申威最新芯片曝光,最强超算同步亮相

计算能力已成为重要的国家资源。自从第一台通用计算机 ENIAC 用于计算火炮和炸弹弹道学以来,计算应用程序呈爆炸式增长。如今,工程师在使用资源密集型验证技术(例如在风洞中构建比例模型)之前,使用计算机模拟来廉价地评估设计。科学家在实验室测试之前模拟蛋白质相互作用以找到有前景的药物配方。政府机构使用超级计算机来预测天气和气候模式。一个拥有充足计算能力的国家可以更有效地利用其人力和物力资本来实现其政策目标。
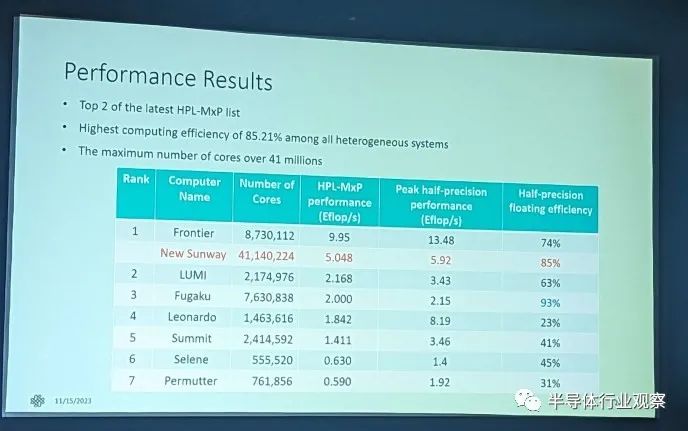
中国清楚地意识到这一点,超级计算机的发展是其国家优先事项之一。在中国本土超级计算机领域处于领先地位。在 Supercomputing 23 上,申威展示了他们的 SW20610-Pro 处理器,该处理器的历史可以追溯到 2020 年底至 2021 年初。它是神威太湖之光中 SW20610 的改进版本。目前,太湖之光在最强超级计算机 TOP500 排行榜上排名第 11 位。新的Sunway超级计算机看起来排名第二,仅次于美国橡树岭国家实验室的新Frontier超级计算机。
为此,Sunway 迭代了几乎完全专注于计算密度的设计。SW20610-Pro 采用了 SW20610 的基本架构,并对其进行了扩展,同时实现了片外连接的现代化。
芯片级
Sunway 的 SW20610-Pro 是一款多核处理器,分为多个核心集群,称为核心组或 CG。(核心组,或 CG)。CG 由 4×4 网格上的 64 个计算处理元件 (CPE) 组成,其中四个 CPE 共享每个网格站点。称为管理处理元件 (MPE) 的管理处理器负责处理通信并在 CPE 上生成线程。
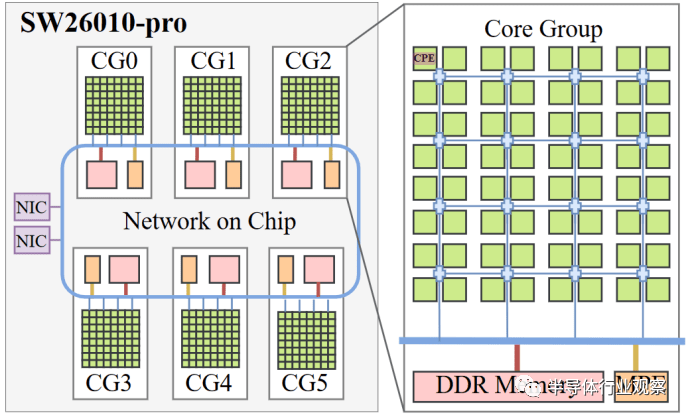
Sunway 没有集群或系统级缓存。SW20610-Pro 的芯片级组织与之前的 SW20610 相同,但具有六个集群而不是四个。

每个集群都有自己的内存控制器。在 SW20610-Pro 中,该控制器已升级为 DDR4 控制器,与上一代 DDR3 设置相比,可提供更高的带宽。从 Sunway 提供的数据来看,每个集群很可能采用双通道 DDR4-3200 设置。在所有六个集群中,Sunway 的 SW20610-Pro 的理论带宽为 307.2 GB/s。内存容量也得到了升级。SW20610-Pro 的集群每个1配备 16 GB DDR4 ,而 SW20610 则配备 8 GB DDR3。一块芯片总共可以访问 96 GB 的主存储器。与 SW26010 的 32 GB 相比,这是一个显着的升级。

Sunway的架构与富士通的A64FX有相似之处。这两款芯片都提供非统一内存访问,每个核心集群都显示为 NUMA 节点。他们还为每个集群使用专用的管理核心。A64FX 的集群具有较少的核心,但具有在集群中的所有核心之间共享的 8 MB L2 缓存。A64FX 上的 L2 缓存可以维持 3.6 TB/s 2,而 HBM2 控制器可以以 1 TB/s 的总带宽处理 L2 缺失。
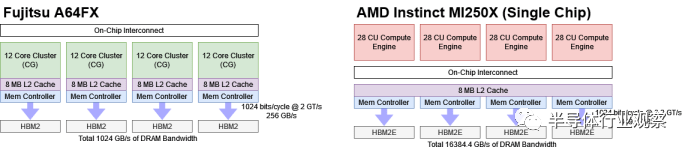
在Sunway的性能结果图表中,他们的新超级计算机被美国的Frontier和芬兰的LUMI包围。两者都利用 AMD 的 CDNA 2 架构和 MI250X GPU,因此该架构也将是一个有用的比较。CDNA 2 将计算单元 (CU) 组织成组,但每个组都享有对 GPU 整个 64 GB 内存池的统一内存访问。管理功能由附加的基于 Zen 3 的 Epyc CPU 执行,该 CPU 可以向 GPU 提交命令。GPU 上的四个异步计算引擎 (ACE) 然后在着色器阵列上启动线程或波前。如果 CDNA 2 像 GCN 一样工作,每个 ACE 每个周期可以发射一个波前。
MI250X 芯片上的所有 112 个计算单元共享一个 8 MB L2 缓存,能够提供约 3.7 TB/s 的速度。L2 未命中由理论带宽为 1.6 TB/s 的 HBM2E 设置处理。
管理核心
SW26010中的CPE只能运行在用户模式并且不支持中断3。这会阻止它们运行操作系统,因此 Sunway 的 MPE 负责启动线程和处理通信。MPE可以在不同的权限级别运行代码并支持中断。由于管理代码不像计算内核那样规则,因此 MPE 具有无序执行和基本的缓存层次结构。
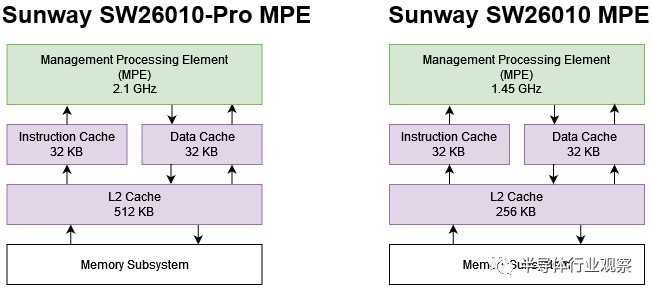
SW26010-Pro 的 MPE 拥有更大的 L2 缓存和更高的时钟速度。我想知道Sunway的新芯片是否将MPE置于与CPE不同的时钟域上。SW26010 以 1.45 GHz 运行 CPE 和 MPE。
SW26010的MPE有两个256位浮点管道。较新的 MPE 可能至少具有同样多的吞吐量。MPE 性能并不是很重要,因为它只需足够快即可将工作分配给 CPE 并将数据传递给 NIC 以进行跨节点通信。
计算架构
Sunway 的 CPE 是小型轻量级核心,专注于以最小的功耗和面积实现最大的矢量吞吐量。较旧的 SW26010 CPE 具有双管道设置,具有部分乱序执行。具体来说,浮点和内存操作是按顺序发出的,但两个管道可以彼此乱序发出指令。基本浮点运算的执行延迟很高,为 7 个周期。我假设这些参数在 SW26010-Pro 中没有变化。

我们确实知道,Sunway 将指令缓存容量增加到了 32 KB。Sunway 使用 RISC 指令,长度可能为 16 字节。因此,16 KB 指令缓存的容量小于最新 x86 CPU 上的微操作缓存。将指令缓存容量加倍是一个很好的举措。
每次迭代通常有 1000 条指令/操作适合 16 KB CPE I-Cache
SW26010 众核处理器基准测试
Sunway 还将向量执行宽度加倍至 512 位。时钟速度从 1.45 GHz 增加到 2.25 GHz,使新 Sunway 的每 CPE 性能大幅提高。
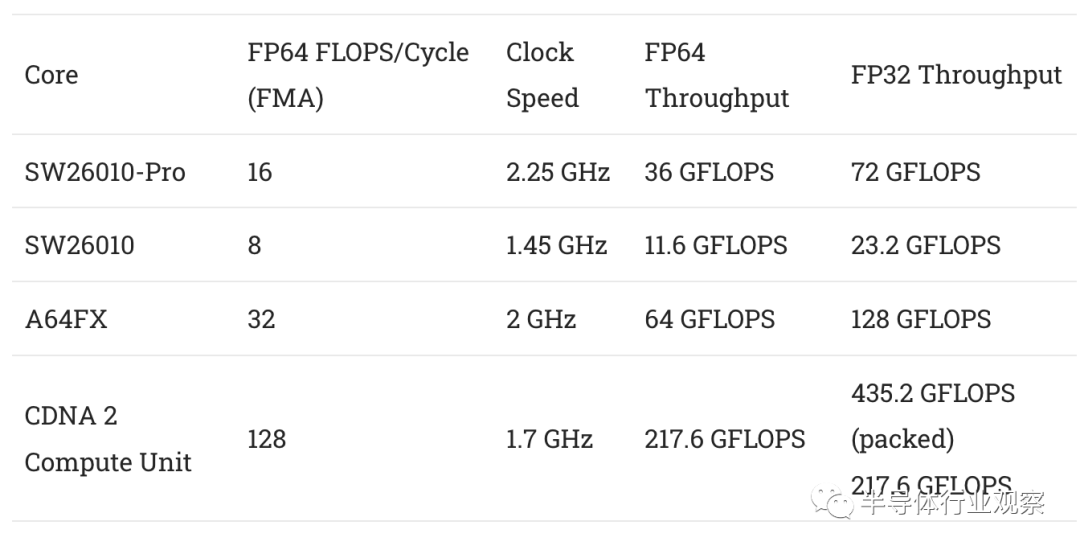
在整个芯片上,SW26010-Pro 的计算吞吐量是其前身的四倍多。这来自更多内核、更高时钟速度和更宽矢量宽度的组合。
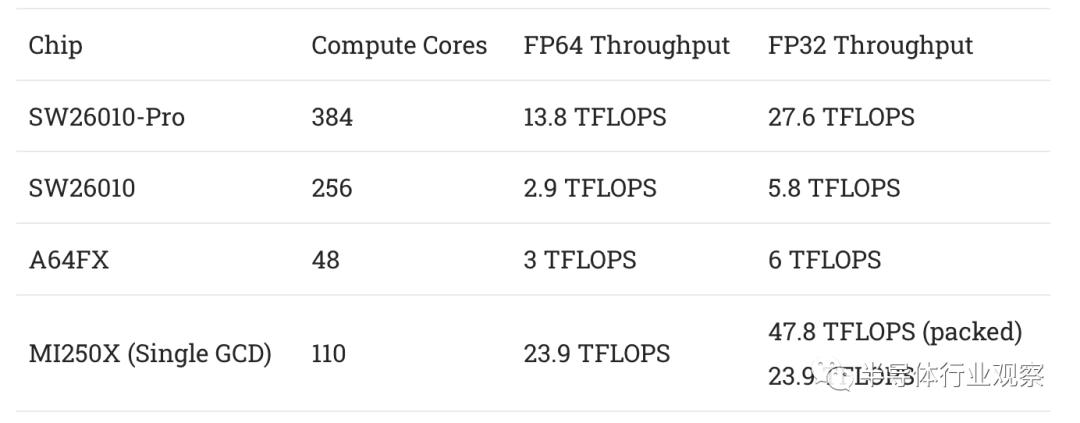
理论上,SW26010-Pro 提供比富士通 A64FX 更多的计算吞吐量。但拥有大量广泛的执行单元是一回事。回馈(Feeding )它们是另一回事。
缓存和内存访问
Sunway 的 SW26010 的 CPE 缺乏数据缓存层次结构。就像索尼的 Cell 处理器一样,每个 CPE 都有一个 64 KB 软件管理的暂存器,具有 4 个周期的访问延迟和每个周期 32 字节的带宽。如果暂存器无法容纳数据,CPE 必须通过 DMA 命令访问系统内存。64 KB 的存储量小得可笑,而且缺乏适当的缓存层次结构意味着 Sunway SW26010 受到内存带宽的严重瓶颈。
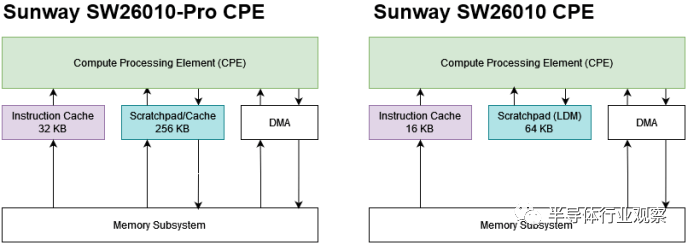
为了解决内存带宽问题,SW26010-Pro 将暂存器容量增加到 256 KB。多达一半的暂存器可以配置为缓存,与 Nvidia 的 GPU 类似。256 KB 的本地存储优于 64 KB,而且基本缓存也比没有好。但与任何其他现代设计相比,SW26010-Pro 的内存限制仍然非常严重。
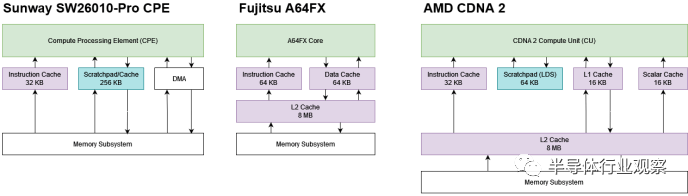
Fujitsu 的 A64FX 具有小型核心专用 64 KB L1 缓存,并由 8 MB 集群范围 L2 提供支持。AMD 的 CDNA 2 架构具有软件管理的暂存器和小型 16 KB L1 缓存。然后,芯片上的所有计算单元共享 8 MB L2。在这两种情况下,大型多兆字节 L2 缓存都有助于减少主内存的带宽需求。SW26010-Pro缺少这样的缓存。
DRAM 配置:不适合用途
HPC 工作负载对内存带宽有很高的要求。zhigeng Xu、James Lin 和 Satoshi Matsuoka 的一篇论文指出,大多数计算内核在访问的每个内存字节上执行 16 次或更少的浮点运算。该论文将 SW26010 描述为极度受内存限制。
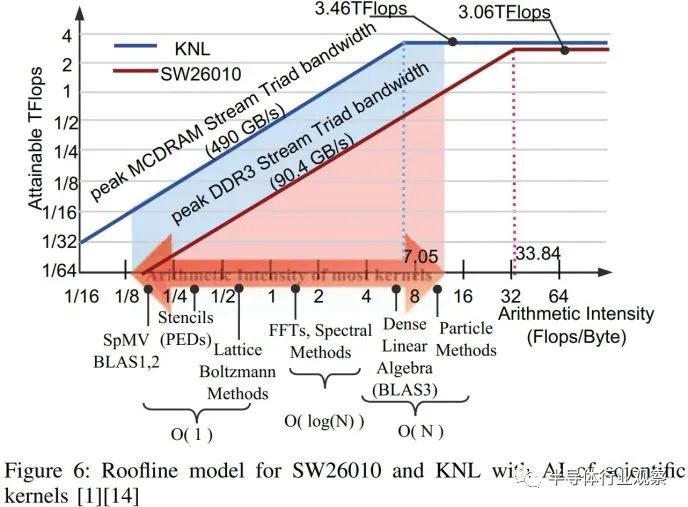
如果我们通过内存带宽来计算吞吐量比,旧版 SW26010 的处境就很糟糕。富士通的 A64FX 和英特尔的 Xeon Phi 等更具可比性的多核超级计算机芯片的每浮点运算内存带宽要高得多。AMD 的 MI250X 和 Nvidia 的 H100 等计算 GPU 在为其执行单元提供数据时可能会遇到更多麻烦,但这只是因为它们正在突破内存技术的极限。
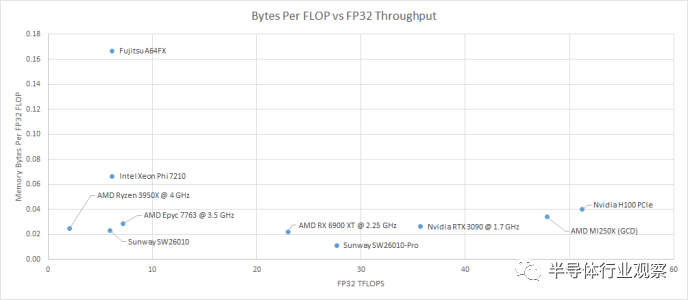
SW26010-Pro 提高了计算吞吐量,而无需相应升级内存带宽。具体来说,每个集群都从 128 位 DDR3-2133 设置迁移到 DDR4-3200 设置。从几个层面来说,这都是一个糟糕的笑话。首先,它为 SW26010-Pro 每 FP32 FLOP 提供 0.11 字节。这是 RX 6900 XT 带宽计算比的一半。6900 XT 是一款消费级 GPU,旨在采用低成本内存设置。不知何故,Sunway 认为拥有比 RX 6900 XT 更多的计算能力但内存带宽更少,并且没有使设置可行的 128 MB 末级缓存会很有趣。
更糟糕的是,连接到每个 SW26010-Pro 核心集群的双通道 DDR4-3200 设置是您在上一代台式机上找到的。
组网配置
在超级计算机中,重要的不仅仅是单个芯片,而是所有芯片如何相互通信。
高速通信使超级计算机有别于一堆服务器。在超级计算机上,研究人员可以将问题分散到多台机器(节点)上,并使用高速网络交换数据。一个薄弱的数据中心以太网可能在服务器之间提供 40 或 100 Gbps(5 到 12.5 GB/秒)。超级计算机网络提供了一个数量级的带宽。

Sunway 的 SW26010-Pro 在纸面上具有不错的网络性能。与我们查看内存带宽时相比,它更接近 Fugaku 和 Frontier。然而,实现该带宽很困难。网络控制器必须从主内存中获取数据,Sunway 糟糕的内存子系统再次出现问题。
优化 HPL-MxP 的研究人员最初为每个集群运行一个 MPI 进程。然后,每个进程将主要与本地内存控制器一起工作,从而最大限度地提高内存性能。但是,您希望将计算与网络传输重叠。每个 SW26010-Pro 集群只有 51.2 GB/s 的带宽。计算和网络活动争夺内存带宽。MPE 的缓存不够大,管理代码最终会进一步占用有限的带宽。结果是网络利用率低下。

Rongfen Lin 等人通过使用单个 MPI 进程克服了这个问题,将每个块划分为 512B 子块,并将这些子块分布在 NUMA 节点上,以实现伪分布式模式。这将计算和网络带宽需求分散到 SW26010-Pro 的 307 GB/s 总带宽中,从而消除了分区露营问题。
我不知道这种优化花了多少时间来编码和测试,但我无法想象它是微不足道的。我也无法想象 Fugaku 或 Frontier 上有必要进行这样的优化工作。Fugaku 每个分区的带宽为 256 GB/s,足以为网络接口提供备用带宽。在 Frontier 上,当单个 MI250X GCD 具有 1.6 TB/s 带宽时,100 GB/s 网络带宽是一个舍入误差。因此,Sunway的内存带宽问题会蔓延到跨节点通信,并且需要比其他系统更多的优化工作。
连接超级计算机
为节点提供高网络带宽是构建超级计算机的第一步。接下来是让所有节点以尽可能多的带宽相互通信。为此,神威保留了太湖之光的总体组织架构。申威的新超级计算机共有 41,140,224 个 CPE,即 107,136 个芯片。

每个芯片都是一个具有自己的网络连接的节点。其中 256 个节点连接到快速交换机,级别称为超级节点。双威表示,第一级连接提供“畅通的网络带宽”。每个超级节点连接到具有 48 个端口的跨超级计算机互连。
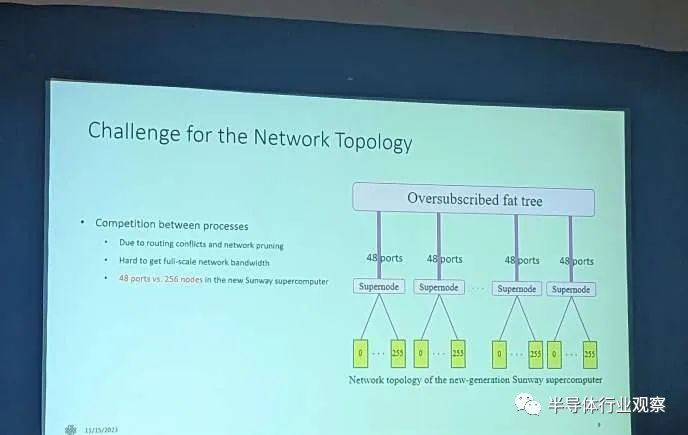
每个超级节点通过 48 条链路连接到中央交换网络。我们不知道中央交换网络的链路带宽或拓扑。如果我们假设所有叶子交换机端口都具有相同的 56.25 GB/s,则每个超级节点将具有 2.7 TB/s 上行链路。

神威·太湖之光的网络平分带宽显然为 70 TB/s,网络直径为 7 4,这表明超级节点并不享有与其他超级节点平等、畅通的带宽。太湖之光的其余拓扑结构与神威新型超级计算机的拓扑结构非常相似。这是一棵三层树。因此,Sunway 使用与 Summit 等较旧的超级计算机类似的网络拓扑。
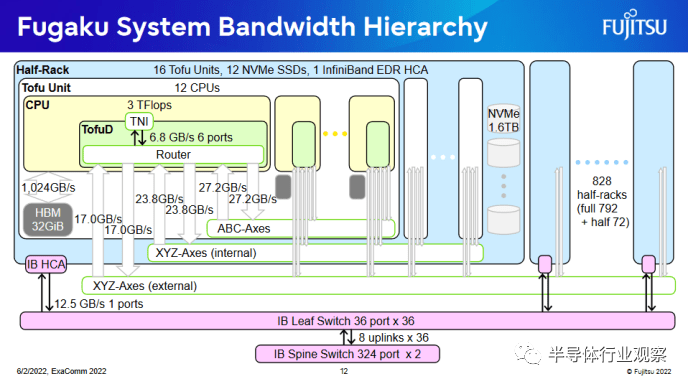
RIKEN 的 Fugaku 采用了更复杂的 6D 环面拓扑方法。每个节点的带宽分为六个端口。成对的端口连接到不同的交换机级别。随着组织中节点的距离越来越远,带宽逐渐减少。
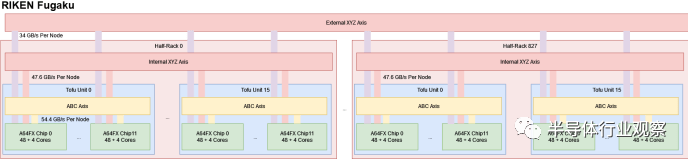
Fugaku 可以为每个节点提供 34 GB/s 直至最高级别轴。相比之下,Sunway 的新型超级计算机中的每个节点均可获得 10.54 GB/s 的全球互连速度。如果超级节点中只有少数节点进行通信,Sunway 可以为系统的其余部分提供更高的每节点带宽。但是,如果一个大问题需要超过 256 个节点,您可能希望将它们放在尽可能少的超级节点中,以利用高超级节点内带宽。因此,Fugaku 为每个节点提供的全球互连带宽是 Sunway 的三倍多。大问题应该更容易在 Fugaku 上扩展。
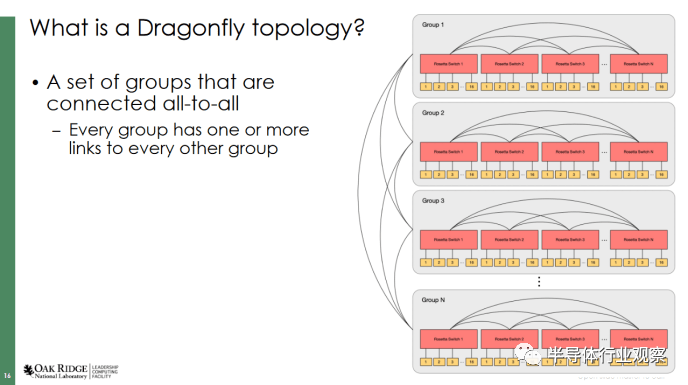
ORNL 的 Frontier 使用三跳蜻蜓拓扑,其中每一层的交换机组都完全连接。我无法找到有关每个交换机有多少上行链路带宽的信息。
最后的话
从理论计算吞吐量的角度来看,Sunway 的新型超级计算机令人印象深刻。SW26010-Pro在节点级别与Fugaku的A64FX最相似,中国的超级计算机在使用更少的芯片的同时提供了比日本更高的FP64吞吐量。然而,它是通过几乎单一地关注将尽可能多的执行能力装入每个芯片来实现的。
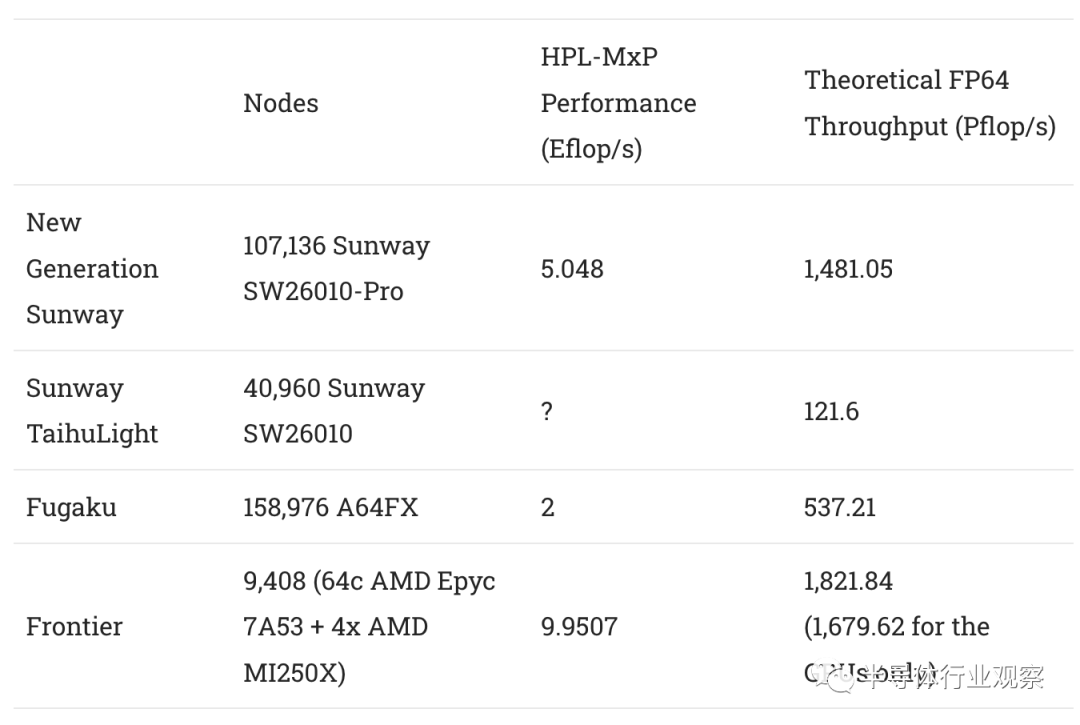
SW26010-Pro 芯片具有许多宽向量执行单元,但对它们的支持很少。CPE 无法利用线程级并行性,并且利用指令级并行性的能力非常有限。内存设置非常弱。结果是芯片需要编译器或程序员进行大量优化工作。
然后我们还有内存带宽问题。在 64 CPE SW26010-Pro 集群上放置双通道 DDR4-3200 设置是不可接受的。尽管该系统可以追溯到 2020 年至 2021 年时代,但这种内存设置相当糟糕。在相同的内存带宽下,计算能力是当代旗舰消费级 CPU (Ryzen 9 3950X) 的 10 倍以上,这要求您的系统在许多任务中受到严重的内存限制。转向当时全新的 DDR5 内存标准仍然会受到系统内存的限制。但考虑到 Sunway 的带宽限制,从 DDR5-4800 增加 50% 的带宽就可以将性能提高近乎同样的程度。为了真正缓解这些问题,SW26010-Pro 应该拥有更好的缓存层次结构和 HBM 设置,同时减少执行单元的数量。
因此,Sunway 的新型超级计算机给人的感觉就像是一个旨在跻身 TOP500 榜单前列的系统。就这个目的而言,它是完美的,可以提供大量吞吐量,而无需在缓存、乱序执行和高带宽内存等烦人的事情上浪费金钱。但从解决国家问题的角度来看,我觉得申威是在追求一个指标。一个在先进技术方面表现出色的国家可能拥有大量的超级计算机吞吐量,但更多的超级计算机吞吐量并不一定意味着你能更快地解决技术问题。
在文章开头,我指出超级计算机的建立是为了让一个国家更有效地利用其人力和物力来实现政策目标。在优化时间上使用人力资源存在机会成本问题。我不确定 Rongfen Lin 等人花了多长时间在节点的内存分区上手动交错 HPL-MxP 矩阵,但在 Fugaku 或 Frontier 上不需要这项任务。从某种意义上说,我对将代码与硬件紧密配合所需的辛勤工作和英勇的编程努力表示赞赏。
另一方面,需要复杂的优化工作才能达到可接受的性能的硬件并不是好硬件。像 Fugaku 或 Frontier 这样的系统不需要那么多的优化工作。A64FX 上的乱序执行使其核心动态地提出接近最佳的指令调度。Frontier 的 MI250X GPU 可以通过利用线程级并行性在另一个维度上做到这一点。在这两种情况下,简单编写的代码可能表现得足够好,让研究人员能够继续解释结果,而不是浪费数周时间迭代代码。而且这是假设它们不会遇到 Sunway 固有的带宽限制。
人类建造强大的计算机不是为了建造强大的计算机,而是为了让它们更快地解决问题。从超级计算机的角度来看,计算领域已经进行了大量的开发,以使计算机解决问题变得更加容易。乱序执行使程序员无需手动指令调度即可获得更好的性能。虚拟内存允许用户同时运行多个程序,而不必担心一个行为不当的程序会导致整个系统崩溃。如果我们转向软件,编译器可以让程序员组织复杂的程序,而不必跟踪哪些变量存储在哪些寄存器中。C# 或 Java 等垃圾收集语言让开发人员可以牺牲一些性能来换取更轻松的编码。
更高的计算性能具有相同的目标。更强的计算能力让人们可以使用更简单的强力算法。但高性能系统不能仅拥有高纸面计算能力。我希望神申威未来的系统能够采取更加平衡的方法,即使以牺牲一些峰值吞吐量为代价,也能提供更容易获得的计算能力。
来源微信公众号:内容由半导体行业观察(ID:icbank)编译自chipsandcheese,谢谢。
原文链接
https://chipsandcheese.com/2023/11/20/chinas-newish-sw26010-pro-supercomputer-at-sc23/
网站声明:如果转载,请联系本站管理员。否则一切后果自行承担。
- 上周热门
- 如何使用 StarRocks 管理和优化数据湖中的数据? 2987
- 【软件正版化】软件正版化工作要点 2906
- 统信UOS试玩黑神话:悟空 2881
- 信刻光盘安全隔离与信息交换系统 2764
- 镜舟科技与中启乘数科技达成战略合作,共筑数据服务新生态 1297
- grub引导程序无法找到指定设备和分区 1270
- 华为全联接大会2024丨软通动力分论坛精彩议程抢先看! 172
- 2024海洋能源产业融合发展论坛暨博览会同期活动-海洋能源与数字化智能化论坛成功举办 170
- 点击报名 | 京东2025校招进校行程预告 166
- 华为纯血鸿蒙正式版9月底见!但Mate 70的内情还得接着挖... 164
- 本周热议
- 我的信创开放社区兼职赚钱历程 40
- 今天你签到了吗? 27
- 信创开放社区邀请他人注册的具体步骤如下 15
- 如何玩转信创开放社区—从小白进阶到专家 15
- 方德桌面操作系统 14
- 我有15积分有什么用? 13
- 用抖音玩法闯信创开放社区——用平台宣传企业产品服务 13
- 如何让你先人一步获得悬赏问题信息?(创作者必看) 12
- 2024中国信创产业发展大会暨中国信息科技创新与应用博览会 9
- 中央国家机关政府采购中心:应当将CPU、操作系统符合安全可靠测评要求纳入采购需求 8
