文档工程体验设计:重塑开发者体验

最近,一边在思考如何进行开发者体验优化,一边在设计新的文档体系,以确保文档和代码的一致性。于是,便结合我先前对于文档代码化的理解和实践,并展开对于 Rust、Julia、Dart、Kotlin、Swift 等语言的文档研究(详细见:《API 库的文档体系支持:主流编程语言的文档设计》),重新思考了如何做了文档工程的开发者体验设计。
本文的面向编写文档的工程师,关注于他们如何能提高自身的开发体验。
文档工程师的痛点
我尝试性的去梳理过去在编写文档的一些痛点,诸如于:
- 文档代码不同步。即文档的 API 变化可能落后于代码,导致 API 与文档出现不一致。
- 频繁的 API 变更。API 变更时,文档需要手动进行更新,不能自动化同步。
- 概念不统一。对于同一个概念,文档的不同地方描述不一致。
- 重复的文档块。文档需要重复引用某一部分的文档,不能像代码一样引用。
- 代码无法运行。按照文档的步骤下来编写的代码、复制的代码,是不能运行的。
还有一些问题,可能是难以通过自动化的方式来解决的,诸如于:
- 风格不一致。不同的人编写文档的风格不一致,可能需要类似于 code review 的 document review 的方式来解决。
- 语法不准确。使用的是不同形式的中文描述方式。(PS:难道是回去再上上语文课)
于是,我们可以尝试性地借用业内一些通用的方式来解决问题。
文档工程体验
再回到标题上,让我对标题做一些解释:
文档工程用于帮助我们指定、设计、和实施计算机技术相关的文档,如产品特定规格或详细说明,以及创建和使用它们的流程。它的特点是以“文档为中心”,以帮助我们构思和理解如何支撑其所在的商业模式。
而文档工程体验设计,则是围绕于构建和设计文档的过程进行的体验改善。即目标用户是编写文档的工程师,改善其编写文档的体验。并针对于文档的目标用户,改善他们在文档方面的体验(PS:这部分不是本文讨论的重点)。
文档体验是开发者体验的一个关键性因素,用于指导新手快速上手技术产品。在我们设计各类开发者体验指标时,一个非常重要的指标就是 TTFHW(Time to first hello world),即从零到第一个 Hello World 需要的时间,而这个指标是严重依赖于开发者文档。
因此,本文的意图是从文档开发者的体验出发,以重新塑造整体的开发者体验。
既然文档工程体验归属于开发者体验,它面向的是开发者提供更好体验,对于自身而言,更需要非凡的体验。只有以此为出发点,才能减小文档团队人员的流 动,毕竟不是程序员想写文档,也不是程序员都想看文档的。
卓越文档工程体验要素
作为一个程序员,我设计和参与过两个文档系统(Ledge 便是其中之一),它们之间有各自不同的思想。再结合我对于多个语言的文档体系的分析和设计,我觉得一个优秀的文档工程应该是满足这样的条件:
- 编辑-发布分离。架构设计上,编辑态和发布是完成分离的,各自可以使用不同的语言和技术来实现,诸如于使用 markdown 编写,但是输出可以是丰富多彩的形式。
- 过程自动化。特别好理解,它应该能实现快速的自动化发布,以代码开发保持一致和构建频繁。
- 文档形式化。XML 是上一个世代比较流行的文档形式化格式,从我的研究情况来看,定制化的 markdown 是这一个世代流行的方式。形式化的输入,它便意味着在输出上会有多种形式,如 markdown 结合 Pandoc 可以转换为 PDF、Word、HTML 等一系列的格式。
- 开放式协作。文档面向使用者开放修改,使用者可以通过 pull request 的形式来对文档进行改进,并可以针对文档提出建议。
- 版本化管理。在编辑态上,所有的历史修改都是可见的,可以回溯所有变更;在发布上,可以看到关键的历史版本,以适应不同人的需求。一种特别简单的示例,就是使用 git 来版本。 对于多数语言、框架的文档系统来说,它们都是面向特定领域定制的,以带来更好的编写体验和一致性。所以,从某种意义上来说,定制化开发也是非常重要的一点 —— 即我们往往难以获得一个通用的解决方案。
面向场景设计呈现
除了上述的要素之后,我们还需要提及一个非常重要的因素,即针对于不同的场景,应该要有不同的文档呈现形式。诸如于:
- 一页文档。诸如于搭建指南,在项目初始化的时候,可以在一个网页内快速完成,而不需要进页面挑战。
- 模块化文档。诸如于面向 API / SDK 场景下,以让每部分 API 都可以独立访问,也能通过搜索引擎优化。
- 可交互文档。诸如于编程语言 REPL、组件库场景下,让用户可以零成本学习和试用技术产品。
- ……
尽管文档很重要,但是请不要忘了,我们的初衷是带来更好的用户体验。
文档模式
为了更方便于讨论,我尝试性对所接触的文章进行了模式上的分类,以及它们所适用的场景:
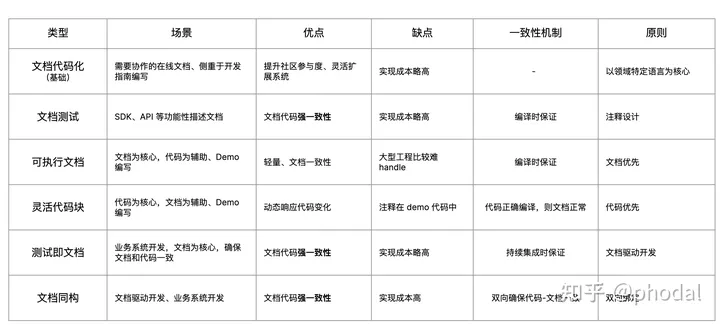
在文档工程这个上下文下,其详细的定义如下。
基础模式:文档代码化
定义:文档代码化是将文档以类代码的领域特定语言的方式编写,并借鉴软件开发的方式(如源码管理、部署)进行管理。 它可以借助于特定的工具进行编辑、预览、查看,又或者是通过专属的系统部署到服务器上。
示例:各类的开源软件文档、Rust、Julia 等编程语言的文档系统
文档代码化其中是现代化的文档工程里的基石。现有的开源软件文档体系,都是以 markdown + 开源的形式而展开的,所有的人都可以在这之上进行协作。除此,基于不同文档的需求,它们会在 DSL 的基础上进行扩展,如新一代的编程语言的文档系统。它们的方式是这样的:
- 为扩展设计:文档 DSL
- 为准确性设计:文档测试
- 构建开放协作平台:开放协作
更详细可以参考:《API 库的文档体系支持:主流编程语言的文档设计》
文档测试:一致性
定义:文档测试的原始定义是,一种测试方式,用于确保系统的文档与系统的功能相匹配。在文档工程的上下文里, 我们定义为针对于文档中的代码验证其有效性,以及其结果的准确性。
示例:Rustdoc、DocumenterTools.jl
如在 Rustdoc 中代码中的注释中的代码会被提取出来,它会被独立编译,确保代码是可运行的。
# Examples
```rust
assert_eq!(2 + 2, 4);
```如下是 Rustdoc 中将上述的代码生成测试代码的测试用例:
#![allow(unused)]
fn main() {
#[allow(non_snake_case)]
fn _doctest_main__some_unique_name() {
assert_eq!(2 + 2, 4);
}
_doctest_main__some_unique_name()
}
一旦上述的代码编译并运行通过,则说明文档中的注释是正确的。具体的步骤如下:
- 解析 markdown,寻找 Rust 语言的语法块(如果没有标注语言类型,默认是 Rust)
- 根据语法块,做一些简单的处理,生成可编译的代码
- 编译上述的测试代码 (如果编译失败,则说明测试失败)
- 运行这些测试 or 文档
详细见 Rustdoc 相关源码:librustdoc
可执行文档
定义:可执行文档是指文档本身已经是代码化的结果,它像代码一样可以执行, 并且可以将结果动态地与文档结合在一起。
示例:Julia 的 DocumenterTools、R Markdown、Exemd
在 R Markdown 里,它可以结合文档与 R 语言源码,可以进行动态的渲染。我们可以在 markdown 文件中,“随意”地调用 R 中的函数,并动态地嵌入数据、代码、计算结果、可视化图表等到输出的文档中。在结合了 Pandoc 之后,文档可以输出到所有主流的文档格式。如下的示例:
```
{r fig.show='animate', dev='jpeg', ffmpeg.format='gif'}
for (i in 1:10) plot(runif(100), ylim = c(0, 1)) # for example
```它将会运行并在文档中嵌入运行的结果。
灵活代码块
定义:灵活代码块是指文档可以通过 DSL 动态引用源码中的内容。
示例:DocumenterTools.jl、Forming 里的 Writing
以我设计的 Writing 为例,它可以动态解析 markdown 中设计的 Writing DSL,并从代码中读取对应的代码块。如下是 Writing 的示例:
// doc-code: file("src/lib.rs").line()[2, 5]
// 读取 "src/lib.rs" 文件的第 2 到第 5 行
// doc-section: file("src/lib.rs").section("section1")
// 读取 "src/lib.rs" 文件中的 section1 相关的代码块通过简单的自定义函数,将文档与代码有机结合到一起。只要应用编译运行成功,那么文档本身也是正确的。
测试即文档
定义:测试即文档即指测试用例以文档的形式编写,文档本身就是测试用例。
示例:Cucumber
相信大家都很“熟悉”了,主要是在自动化测试中使用非常广泛。Cucumber 示例如下:
# language: zh-CN
@math
功能: 加法
加法计算器的验证用例
@sanity
场景: 两个数相加
假如我已经在计算器里输入6
而且我已经在计算器里输入7
当我按"相加"按钮
那么我应该在屏幕上看到的结果是13测试是文档,文档即是测试。
文档同构(概念)
文档同构。文档同构 是一种将代码与文档保持一致的技术理念,它能读取格式化的文档,并将文档自动加入到代码中,如以注释的形式或者是只在 IDE 呈现;同时,还能将读取代码中的文档,自动更新到文档中,或是对文档进行测试和差异对比。
PS:我正在设计的一种方式,暂时没有 DEMO。
体验设计
最后,进行最后一个不愉快地话题,讨论一下如何优化这方面的指标。实际上,我并没有任何相关的经验。只是呢,我试想了一下,开发者体验相关的体系,修改一下,理论上也可以在这里适用。
度量驱动
文档的度量本质上还可以使用开发者相关的指标进行度量,诸如于:
- TTFHW,Time to first hello world 所花费的时间,是否存在改善。
- PR 数 & Issue 数,适用于开源项目相关的文档,指在完善文档。随着文档的成熟,相关的内容应该越来越少。
从 API 相关的用户体验来说,它还可以是:
- API 占比覆盖率。即通过文档测试等的方式,可以知道是否所有的 API 都有文档覆盖。
- SEO 指标。即当开发人员从搜索引擎搜索时,是否能被搜索到?以及它在搜索引擎的排位?避免被乌龙。
还有一些不是那么易于衡量的:
- 美观。这个很重要吗??大概是吧
- 易用性。这个怎么用指标衡量?
不过呢,线上的文档作为一个网站 ,常规的 Web 应用的指标也是适用的:文档访问速度等。
优化开发者体验
为了这个文档的概念完整性,我复制/粘贴了一些我司关于开发者体验优化相关的步骤:
- 定义价值度量维度
- 匹配用户旅程,细化维度至可量化的指标
- 建立体验度量体系
- 度量与诊断
- 分析与体验提升
- 构建体验管理机制
从模式上来说,它和用户体验是极为相似的,同样的也是出于指标度量的维度来考虑问题的。
网站声明:如果转载,请联系本站管理员。否则一切后果自行承担。
- 上周热门
- 银河麒麟添加网络打印机时,出现“client-error-not-possible”错误提示 1514
- 银河麒麟打印带有图像的文档时出错 1434
- 银河麒麟添加打印机时,出现“server-error-internal-error” 1226
- 统信操作系统各版本介绍 1145
- 统信桌面专业版【如何查询系统安装时间】 1141
- 统信桌面专业版【全盘安装UOS系统】介绍 1099
- 麒麟系统也能完整体验微信啦! 1053
- 统信【启动盘制作工具】使用介绍 705
- 统信桌面专业版【一个U盘做多个系统启动盘】的方法 648
- 信刻全自动档案蓝光光盘检测一体机 551
- 本周热议
- 我的信创开放社区兼职赚钱历程 40
- 今天你签到了吗? 27
- 如何玩转信创开放社区—从小白进阶到专家 15
- 信创开放社区邀请他人注册的具体步骤如下 15
- 方德桌面操作系统 14
- 我有15积分有什么用? 13
- 用抖音玩法闯信创开放社区——用平台宣传企业产品服务 13
- 如何让你先人一步获得悬赏问题信息?(创作者必看) 12
- 2024中国信创产业发展大会暨中国信息科技创新与应用博览会 9
- 中央国家机关政府采购中心:应当将CPU、操作系统符合安全可靠测评要求纳入采购需求 8
