,一共读了3次数据,一共读了12K的数据。从磁盘读12KB的数据到内存是很快的。
那么看似没有问题,在仔细想一下,每一个磁盘块里都包含key和data,那么这个data多大呢?假如一个表有100个字段,每一个字段都是varchar,并且把varchar写满了。那么一条数据假设id = 1这条数据,就有100列,每一列占用的容量都很大。假设一条数据,也就是一个data是1KB。其他忽略不计,那么就代表一个磁盘块里最多存储4个1KB,4个data,4条数据。那一个3层的B树最多能存储4的三次方 = 64条数据。那这不是在开玩笑?测试代码的时候,数据库随便搞一下都比64条数据多。
所以B树有一个问题:当每一个节点里存太多的数据,会导致树的深度有5678N层。而树的深度越深,io次数就越多,io的量也在增大。所以当这种情况的B树存索引的时候,在进行查询的时候,因为树深所以io的次数过多,读取的io量很多,会对性能产生影响。
缺点:每个节点都有key和data,而每个页存储空间是有限的假如4K,如果data比较大会导致每个节点存储的key数量变少(举个例子,就拿第一个磁盘块来说,4K的时候,如果一个data是1K,忽略其他不计的话,那么就有4个data和对应的key,假如data变成2K,那么就只能有2个data和2个key。所以data变大的话,key就小了。key数量小的话,意味着范围就越小,如果key越多的话,说不定第二次查找到第二层就找到数据了,也就节省了io了)当存储的数量很大的时候会导致树的深度较大,增大查询时磁盘io次数,进而影响性能查询。
既然B树优缺点,那么把data放到叶子结点就行了,MySQL使用的B+树

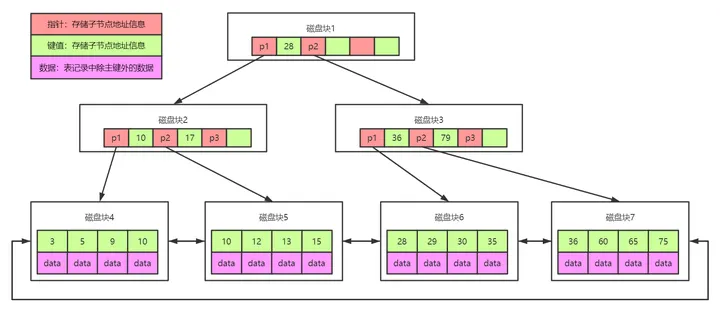
那现在可以放多少数据呢?计算一下
假设指针和一个key占10字节,磁盘块1是4K,算4000字节,那第一层可以放400对指针和key,第二层也是400对指针和key,第三层data算1K,第三层是4条数据。
一个3层的B+树一共可以放 400 X 400 X 4 = 64万数据,相比于B树的64条数据多了去了。
除此之外,B+树还有一个优化就是在B+树上有两个头指针,一个指向根节点,另一个指向关键字最小的叶子节点,而且所有的叶子节点(数据节点)之间是一种链式环结构。因此可以对B+树进行两种查找运算:一种是对于主键的范围查找和分页查找,另一种是从根节点开始,进行随机查找。
一般情况下,mysql或者oracle会自动给主键或者唯一键,建立索引。为什么不会给其他字段建立索引?
一旦用了索引的话,每次读取的时候做了两件事:
1、先去遍历索引文件。2、再去遍历数据文件
要更新数据的话,维护索引是一件很麻烦的事,所以不要拍脑袋就随意给某个字段建立索引。
MySQL InnoDB B+树,叶子节点直接存放数据。
数据表:
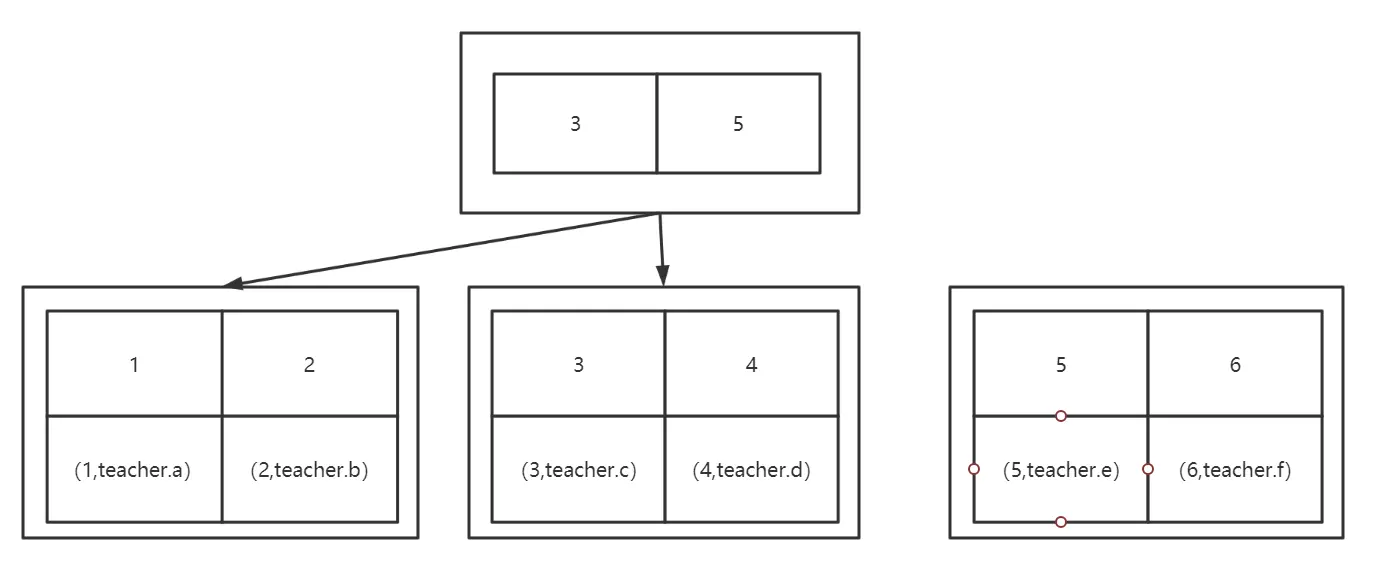
InnoDB是通过B+树结构对主键创建索引,叶子节点中存储数据记录,如果没有主键,那么会选择唯一键,如果没有唯一键,则会生成一个6为的row_id作为主键。(row_id不可见),在InnoDB存储引擎中,除了默认方式外,索引文件和数据文件一起保存在.ibd文件中。
如果创建索引的键是其他字段,那么在叶子节点中存储的是该记录的主键,然后通过主键索引找到对应的记录,这种情况叫做 回表
如果给name字段加索引的话,那么图就变了。
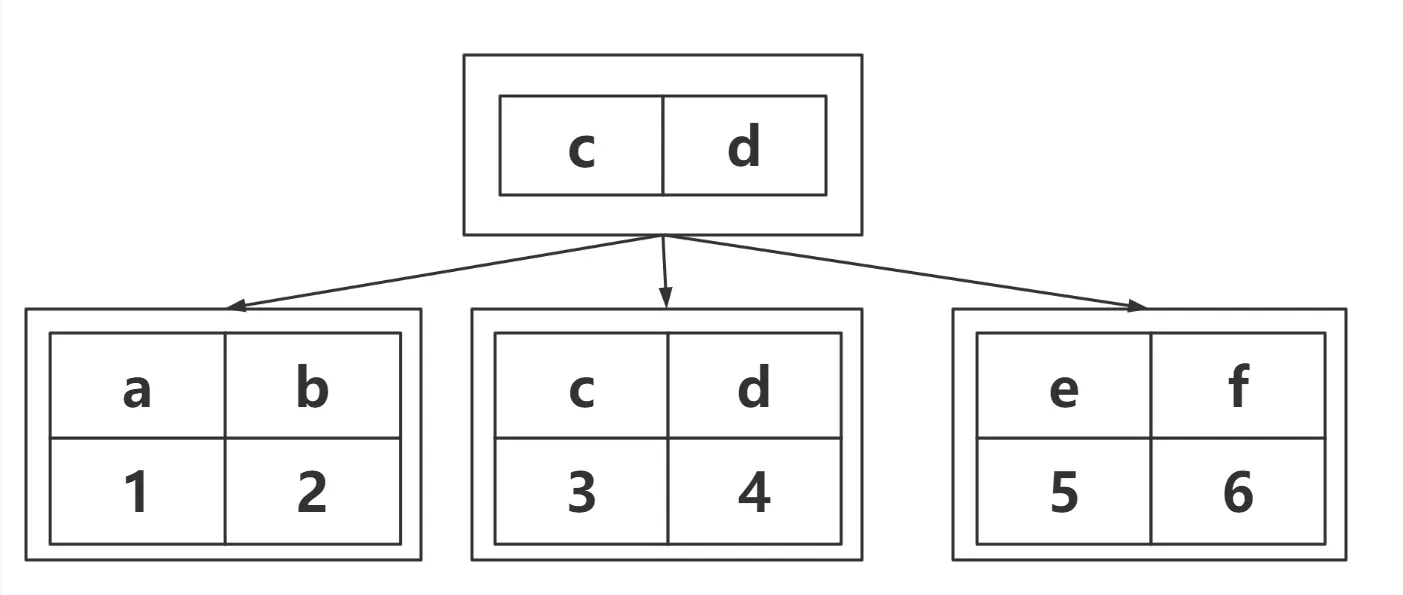
叶子节点保存的不再是数据,而是主键key,也就是数据表里的 id。假设找 name = d。那么找到的叶子节点是id = 4,然后通过id = 4 去上上图再去查找,最终在上上图的 叶子节点中找到完整的记录(4,teacher.d)。这就是回表。所以给普通字段建立索引,就这个数据表来说走了4次io,遍历了两颗B+树。一颗B+树走两次io。
再说一下MyISAM存储引擎下的B+树的索引
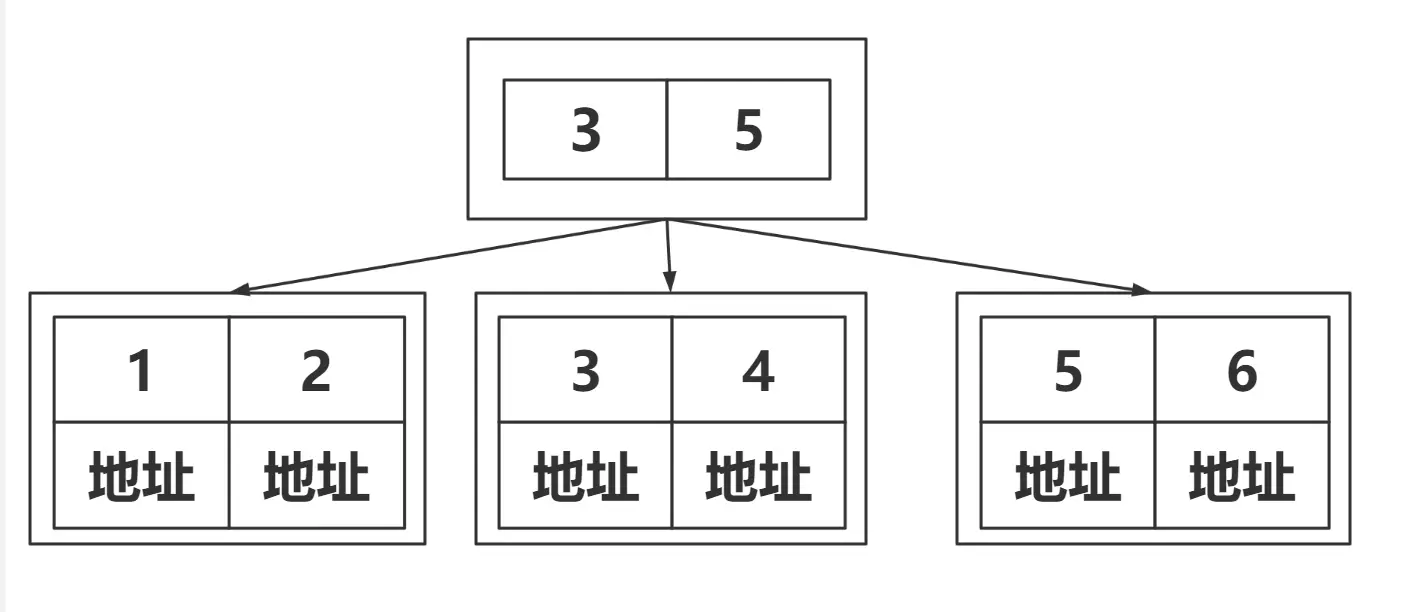
查找到的叶子节点的并不是整条记录,而是地址,再根据地址去数据文件里查找数据。因为这种存储引擎下,索引文件和数据文件是分开保存的。
MySQL索引的类型:
主键索引:主键索引是一种唯一性索引,必须指定为primary key,每个表只能有一个主键
唯一索引:索引列的所有值都只能出现一次,必须唯一,值可以空(不需要回表操作)
普通索引:基本的索引类型,值可为空,没有唯一性的限制(覆盖索引)(需要回表操作)
简单说一下覆盖所引,假如一个表有两个列,id和name都建立了索引,
假如 select * from table where name = ""; 这个sql语句就是要走两颗B+树;
假如 select id from table where name = "";这个sql语句就不用走两颗B+树了,因为name是普通字段,B+树的叶子节点上保存的是主键id,sql语句也是查询的id ,
这就叫做覆盖所引
全文索引:索引类型为FullText。可以在varchar,char,text类型的列上创建
组合索引:多列值组成一个索引,专门用于组合索引(最左匹配原则)
MySQL存储引擎中MyISAM适合大量select ,innoDB适合增删改。innoDB对事务表锁行锁外键都支持,5.6后还支持全文索引。而MyISAM有的支持有的不支持。
索引维护:
索引在插入新的值的时候,为了维护索引的有序性,必须要维护。维护索引分为几种情况:
1、如果插入一个比较大的值,直接插入,几乎没有成本。
2、如果插入的是一个中间的某一个值,需要逻辑上移动后续元素。空出位置。
3、如果需要插入的数据页满了,就需要单独申请一个新的数据页,然后移动部分数据过去,这叫做页分裂,此时性能会受影响同时空间的使用率也会降低,除了页分裂之外还有页合并。
4、尽量使用自增主键作为索引。
网站声明:如果转载,请联系本站管理员。否则一切后果自行承担。
- 上周热门
- 如何使用 StarRocks 管理和优化数据湖中的数据? 2972
- 【软件正版化】软件正版化工作要点 2891
- 统信UOS试玩黑神话:悟空 2864
- 信刻光盘安全隔离与信息交换系统 2749
- 镜舟科技与中启乘数科技达成战略合作,共筑数据服务新生态 1283
- grub引导程序无法找到指定设备和分区 1253
- 华为全联接大会2024丨软通动力分论坛精彩议程抢先看! 169
- 2024海洋能源产业融合发展论坛暨博览会同期活动-海洋能源与数字化智能化论坛成功举办 169
- 点击报名 | 京东2025校招进校行程预告 165
- 华为纯血鸿蒙正式版9月底见!但Mate 70的内情还得接着挖... 161
- 本周热议
- 我的信创开放社区兼职赚钱历程 40
- 今天你签到了吗? 27
- 信创开放社区邀请他人注册的具体步骤如下 15
- 如何玩转信创开放社区—从小白进阶到专家 15
- 方德桌面操作系统 14
- 我有15积分有什么用? 13
- 用抖音玩法闯信创开放社区——用平台宣传企业产品服务 13
- 如何让你先人一步获得悬赏问题信息?(创作者必看) 12
- 2024中国信创产业发展大会暨中国信息科技创新与应用博览会 9
- 中央国家机关政府采购中心:应当将CPU、操作系统符合安全可靠测评要求纳入采购需求 8
