ChatGPT被起诉索赔30亿!OpenAI接连“吃官司”


6月29日,有16 名匿名人士向美国加利福尼亚州旧金山联邦法院提起诉讼,称 ChatGPT 在没有充分通知用户或获得同意的情况下收集和泄露了他们的个人信息,据此他们要求微软和 OpenAI 索赔 30 亿美元。

诉讼中指出,尽管制定了购买和使用个人信息的协议,但是OpenAI和微软系统性地从互联网中窃取了3000亿个单词,包括数百万未经同意获取的个人信息。

数据安全不容忽视,培养安全人才是大势所趋,高薪行业欢迎你的加入。天融信教育7月认证课程安排已出,详情请咨询~
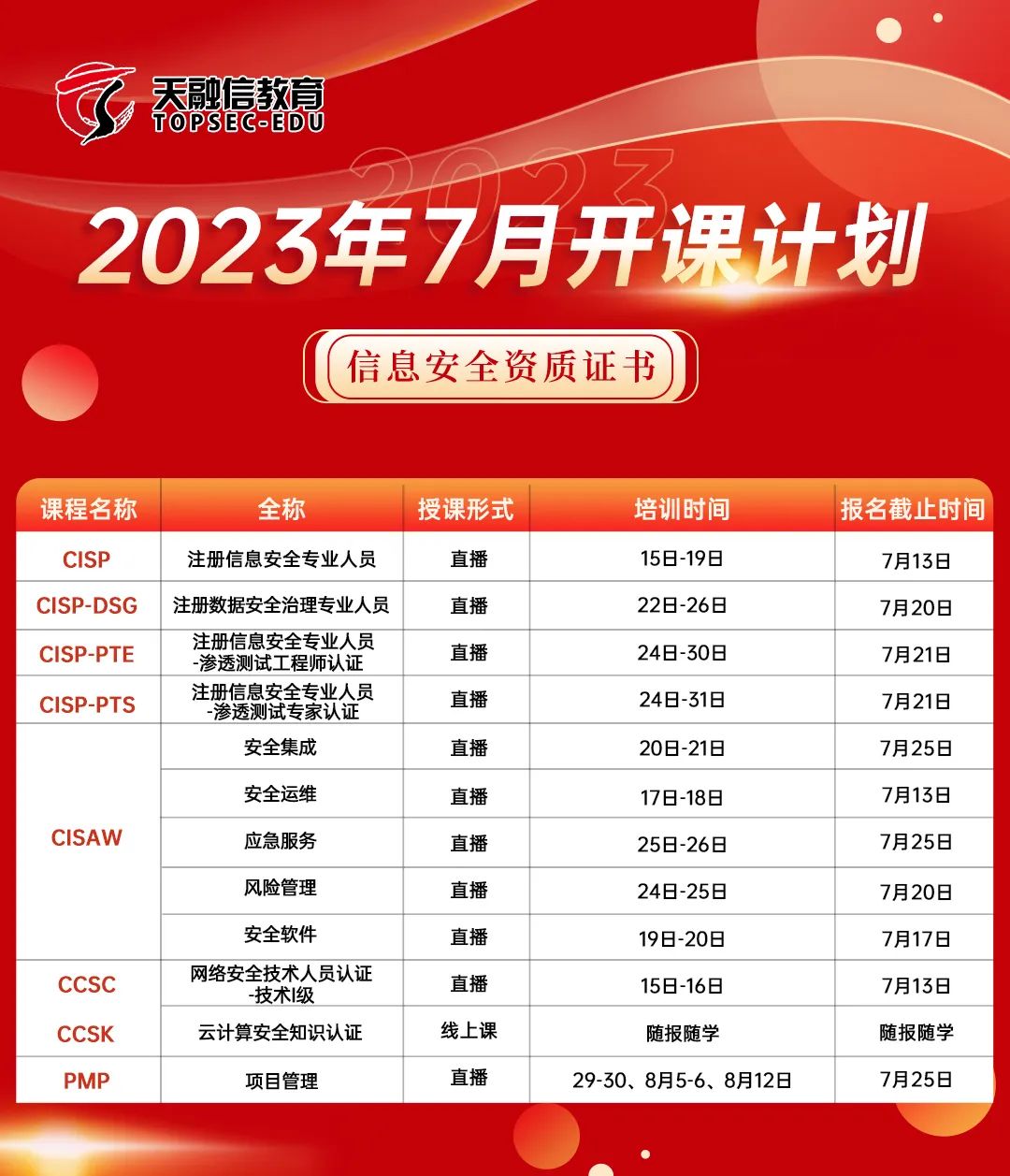
7月开课计划表
网站声明:如果转载,请联系本站管理员。否则一切后果自行承担。
赞同 0
评论 0 条
- 上周热门
- 银河麒麟添加网络打印机时,出现“client-error-not-possible”错误提示 1504
- 银河麒麟打印带有图像的文档时出错 1423
- 银河麒麟添加打印机时,出现“server-error-internal-error” 1213
- 统信操作系统各版本介绍 1134
- 统信桌面专业版【如何查询系统安装时间】 1131
- 统信桌面专业版【全盘安装UOS系统】介绍 1087
- 麒麟系统也能完整体验微信啦! 1043
- 统信【启动盘制作工具】使用介绍 692
- 统信桌面专业版【一个U盘做多个系统启动盘】的方法 635
- 信刻全自动档案蓝光光盘检测一体机 542
- 本周热议
- 我的信创开放社区兼职赚钱历程 40
- 今天你签到了吗? 27
- 信创开放社区邀请他人注册的具体步骤如下 15
- 如何玩转信创开放社区—从小白进阶到专家 15
- 方德桌面操作系统 14
- 我有15积分有什么用? 13
- 用抖音玩法闯信创开放社区——用平台宣传企业产品服务 13
- 如何让你先人一步获得悬赏问题信息?(创作者必看) 12
- 2024中国信创产业发展大会暨中国信息科技创新与应用博览会 9
- 中央国家机关政府采购中心:应当将CPU、操作系统符合安全可靠测评要求纳入采购需求 8
热门标签更多
