英伟达H200突然发布:容量翻倍,带宽狂飙

在今年的S23大会上,NVIDIA 突然宣布推出了 NVIDIA HGX H200,为全球领先的 AI 计算平台带来强大动力。据介绍,该平台基于 NVIDIA Hopper 架构,配备 NVIDIA H200 Tensor Core GPU 和高级内存,可处理生成 AI 和高性能计算工作负载的海量数据。
英伟达指出,NVIDIA H200 是首款提供 HBM3e 的 GPU,作为一种更快、更大的内存,HBM3e可加速生成式 AI 和大型语言模型,同时能推进 HPC 工作负载的科学计算。借助 HBM3e,NVIDIA H200 能以每秒 4.8 TB 的速度提供 141GB 内存,与前前一代的NVIDIA A100 相比,容量几乎翻倍,带宽增加 2.4 倍。

HGX H200 由 NVIDIA NVLink 和 NVSwitch 高速互连提供支持,可为各种应用工作负载提供最高性能,包括针对超过 1750 亿个参数的最大模型的 LLM 训练和推理。英伟达表示,在不断发展的人工智能领域,企业依靠LLM来满足各种推理需求。当为大量用户群大规模部署时,人工智能推理加速器必须以最低的 TCO 提供最高的吞吐量。
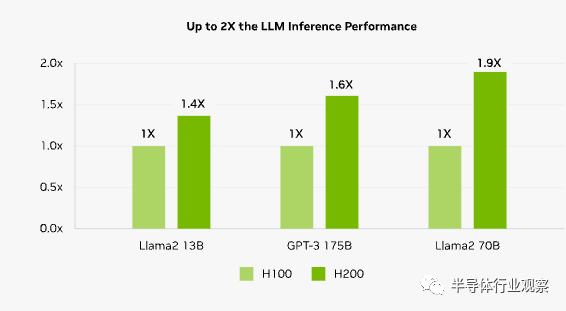
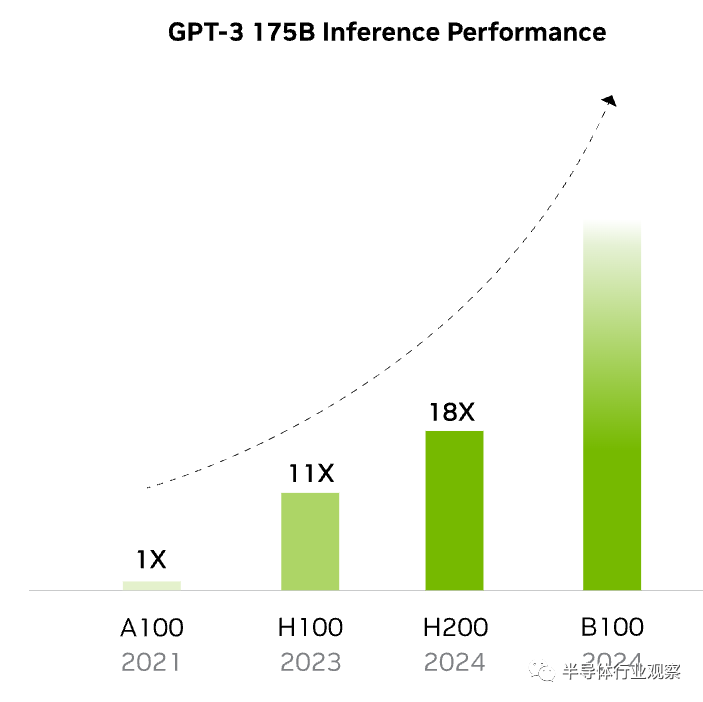
在处理 Llama2 (一个 700 亿参数的 LLM)等 LLM 时,H200 的推理速度比 H100 GPU 提高了 2 倍。
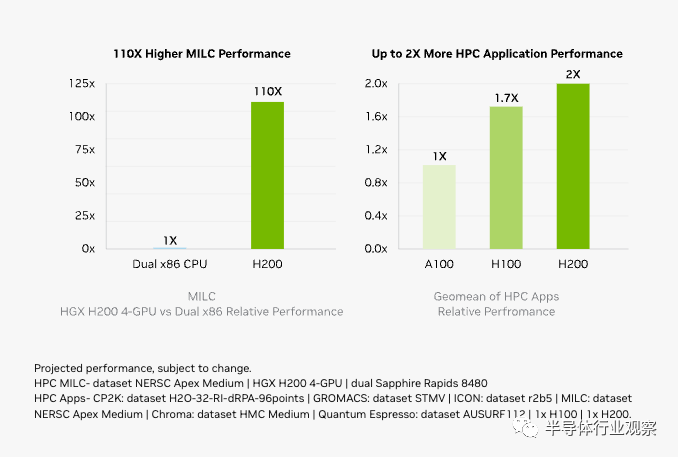
英伟达进一步指出,内存带宽对于 HPC 应用程序至关重要,因为它可以实现更快的数据传输,减少复杂的处理瓶颈。对于模拟、科学研究和人工智能等内存密集型 HPC 应用,H200 更高的内存带宽可确保高效地访问和操作数据,与 CPU 相比,获得结果的时间最多可加快 110 倍。
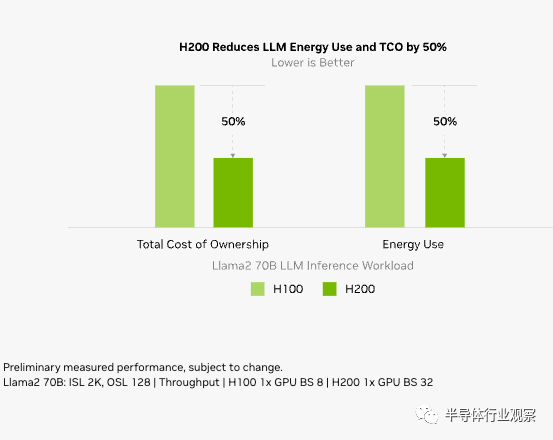
随着 H200 的推出,能源效率和 TCO 达到了新的水平。这项尖端技术提供了无与伦比的性能,且功率配置与 H100 相同。人工智能工厂和超级计算系统不仅速度更快,而且更环保,提供了推动人工智能和科学界向前发展的经济优势。
NVIDIA H200 将应用于具有四路和八路配置的 NVIDIA HGX H200 服务器主板,这些主板与 HGX H100 系统的硬件和软件兼容。它还可用于8 月份发布的采用 HBM3e 的 NVIDIA GH200 Grace Hopper superichip。
据介绍,八路 HGX H200 提供超过 32 petaflops 的 FP8 深度学习计算和 1.1TB 聚合高带宽内存,可在生成式 AI 和 HPC 应用中实现最高性能。
英伟达表示,H200 可以部署在各种类型的数据中心中,包括本地、云、混合云和边缘。NVIDIA 的全球生态系统合作伙伴服务器制造商(包括华擎 Rack、华硕、戴尔科技、Eviden、技嘉、惠普企业、英格拉科技、联想、QCT、Supermicro、纬创资通和纬颖科技)可以使用 H200 更新其现有系统。
而除了CoreWeave、Lambda和 Vultr 之外,亚马逊网络服务、谷歌云、微软 Azure 和甲骨文云基础设施将从明年开始成为首批部署基于 H200 实例的云服务提供商。
HBM3e,H200的升级重点
随着速度更快、容量更大的 HBM3E 内存将于 2024 年初上线,NVIDIA 一直在准备其当前一代服务器 GPU 产品以使用新内存。早在 8 月份,我们就看到 NVIDIA 计划发布配备 HBM3E 的 Grace Hopper GH200 超级芯片版本。这次NVIDIA 宣布的H200,其实就是配备 HBM3E 内存的独立 H100 加速器的更新版本。
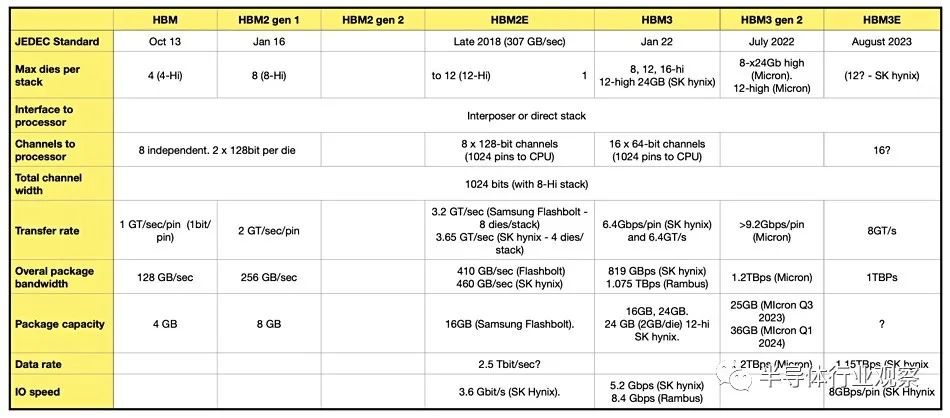
据SK海力士介绍,HBM3E不仅满足了用于AI的存储器必备的速度规格,也在发热控制和客户使用便利性等所有方面都达到了全球最高水平。在速度方面,其最高每秒可以处理1.15TB(太字节)的数据。其相当于在1秒内可处理230部全高清(Full-HD,FHD)级电影(5千兆字节,5GB)。值得一提的是,美光在七月还宣布推出超过 1.2TBps HBM3 gen 2 产品,这表明 SK 海力士还有很多追随的工作要做。
与 Grace Hopper 的同类产品一样,H200 的目的是通过推出具有更快和更高容量内存芯片版本,作为 Hx00 产品线的中期升级。利用美光和其他公司即将推出的HBM3E 内存,NVIDIA 将能够提供在内存带宽受限的工作负载中具有更好的实际性能的加速器,而且还能够提供能够处理更大工作负载的部件。这对于生成式AI 领域尤其有帮助——迄今为止,该领域几乎推动了对 H100 加速器的所有需求——因为最大的大型语言模型可以最大程度地支持 80GB H100。
与此同时,由于 HBM3E 内存要到明年才能发货,NVIDIA 一直在利用这个间隙发布 HBM3E 更新部件。继今年夏天发布 GH200 后,NVIDIA 宣布采用 HBM3E 的 Hx00 加速器独立版本只是时间问题,现在H200终于到来。
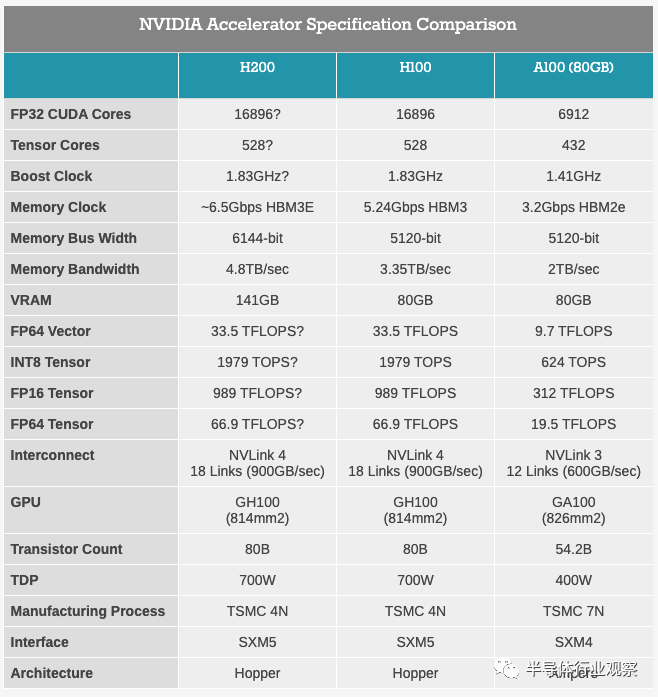
从今天披露的规格来看,H200 基本上看起来就像是 GH200 的 Hopper 一半,作为自己的加速器。当然,这里最大的区别是将 HBM3 替换为 HBM3E,这使得 NVIDIA 能够提高内存带宽和容量,并且 NVIDIA 启用了第 6 个HBM内存堆栈,该堆栈在原始 H100 中被禁用。这将使 H200 的内存带宽从 80GB 提升至 141GB,内存带宽从 3.35TB/秒提升至 NVIDIA 初步预期的 4.8TB/秒。
根据总带宽和内存总线宽度向后推算,这表明 H200 的内存将以大约 6.5Gbps/引脚运行,与原始 H100 的 5.3Gbps/引脚 HBM3 内存相比,频率增加了大约 25%。这实际上远低于 HBM3E 额定的内存频率(美光希望达到 9.2Gbps/pin),但由于它正在针对现有 GPU 设计进行改造,因此看到 NVIDIA 当前的内存控制器没有相同的内存频率范围也就不足为奇了。
H200还将保留GH200不同寻常的141GB内存容量。HBM3E 内存本身的物理容量为 144GB(以六个 24GB 堆栈的形式出现),但 NVIDIA 出于产量原因保留了部分容量。因此,客户无法访问板载的所有 144GB,但与 H100 相比,他们可以访问所有六个堆栈,并具有容量和内存带宽优势。
正如我们之前所说,运送具有全部 6 个工作堆栈的部件基本上需要完美的芯片,因为 H100 的规格非常慷慨地允许 NVIDIA 运送具有非功能堆栈的部件。因此,与同类 H100 加速器(已经供不应求)相比,这可能是体积较小、良率更低的部件。
除此之外,到目前为止,NVIDIA 尚未透露任何信息表明 H200 将比其前身具有更好的原始计算吞吐量。虽然内存变化应该会提高实际性能,但 NVIDIA 为 HGX H200 集群引用的 32 PFLOPS FP8 性能与当今市场上的 HGX H100 集群相同。
不过据anadtech分析,H200 迄今为止仅适用于 SXM5 插槽,并且在矢量和矩阵数学方面具有与 Hopper H100 加速器完全相同的峰值性能统计数据。区别在于,H100 具有 80 GB 和 96 GB 的 HBM3 内存,在初始设备中分别提供 3.35 TB/秒和 3.9 TB/秒的带宽,而 H200 具有 141 GB 更快的 HBM3e 内存,带宽为 4.8总带宽 TB/秒。
与 Hopper 基准相比,内存容量增加了 1.76 倍,内存带宽比 Hopper 基准增加了 1.43 倍——所有这些都在相同的 700 瓦功率范围内。作为对比,AMD 的Antares MI300X 将提供 5.2 TB/秒的带宽和 192 GB 的 HBM3 容量,并且很可能提供更高的峰值浮点功率,但也可能只是更有效的浮点功率。
最后,与配备 HBM3E 的 GH200 系统一样,NVIDIA 预计 H200 加速器将于 2024 年第二季度推出。
HGX H200和Quad GH200 ,同时发布
除了 H200 加速器之外,NVIDIA 还发布了 HGX H200 平台,这是使用较新加速器的 8 路 HGX H100 的更新版本。HGX 载板是 NVIDIA H100/H200 系列的真正支柱,包含 8 个 SXM 外形加速器,这些加速器以预先安排的全连接拓扑连接。HGX 板的独立性质使其能够插入合适的主机系统,从而允许 OEM 定制其高端服务器的非 GPU 部分。

鉴于 HGX 与 NVIDIA 的服务器加速器齐头并进,HGX 200 的发布很大程度上只是一种形式。尽管如此,NVIDIA 仍确保在 SC23 上宣布这一消息,并确保 HGX 200 主板与 H100 主板交叉兼容。因此,服务器制造商可以在当前的设计中使用 HGX H200,从而实现相对无缝的过渡。
随着 NVIDIA 现在批量发售 Grace 和 Hopper(以及 Grace Hopper)芯片,该公司还宣布推出一些使用这些芯片的其他产品。其中最新的是 4 路 Grace Hopper GH200 板,NVIDIA 简称为 Quad GH200。
名副其实,Quad GH200 将四个 GH200 加速器放置在一块板上,然后可以安装在更大的系统中。各个 GH200 以 8 芯片、4 路 NVLink 拓扑相互连接,其想法是使用这些板作为更大系统的构建块。
实际上,Quad GH200 是与 HGX 平台相对应的 Grace Hopper。与仅 GPU 的 HGX 板不同,Grace CPU 的加入在技术上使每个板独立且自支撑,但将它们连接到主机基础设施的需求保持不变。
Quad GH200 节点将提供 288 个 Arm CPU 内核和总计 2.3TB 的高速内存。值得注意的是,NVIDIA 在这里没有提到使用 GH200 的 HBM3E 版本(至少最初没有),因此这些数字似乎是原始的 HBM3 版本。这意味着我们希望每个 Grace CPU 配备 480GB LPDDR5X,每个 Hopper GPU 配备 96GB HBM3。或者总共1920GB LPDDR5X和384GB HBM3内存。
一台超级计算机:23762个GH200,18.2 兆瓦
在发布H200的同时,NVIIDA 还宣布与 Jupiter 合作赢得了一项新的超级计算机设计。根据 EuroHPC 联合组织的订购,Jupiter 将成为由 23,762 个 GH200 节点构建的新型超级计算机。一旦上线,Jupiter 将成为迄今为止宣布的最大的基于 Hopper 的超级计算机,并且是第一台明确(且公开)针对标准 HPC 工作负载以及已经出现的低精度张量驱动的 AI 工作负载的超级计算机。定义迄今为止宣布的基于 Hopper 的超级计算机。
Jupiter 与 Eviden 和 ParTec 签约,彻底展示了NVIDIA 技术。基于 NVIDIA 今天发布的 Quad GH200 节点,Grace CPU 和 Hopper GPU 成为超级计算机的核心。各个节点均由 Quantum-2 InfiniBand 网络支持,毫无疑问基于 NVIDIA 的 ConnectX 适配器。
该公司没有透露具体的核心数量或内存容量数据,但由于我们知道单个 Quad GH200 主板提供的功能,因此数学计算很简单。在高端(假设没有出于良率原因进行回收/合并),这将是 23,762 个 Grace CPU、23,762 个 Hopper H100 级 GPU、大约 10.9 PB 的 LPDDR5X 和另外 2.2PB 的 HBM3 内存。
该系统预计为人工智能用途提供 93 EFLOPS 的低精度性能,或为传统 HPC 工作负载提供超过 1 EFLOPS 的高精度 (FP64) 性能。后一个数字尤其值得注意,因为这将使 Jupiter 成为第一个用于 HPC 工作负载的基于 NVIDIA 的百亿亿次系统。
也就是说,应谨慎对待 NVIDIA 的 HPC 性能声明,因为 NVIDIA 仍在计算张量性能 - 1 EFLOPS 是 23,762 个 H100 只能通过 FP64 张量运算提供的东西。理论 HPC 超级计算机吞吐量的传统指标是矢量性能而不是矩阵性能,因此该数字与其他系统不完全可比。不过,由于 HPC 工作负载也部分地大量使用了矩阵数学,因此这也不是一个完全无关的说法。否则,对于任何寻求强制性 Frontier 比较的人来说,Jupiter 的直接矢量性能将约为 800 TFLOPS,而 Frontier 的直接矢量性能是 Frontier 的两倍多。另一方面,这两个系统在现实条件下的接近程度将取决于它们各自的工作负载中使用了多少矩阵数学(LINPACK 结果应该很有趣)。
该系统的价格标签尚未公布,但功耗为:18.2 兆瓦电力(比 Frontier 少约 3 兆瓦)。因此,无论系统的真实价格是多少,就像系统本身一样,它绝不是娇小的。
根据 NVIDIA 的新闻稿,该系统将安装在德国于利希研究中心 (Forschungszentrum Jülich) 设施中,用于“创建气候和天气研究、材料科学、药物发现、工业工程和量子计算领域的基础人工智能模型”。” 该系统计划于 2024 年安装,但尚未公布预计上线日期。
网站声明:如果转载,请联系本站管理员。否则一切后果自行承担。
- 上周热门
- Kingbase用户权限管理 2020
- 信刻全自动光盘摆渡系统 1749
- 信刻国产化智能光盘柜管理系统 1419
- 银河麒麟添加网络打印机时,出现“client-error-not-possible”错误提示 1014
- 银河麒麟打印带有图像的文档时出错 924
- 银河麒麟添加打印机时,出现“server-error-internal-error” 715
- 麒麟系统也能完整体验微信啦! 657
- 统信桌面专业版【如何查询系统安装时间】 633
- 统信操作系统各版本介绍 624
- 统信桌面专业版【全盘安装UOS系统】介绍 598
- 本周热议
- 我的信创开放社区兼职赚钱历程 40
- 今天你签到了吗? 27
- 信创开放社区邀请他人注册的具体步骤如下 15
- 如何玩转信创开放社区—从小白进阶到专家 15
- 方德桌面操作系统 14
- 我有15积分有什么用? 13
- 用抖音玩法闯信创开放社区——用平台宣传企业产品服务 13
- 如何让你先人一步获得悬赏问题信息?(创作者必看) 12
- 2024中国信创产业发展大会暨中国信息科技创新与应用博览会 9
- 中央国家机关政府采购中心:应当将CPU、操作系统符合安全可靠测评要求纳入采购需求 8
