SpringCloud中的Hystrix

项目不可能一点问题都不出,假如说请求超时了,怎么解决?
分为两个部分:
1、建立连接的时候请求超时,网络不通畅
2、连接建立成功,业务线程耗时,所以超时。
连接超时是在consumer端的,配置ribbon
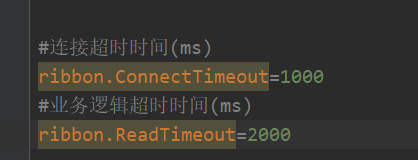
假如在provider端睡了4秒,那么consumer调用provider的时候consumer就会报一个
read timed out executing get http://xxx/xxx的错误,但是在provider端是不会报错的反而,假设服务端有打印的话,会打印出provider的端口被调用了2次,为什么是2次? 因为配置的业务逻辑超时时间是2s = 2000毫秒,睡了4秒,所以睡4秒的时间里,刚好调用了2次。这里ribbon是可以提供重试的,即provider没有给consumer回应的话,consumer会自动重试的。假如有两个provider端口分别是81 和 82,配置不变还ribbon.ReadTimeout=2000,provider里的业务逻辑还是睡4秒的话,那么就端口82被调用一次,81调用一次,当然这也要看负载均衡策略。这就是ribbon提供的负载均衡和重试机制
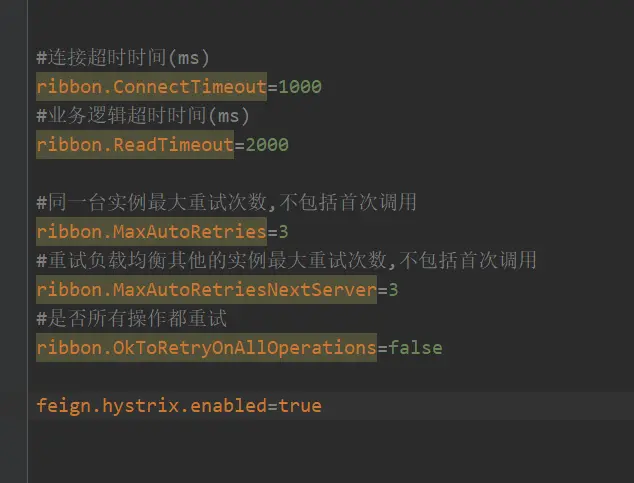
这都是在consumer端配置的。
假设起了2个provider,81里面睡0.5秒,这个consumer是可以调通的,但是另一个82里睡了4秒,这是consumer调不通的。默认ribbon还是轮询,第一次调用81,可以调通,但是第二次调用82,因为刚配置的是重试3次,不包括首次,所以会调4次82,页面就卡住了,一直在转圈还没返回。下一次还是81,下一次还是81,下一次还是81,因为82不通,所以就一直走81了,但是有可能是网络原因,过一会又去掉82了,不长记性,6秒吧,81和82之间,假如82不通,调用81,下一次还是81, 6秒后就会调用82。82还是不同
那么有没有一个更好的方法,提供服务调用上的容错机制???
Hystrix诞生了。
Hystrix是干什么的?
自己写伪代码:
前段请求打进来,consumer接收,第一步发起向其中一个provider的请求,假如是发向的是81provider的请求,会先判断链接超时,超时后尝试向其他provider发请求,假如81超时了会记录下来,别的请求也去调用81的时候,就会知道81是超时的,别去调用81了。如果刚才超时后尝试向其他provider发请求还是没成功呢?会catch住异常,给consumer 或者前端 return 一个友好的提示:稍后再来。或者一个好看的友好的页面(重试按钮,联系xx电话邮箱)(这是降级的一种方案)。
降级的第二种就是 return 另外一个东西(假设是写数据库的操作,变成写到mq里)
上面就是Hystrix的降级。
接下来是限流:
还是上面的例子每次consumer给provider发请求都是http请求,http请求每次发的时候都得开一个独立的线程,针对同一服务,可以判断一下请求的线程有多少个,不能因为每次请求超时,导致前面的请求积压。画个图理解一下:目前是provider业务耗时的状况:
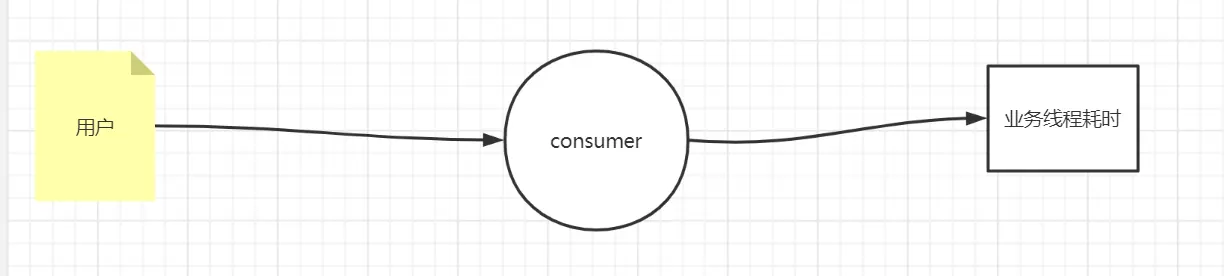
解释一下:淘宝双11了,很多人都买东西,上图的用户就指的是那些很多的人。
假设第一秒有500个用户发请求给consumer,consumer接住了。
这里分为两步:
1、用户和consumer建立连接,是连接线程处理的。
2、consumer在处理这500个用户的请求的时候,是要开业务线程的。这里的业务线程不是单例的,有多少个用户的请求,consumer就应该开500个业务线程,此时500个请求consumer夯住了,开了500个业务线程都去请求provider,provider因为耗时的原因,那500个业务线程都在等待provider的返回结果。
下一秒又有500个用户请求打在了consumer上,consumer照样接住了,又去开500个业务线程去请求provider,这500个也是一样,又是在等待provider给返回结果,因为provider耗时
再下一秒又来500个用户请求。。。consumer又去开500个业务线程。。。不能这样下去,这样合理吗?这样很不合理。不能无限制的开线程的。那应该怎么办呢?
所以应该针对用户请求的每一个资源,每一个url,(假如对user服务,对order服务的请求,每一类请求的url)去开辟独立的请求线程。为什么?因为应用服务器Tomcat在收到http请求后会按照如下流程处理:https://www.dazhuanlan.com/2019/10/17/5da74076504f7/
- 容器负责接收并解析请求为HttpServletRequest。
- 然后交给Servlet进行业务处理。
- 最后通过HttpServletResponse进行响应。
在Servlet 2.0规范中,所有这些处理都是同步进行的,也就是说必须在同一个线程中完成从接收请求、业务处理到结果的响应:
大部分应用都会采用这种同步机制,所有的http请求都共享一个线程池(Tomcat容器线程池)。当其中一个服务变得很慢时(可能是某个DB慢查),将造成服务响应时间变长,大多数线程阻塞等待数据响应返回,最终导致整个Tomcat线程池都被该服务占用,甚至拖垮整个Tomcat。为了提升应用的可用性,我们可以把不同的服务隔离到不同的线程池,当某个服务发生故障时,不会对其它线程池的服务造成影响。
为了实现线程隔离,我们还需要借助Servlet 3.0的异步处理支持:Servlet主线程在解析完请求之后,将耗时的操作委派给另一个线程,然后返还给Tomcat容器,由另一个线程来完成业务逻辑的处理和结果的响应。
有几点需要注意:
1、用户发起请求,查看订单,consumer接收请求,实际上是tomcat接收了请求,然后tomcat 去初始化一个 hystrix,hystrix再根据这个用户的请求,是订单服务,去开一个专门是订单服务的线程池,去限制里面的线程数。假如说这个线程池里初始化了10个线程,当10个线程满了,后面的线程进来就不接收了。这里限制的是发起http请求的线程。为啥要开线程池啊,为了避免请求堆积。
2、当线程池里的线程满了的时候,(后面来的线程都不接了,为的是快速失败)直接throw一个异常,catch一下就回到了给consumer 或者前端 return 一个友好的提示:稍后再来。或者一个好看的友好的页面(重试按钮,联系xx电话邮箱)。这就叫隔离。
下来说熔断:
前面也说了 假如第一次想provider发请求,provide业务超时,所以请求失败。当请求很多次都失败了之后,达到一个阈值的时候count,比如说count=10次,当达到10次以后,后面进来的请求就别调用了,直接进异常。那就throw 一个异常,到了catch return 一个友好页面。这就是熔断
但是直接断了不好吧?当然了,直接断掉不好,熔断就是保险丝,会有开/关/半开 这三种状态,刚才count=10的if判断里,可以new一个随机数 =1,可以发一个请求,还可以按时间,过了几秒之后发一个请求,发一个请求试试,看看是否成功,如果不成功那就接着熔断,如果成了count重置一下,后续线程就会进来了,这就是办开状态。
那么假如有多个consumer微服务,其中consumer1号熔断了,会去通知其他的consumer一块儿熔断吗?
看场景和需求,如果说真的是想provider调不同了,一不通都不通的话,那就consumer1号熔断了,就通知其他的consumer都熔断。
但是在微服务里consumer1号熔断了是不需要通知其他consumer也熔断的,因为没有办法判断consumer1号的熔断是因为什么?更多的不是说后台provider服务500了,假如说是500了,是会快速fix这个500的,下次就不再出现500了。出现熔断的时候一般更多的是因为consumer1号调用provider网络不通,连接超时了导致的熔断,那就跟其他微服务consumer没关系啦。
当然hystrix不是用try,catch实现的,自己写的话可以用aop 把restTemplate包一下,请求前请求后,抛了异常后,进入另一个方法之类的。
如果要更方便的话,可以包装注解。。。。这就是Hystrix。熔断最好的还是在网关层。限流是在服务提供方弄,自己有多大能耐自己应该知道,不要来活就接。
网站声明:如果转载,请联系本站管理员。否则一切后果自行承担。
- 上周热门
- 银河麒麟添加网络打印机时,出现“client-error-not-possible”错误提示 1504
- 银河麒麟打印带有图像的文档时出错 1423
- 银河麒麟添加打印机时,出现“server-error-internal-error” 1213
- 统信操作系统各版本介绍 1134
- 统信桌面专业版【如何查询系统安装时间】 1131
- 统信桌面专业版【全盘安装UOS系统】介绍 1087
- 麒麟系统也能完整体验微信啦! 1043
- 统信【启动盘制作工具】使用介绍 692
- 统信桌面专业版【一个U盘做多个系统启动盘】的方法 635
- 信刻全自动档案蓝光光盘检测一体机 542
- 本周热议
- 我的信创开放社区兼职赚钱历程 40
- 今天你签到了吗? 27
- 信创开放社区邀请他人注册的具体步骤如下 15
- 如何玩转信创开放社区—从小白进阶到专家 15
- 方德桌面操作系统 14
- 我有15积分有什么用? 13
- 用抖音玩法闯信创开放社区——用平台宣传企业产品服务 13
- 如何让你先人一步获得悬赏问题信息?(创作者必看) 12
- 2024中国信创产业发展大会暨中国信息科技创新与应用博览会 9
- 中央国家机关政府采购中心:应当将CPU、操作系统符合安全可靠测评要求纳入采购需求 8
