故障分析 | MySQL 参数设置不当导致复制中断

1前言
在日常的运维工作中,偶尔会遇到一些意想不到的线上问题,多数因为设置不当导致故障。前段时间,DMP 数据库运维平台[1] 报错主从复制 SQL 线程断开,就是因为一个参数设置异常导致的。本文分享一下当时的情况。
2故障描述
DMP 收到告警 MySQL 从库的 SQL 线程停止了工作,去从库后台执行 show slave status\G:
' fill='%23FFFFFF'%3E%3Crect x='249' y='126' width='1' height='1'%3E%3C/rect%3E%3C/g%3E%3C/g%3E%3C/svg%3E)
可以看到 SQL 线程确实停止工作了,根据提示查看 :select * from performance_schema.replication_applier_status_by_worker;
报错为:
Worker 1 failed executing transaction '44bbb836-19b4-11eb-aae3-98f2b315b1a5:216718523' at master log mysqlbin.000492, end_log_pos 533198991; Could not execute Delete_rows event on table cmbc_msearch.search_hotword_item; Multi-statement transaction required more than 'max_binlog_cache_size' bytes of storage; increase this mysqld variable and try again, Error_code: 1197; handler error HA_ERR_RBR_LOGGING_FAILED; the event's master log mysqlbin.000492, end_log_pos 533198991
我们可以看到报错信息比较明显,是 max_binlog_cache_size 参数设置出现了问题。
查看主从的 max_binlog_cache_size 的大小,主库为 10G,从库为 10M。
3原理描述
官方文档[2] 了解 max_binlog_cache_size 参数:
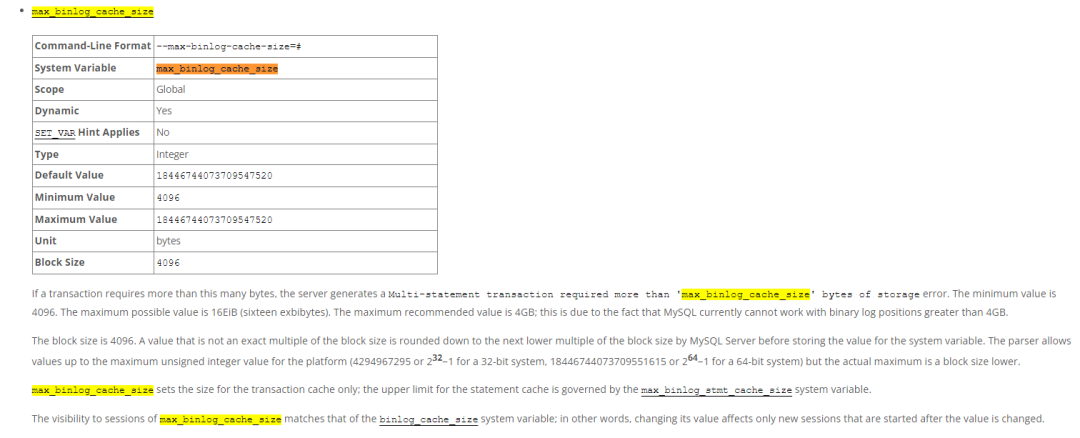
binlog 是 MySQL 用来记录所有修改数据库数据的操作的二进制日志。在主从复制中,主库会把自己的 binlog 传输给从库,供从库执行相同的操作,以保证数据的一致性。而 max_binlog_cache_size 则是 MySQL 设置的最大 binlog 缓存大小。当事务过于复杂,多语句事务执行,需要写入 binlog 的数据量超过了这个值时,就会出现上述错误。
此时还要注意另一个参数 binlog_cache_size,这个参数给每个客户端分配用来存储二进制日志的缓存,而 max_binlog_cache_size 则表示所有客户端缓存使用的最大值。
4问题解决
从库为 10M 的历史原因也追溯不到,但主从设置参数不一致,且一个很大一个很小,是不合理的,也是导致本文中报错的主要因素。
max_binlog_cache_size 参数是可以通过在线动态修改的,现场解决方案,将从库的该值调大:
mysql> set global max_binlog_cache_size=10240000000;
Query OK, 0 rows affected (0.00 sec)
然后再开启主从复制,就正常了。
5总结
在运维过程中,合理配置和及时调整参数是确保系统稳定性和性能优化的重要环节,在修改一些参数的时候要充分了解相关知识概念,并且要掌握复制集群中相同参数的配置情况,确保合理合规修改,减少生产故障。
参考资料
云树 DMP: https://www.actionsky.com/cloudTreeDMP
[2]max_binlog_cache_size: https://dev.mysql.com/doc/mysql-replication-excerpt/8.0/en/replication-options-binary-log.html
阅读推荐
故障分析 | innodb_thread_concurrency 导致数据库异常的问题分析
故障分析 | OceanBase 频繁更新数据后读性能下降的排查
技术分享 | 一招解决 MySQL 中 DDL 被阻塞的问题
故障分析 | 一条本该记录到慢日志的 SQL 是如何被漏掉的
Gdevops 全球敏捷运维峰会 北京站
7.21 爱可生开源社区将亮相【Gdevops 全球敏捷运维峰会 北京站】,期待与您线下交流。
爱可生技术专家苏鹏,将带来主题演讲《大模型与向量数据库:敏捷运维的创新引擎》,敬请期待。

议题要点
大模型具备强大的语言理解和生成能力,向量数据库能高效存储和索引大规模向量数据。将两者结合,可实现高速数据访问、智能决策和快速问题解决。通过大规模数据分析与大模型预测,我们能快速发现关键问题、优化系统、提升可靠性和效率。本议题将深入探讨原理、优势和应用场景,分享创新解决方案和成功案例,具体包括以下内容:
-
智能决策和问题解决:如何利用大模型的语言理解和生成能力,结合向量数据库的相似性搜索,快速做出敏捷决策和解决问题;
-
系统优化和故障排查:如何通过对大规模运维数据的分析和挖掘,结合大模型的预测能力,快速发现系统优化和故障排查的关键问题;
-
数据驱动的运维策略:如何利用大模型和向量数据库的结合,实现数据驱动的运维策略,提升系统的可靠性、效率和安全性。
网站声明:如果转载,请联系本站管理员。否则一切后果自行承担。
- 上周热门
- 如何使用 StarRocks 管理和优化数据湖中的数据? 2941
- 【软件正版化】软件正版化工作要点 2860
- 统信UOS试玩黑神话:悟空 2819
- 信刻光盘安全隔离与信息交换系统 2712
- 镜舟科技与中启乘数科技达成战略合作,共筑数据服务新生态 1246
- grub引导程序无法找到指定设备和分区 1213
- 华为全联接大会2024丨软通动力分论坛精彩议程抢先看! 163
- 点击报名 | 京东2025校招进校行程预告 162
- 2024海洋能源产业融合发展论坛暨博览会同期活动-海洋能源与数字化智能化论坛成功举办 160
- 华为纯血鸿蒙正式版9月底见!但Mate 70的内情还得接着挖... 157
- 本周热议
- 我的信创开放社区兼职赚钱历程 40
- 今天你签到了吗? 27
- 信创开放社区邀请他人注册的具体步骤如下 15
- 如何玩转信创开放社区—从小白进阶到专家 15
- 方德桌面操作系统 14
- 我有15积分有什么用? 13
- 用抖音玩法闯信创开放社区——用平台宣传企业产品服务 13
- 如何让你先人一步获得悬赏问题信息?(创作者必看) 12
- 2024中国信创产业发展大会暨中国信息科技创新与应用博览会 9
- 中央国家机关政府采购中心:应当将CPU、操作系统符合安全可靠测评要求纳入采购需求 8
