Paper:《Distilling the Knowledge in a Neural Network神经网络中的知识蒸馏》翻译与解读

Paper:《Distilling the Knowledge in a Neural Network神经网络中的知识蒸馏》翻译与解读
目录
《Distilling the Knowledge in a Neural Network神经网络中的知识蒸馏》翻译与解读
2.1 Matching logits is a special case of distillation
3、Preliminary experiments on MNIST
4、Experiments on speech recognition
5、Training ensembles of specialists on very big datasets
5.3、Assigning classes to specialists
5.4、Performing inference with ensembles of specialists
6、Soft Targets as Regularizers
6.1、Using soft targets to prevent specialists from overfitting
7、Relationship to Mixtures of Experts
《Distilling the Knowledge in a Neural Network神经网络中的知识蒸馏》翻译与解读
| 来源 | |
| 作者 | Geoffrey Hinton, Oriol Vinyals, Jeff Dean |
| 发布日期 | 2015年3月9日 |
Abstract
| A very simple way to improve the performance of almost any machine learning algorithm is to train many different models on the same data and then to average their predictions [3]. Unfortunately, making predictions using a whole ensemble of models is cumbersome and may be too computationally expensive to allow de- ployment to a large number of users, especially if the individual models are large neural nets. Caruana and his collaborators [1] have shown that it is possible to compress the knowledge in an ensemble into a single model which is much eas- ier to deploy and we develop this approach further using a different compression technique. We achieve some surprising results on MNIST and we show that we can significantly improve the acoustic model of a heavily used commercial system by distilling the knowledge in an ensemble of models into a single model. We also introduce a new type of ensemble composed of one or more full models and many specialist models which learn to distinguish fine-grained classes that the full mod- els confuse. Unlike a mixture of experts, these specialist models can be trained rapidly and in parallel. | 提高几乎任何机器学习算法性能的一种非常简单的方法,是在相同数据上训练许多不同的模型,然后对它们的预测进行平均[3]。不幸的是,使用整个模型集合进行预测是很麻烦的,并且可能计算量太大,而无法部署到大量用户,特别是在单个模型是大型神经网络的情况下。Caruana和他的合作者[1]已经证明,可以将集成中的知识压缩到一个更容易部署的模型中,我们使用一种不同的压缩技术进一步开发了这种方法。我们在MNIST上取得了一些令人惊讶的结果,并且我们表明,我们可以通过将模型集合中的知识提取到单个模型中来显著改进大量使用的商业系统的声学模型。我们还介绍了一种新的集成类型,它由一个或多个完整模型和许多专家模型组成,这些专家模型学习区分完整模型所混淆的细粒度类。与混合专家不同,这些专家模型可以快速、并行地训练。 |
1、Introduction
| Many insects have a larval form that is optimized for extracting energy and nutrients from the envi- ronment and a completely different adult form that is optimized for the very different requirements of traveling and reproduction. In large-scale machine learning, we typically use very similar models for the training stage and the deployment stage despite their very different requirements: For tasks like speech and object recognition, training must extract structure from very large, highly redundant datasets but it does not need to operate in real time and it can use a huge amount of computation. Deployment to a large number of users, however, has much more stringent requirements on latency and computational resources. The analogy with insects suggests that we should be willing to train very cumbersome models if that makes it easier to extract structure from the data. The cumbersome model could be an ensemble of separately trained models or a single very large model trained with a very strong regularizer such as dropout [9]. Once the cumbersome model has been trained, we can then use a different kind of training, which we call “distillation” to transfer the knowledge from the cumbersome model to a small model that is more suitable for deployment. A version of this strategy has already been pioneered by Rich Caruana and his collaborators [1]. In their important paper they demonstrate convincingly that the knowledge acquired by a large ensemble of models can be transferred to a single small model. | 许多昆虫的幼虫都能从环境中汲取能量和营养,而成虫则完全不同,能满足旅行和繁殖的不同需求。在大规模机器学习中,我们通常在训练阶段和部署阶段使用非常相似的模型,尽管它们的要求非常不同:对于像语音和目标识别这样的任务,训练必须从非常大的、高冗余的数据集中提取结构,但它不需要实时操作,并且可以使用大量的计算。但是,部署到大量用户时,对延迟和计算资源的要求要严格得多。与昆虫的类比表明,如果能更容易地从数据中提取结构,我们应该愿意训练非常繁琐的模型。繁琐的模型可以是单独训练的模型的集合,也可以是使用非常强的正则化器(如dropout[9])训练的单个非常大的模型。一旦繁琐的模型训练完毕,我们就可以使用另一种训练方式,我们称之为“蒸馏”,将知识从繁琐的模型转移到更适合部署的小模型上。Rich Caruana和他的合作者[1]已经开创了这种策略的一个版本。在他们的重要论文中,他们令人信服地证明了,由大量模型集合获得的知识可以转移到单个小模型上。 |
| A conceptual block that may have prevented more investigation of this very promising approach is that we tend to identify the knowledge in a trained model with the learned parameter values and this makes it hard to see how we can change the form of the model but keep the same knowledge. A more abstract view of the knowledge, that frees it from any particular instantiation, is that it is a learned mapping from input vectors to output vectors. For cumbersome models that learn to discriminate between a large number of classes, the normal training objective is to maximize the average log probability of the correct answer, but a side-effect of the learning is that the trained model assigns probabilities to all of the incorrect answers and even when these probabilities are very small, some of them are much larger than others. The relative probabilities of incorrect answers tell us a lot about how the cumbersome model tends to generalize. An image of a BMW, for example, may only have a very small chance of being mistaken for a garbage truck, but that mistake is still many times more probable than mistaking it for a carrot. | 一个可能阻碍对这种非常有前途的方法进行更多研究的概念块是,我们倾向于用学习到的参数值来识别训练模型中的知识,这使得我们很难看到我们如何改变模型的形式但保持相同的知识。将知识从任何特定实例化中解放出来的更抽象的知识视图是,它是从输入向量到输出向量的学习映射。对于学习区分大量类别的繁琐模型,正常的训练目标是最大化正确答案的平均对数概率,但学习的副作用是训练后的模型将概率分配给所有不正确的答案,即使这些概率非常小,其中一些也比其他概率大得多。错误答案的相对概率告诉我们很多关于这个繁琐的模型是如何泛化的。例如,一辆宝马的图像可能只有很小的几率被误认为是垃圾车,但这个错误仍然比把它误认为是胡萝卜的可能性大很多倍。 |
| It is generally accepted that the objective function used for training should reflect the true objective of the user as closely as possible. Despite this, models are usually trained to optimize performance on the training data when the real objective is to generalize well to new data. It would clearly be better to train models to generalize well, but this requires information about the correct way to generalize and this information is not normally available. When we are distilling the knowledge from a large model into a small one, however, we can train the small model to generalize in the same way as the large model. If the cumbersome model generalizes well because, for example, it is the average of a large ensemble of different models, a small model trained to generalize in the same way will typically do much better on test data than a small model that is trained in the normal way on the same training set as was used to train the ensemble. An obvious way to transfer the generalization ability of the cumbersome model to a small model is to use the class probabilities produced by the cumbersome model as “soft targets” for training the small model. For this transfer stage, we could use the same training set or a separate “transfer” set. When the cumbersome model is a large ensemble of simpler models, we can use an arithmetic or geometric mean of their individual predictive distributions as the soft targets. When the soft targets have high entropy, they provide much more information per training case than hard targets and much less variance in the gradient between training cases, so the small model can often be trained on much less data than the original cumbersome model and using a much higher learning rate. | 一般认为,用于训练的目标函数应尽可能地反映用户的真实目标。尽管如此,当真正的目标是很好地泛化到新数据时,通常会训练模型以优化训练数据的性能。练模型以很好地泛化显然会更好,但这需要有关正确泛化方法的信息,而这些信息通常不可用(不可获得的)。然而,当我们将知识从大模型提炼成小模型时,我们可以训练小模型以与大模型相同的方式进行泛化。如果繁琐的模型泛化得很好,例如,它是不同模型的大型集合的平均值,那么用同样的方法训练的一个小模型在测试数据上的泛化效果,通常会比用正常的方法训练的小模型在用于训练集合的同一训练集上的效果要好得多。 将繁琐模型的泛化能力转移到小模型的一种明显方法,是使用繁琐模型产生的类概率作为训练小模型的“软目标”。对于这个转移阶段,我们可以使用相同的训练集或单独的“迁移”集。当繁琐的模型是简单模型的大集合时,我们可以使用它们各自预测分布的算术或几何平均值作为软目标。当软目标具有较高的熵值时,它们提供的每个训练案例的信息量比硬目标要大得多,并且训练案例之间的梯度变化要小得多,因此小模型通常可以在比原始繁琐模型少得多的数据上进行训练,并使用更高的学习率。 |
| For tasks like MNIST in which the cumbersome model almost always produces the correct answer with very high confidence, much of the information about the learned function resides in the ratios of very small probabilities in the soft targets. For example, one version of a 2 may be given a probability of 10−6 of being a 3 and 10−9 of being a 7 whereas for another version it may be the other way around. This is valuable information that defines a rich similarity structure over the data (i. e. it says which 2’s look like 3’s and which look like 7’s) but it has very little influence on the cross-entropy cost function during the transfer stage because the probabilities are so close to zero. Caruana and his collaborators circumvent this problem by using the logits (the inputs to the final softmax) rather than the probabilities produced by the softmax as the targets for learning the small model and they minimize the squared difference between the logits produced by the cumbersome model and the logits produced by the small model. Our more general solution, called “distillation”,is to raise the temperature of the final softmax until the cumbersome model produces a suitably soft set of targets. We then use the same high temperature when training the small model to match these soft targets. We show later that matching the logits of the cumbersome model is actually a special case of distillation. The transfer set that is used to train the small model could consist entirely of unlabeled data [1] or we could use the original training set. We have found that using the original training set works well, especially if we add a small term to the objective function that encourages the small model to predict the true targets as well as matching the soft targets provided by the cumbersome model. Typically, the small model cannot exactly match the soft targets and erring in the direction of the correct answer turns out to be helpful. | 对于像MNIST这样的任务,繁琐的模型几乎总是以非常高的置信度产生正确的答案,关于学习函数的大部分信息都存在于软目标中非常小的概率的比率中。例如,一个版本的2可能有10-6的概率是3,10- 9的概率是7,而对于另一个版本,可能是相反的。这是有价值的信息,它定义了数据上丰富的相似结构(即,它说明哪个2看起来像3,哪个看起来像7),但它对传递阶段的交叉熵代价函数影响很小,因为概率如此接近于零。Caruana和他的合作者通过使用logits(最终softmax的输入)而不是softmax产生的概率作为学习小模型的目标来规避这个问题,他们最小化了繁琐模型产生的logits和小模型产生的logits之间的平方差。我们更通用的解决方案,称为“蒸馏”,是提高最终softmax的温度,直到繁琐的模型产生一组合适的软目标。然后我们在训练小模型以匹配这些软目标时使用相同的高温。我们稍后将说明,匹配繁琐模型的 logits 实际上是蒸馏的一种特殊情况。 用于训练小模型的传输集可以完全由未标记的数据[1]组成,或者我们可以使用原始的训练集。我们发现使用原始的训练集效果很好,特别是如果我们在目标函数中加入一个小项,鼓励小模型预测真实目标,并匹配繁琐的模型提供的软目标。通常情况下,小模型不能完全匹配软目标,并且在正确答案的方向上犯错是有帮助的。 |
2、Distillation
| Neural networks typically produce class probabilities by using a “softmax” output layer that converts the logit, zi, computed for each class into a probability, qi, by comparing zi with the other logits.
where T is a temperature that is normally set to 1. Using a higher value for T produces a softer probability distribution over classes. | 神经网络通常通过使用“softmax”输出层生成类概率,该输出层通过比较zi与其他logit,将为每个类计算的logit, zi转换为概率,qi。 其中T是通常设为1的温度。使用较高的T值在类中产生较软的概率分布。 |
| In the simplest form of distillation, knowledge is transferred to the distilled model by training it on a transfer set and using a soft target distribution for each case in the transfer set that is produced by using the cumbersome model with a high temperature in its softmax. The same high temperature is used when training the distilled model, but after it has been trained it uses a temperature of 1. When the correct labels are known for all or some of the transfer set, this method can be significantly improved by also training the distilled model to produce the correct labels. One way to do this is to use the correct labels to modify the soft targets, but we found that a better way is to simply use a weighted average of two different objective functions. The first objective function is the cross entropy with the soft targets and this cross entropy is computed using the same high temperature in the softmax of the distilled model as was used for generating the soft targets from the cumbersome model. The second objective function is the cross entropy with the correct labels. This is computed using exactly the same logits in softmax of the distilled model but at a temperature of 1. We found that the best results were generally obtained by using a condiderably lower weight on the second objective function. Since the magnitudes of the gradients produced by the soft targets scale as 1/T 2 it is important to multiply them by T 2 when using both hard and soft targets. This ensures that the relative contributions of the hard and soft targets remain roughly unchanged if the temperature used for distillation is changed while experimenting with meta-parameters. | 在最简单的精馏形式中,知识通过在一个转移集上对其进行训练,并对通过在其softmax中使用高温的繁琐模型产生的转移集中的每个情况使用软目标分布来转移到精馏模型。训练蒸馏模型时使用相同的高温,但训练后使用的温度为1。 当所有或部分传输集都知道正确的标签时,还可以训练提取的模型生成正确的标签,从而显著改进该方法。一种方法是使用正确的标签来修改软目标,但我们发现更好的方法是简单地使用两个不同目标函数的加权平均。第一个目标函数是软目标的交叉熵,该交叉熵的计算方法与从繁琐的模型生成软目标时使用的相同,即使用蒸馏模型的softmax中的高温。第二个目标函数是带有正确标签的交叉熵。这是在蒸馏模型的softmax中使用完全相同的对数,但温度为1。我们发现,最好的结果通常是使用一个相当低的权重对第二个目标函数。由于软目标产生的梯度大小为1/ t2,因此在使用硬目标和软目标时,将它们乘以t2是很重要的。这确保了在使用元参数进行实验时,如果改变蒸馏所用的温度,硬靶和软靶的相对贡献大致保持不变。 |
2.1 Matching logits is a special case of distillation
| Each case in the transfer set contributes a cross-entropy gradient, dC/dzi, with respect to each logit, zi of the distilled model. If the cumbersome model has logits vi which produce soft target probabilities pi and the transfer training is done at a temperature of T , this gradient is given by:
If the temperature is high compared with the magnitude of the logits, we can approximate: If we now assume that the logits have been zero-meaned separately for each transfer case so that | 在转移集中的每一种情况都贡献了一个交叉熵梯度,dC/dzi,相对于蒸馏模型的每个logit, zi。如果繁琐的模型有logits vi,产生软目标概率pi,并且转移训练是在温度T下进行的,这个梯度由: 如果温度比对数的量级高,我们可以近似地: 如果我们现在假设每一个转帐案例的对数都是零,那么 |
| So in the high temperature limit, distillation is equivalent to minimizing 1/2(zi − vi)2, provided the logits are zero-meaned separately for each transfer case. At lower temperatures, distillation pays much less attention to matching logits that are much more negative than the average. This is poten- tially advantageous because these logits are almost completely unconstrained by the cost function used for training the cumbersome model so they could be very noisy. On the other hand, the very negative logits may convey useful information about the knowledge acquired by the cumbersome model. Which of these effects dominates is an empirical question. We show that when the distilled model is much too small to capture all of the knowledege in the cumbersome model, intermedi- ate temperatures work best which strongly suggests that ignoring the large negative logits can be helpful. | 所以在高温极限下,蒸馏等价于最小化1/2(zi−vi)2,前提是每个转移情况下的对数都是零。在较低的温度下,蒸馏很少注意匹配比平均值负得多的对数。这是潜在的优势,因为这些对数几乎完全不受用于训练繁琐模型的代价函数的限制,因此它们可能非常嘈杂。另一方面,非常负的对数可能会传递由繁琐的模型获得的知识的有用信息。这些效应中哪一个占主导地位是一个经验问题。我们表明,当蒸馏模型太小,无法捕捉繁琐模型中的所有知识时,中间温度是最好的,这强烈表明忽略大的负对数是有帮助的。 |

3、Preliminary experiments on MNIST
| To see how well distillation works, we trained a single large neural net with two hidden layers of 1200 rectified linear hidden units on all 60,000 training cases. The net was strongly regularized using dropout and weight-constraints as described in [5]. Dropout can be viewed as a way of training an exponentially large ensemble of models that share weights. In addition, the input images were jittered by up to two pixels in any direction. This net achieved 67 test errors whereas a smaller net with two hidden layers of 800 rectified linear hidden units and no regularization achieved 146 errors. But if the smaller net was regularized solely by adding the additional task of matching the soft targets produced by the large net at a temperature of 20, it achieved 74 test errors. This shows that soft targets can transfer a great deal of knowledge to the distilled model, including the knowledge about how to generalize that is learned from translated training data even though the transfer set does not contain any translations. | 为了了解蒸馏工作的效果如何,我们在所有60000个训练案例上训练了一个具有两个隐藏层的大型神经网络,该隐藏层包含1200个经过修正的线性隐藏单元。如[5]中所述,使用dropout和weight约束对网进行了强正则化。Dropout可以被视为一种训练共享权重的指数级模型集合的方法。此外,输入图像在任何方向上都有最多两个像素的抖动。这个网络实现了67个测试错误,而一个较小的网络,两个隐藏层800矫正线性隐藏单元,没有正则化实现了146个错误。但如果仅通过添加匹配大网在温度为20时产生的软目标的附加任务来对小网进行正则化,则其测试误差为74。这表明,软目标可以将大量知识转移到提取的模型中,包括从翻译后的训练数据中学习到的关于如何归纳的知识,即使转移集不包含任何翻译。 |
| When the distilled net had 300 or more units in each of its two hidden layers, all temperatures above 8 gave fairly similar results. But when this was radically reduced to 30 units per layer, temperatures in the range 2.5 to 4 worked significantly better than higher or lower temperatures. We then tried omitting all examples of the digit 3 from the transfer set. So from the perspective of the distilled model, 3 is a mythical digit that it has never seen. Despite this, the distilled model only makes 206 test errors of which 133 are on the 1010 threes in the test set. Most of the errors are caused by the fact that the learned bias for the 3 class is much too low. If this bias is increased by 3.5 (which optimizes overall performance on the test set), the distilled model makes 109 errors of which 14 are on 3s. So with the right bias, the distilled model gets 98.6% of the test 3s correct despite never having seen a 3 during training. If the transfer set contains only the 7s and 8s from the training set, the distilled model makes 47.3% test errors, but when the biases for 7 and 8 are reduced by 7.6 to optimize test performance, this falls to 13.2% test errors. | 当蒸馏网的两个隐藏层中各有300个或更多的单元时,所有温度高于8的结果都相当相似。但当这一数字大幅降低到每层30个单位时,2.5到4的温度范围内的工作效果明显优于更高或更低的温度。 然后我们试着省略所有数字3的例子。所以从蒸馏模型的角度来看,3是一个从未见过的神话数字。尽管如此,蒸馏模型只产生206个测试错误,其中133个错误位于测试集中的1010个3上。大部分的错误是由于3类的习得偏差太低。如果这个偏差增加3.5(这优化了测试集的整体性能),蒸馏模型产生109个错误,其中14个错误在3。因此,在正确的偏差下,蒸馏模型得到了98.6%的测试3的正确率,尽管在训练中从未见过3。如果转移集只包含训练集的7s和8s,蒸馏模型的测试误差为47.3%,但当对7和8的偏差降低7.6以优化测试性能时,这一测试误差下降到13.2%。 |
4、Experiments on speech recognition
| In this section, we investigate the effects of ensembling Deep Neural Network (DNN) acoustic models that are used in Automatic Speech Recognition (ASR). We show that the distillation strategy that we propose in this paper achieves the desired effect of distilling an ensemble of models into a single model that works significantly better than a model of the same size that is learned directly from the same training data. State-of-the-art ASR systems currently use DNNs to map a (short) temporal context of features derived from the waveform to a probability distribution over the discrete states of a Hidden Markov Model (HMM) [4]. More specifically, the DNN produces a probability distribution over clusters of tri-phone states at each time and a decoder then finds a path through the HMM states that is the best compromise between using high probability states and producing a transcription that is probable under the language model. | 在本节中,我们研究了在自动语音识别(ASR)中使用的集成深度神经网络(DNN)声学模型的影响。我们表明,我们在本文中提出的蒸馏策略达到了期望的效果,即将一组模型蒸馏成一个单独的模型,其效果明显优于直接从相同的训练数据学习的相同规模的模型。 最先进的ASR系统目前使用dnn将从波形导出的特征的(短)时间上下文映射到隐藏马尔可夫模型(HMM)[4]的离散状态的概率分布。更具体地说,DNN每次在三音状态集群上产生一个概率分布,然后解码器找到一个通过HMM状态的路径,它是使用高概率状态和在语言模型下产生可能的转录之间的最佳折衷。 |
| Although it is possible (and desirable) to train the DNN in such a way that the decoder (and, thus, the language model) is taken into account by marginalizing over all possible paths, it is common to train the DNN to perform frame-by-frame classification by (locally) minimizing the cross entropy between the predictions made by the net and the labels given by a forced alignment with the ground truth sequence of states for each observation:
where θ are the parameters of our acoustic model P which maps acoustic observations at time t,st, to a probability, P (ht|st; θ′) , of the “correct” HMM state ht, which is determined by a forced alignment with the correct sequence of words. The model is trained with a distributed stochastic gradient descent approach. | 尽管通过边缘化所有可能的路径来考虑解码器(以及语言模型)的方式来训练DNN是可能的(也是可取的),但通常的做法是通过(局部)最小化网络做出的预测与每个观测的状态的地面真实序列强制对齐所给出的标签之间的交叉熵来训练DNN执行逐帧分类: θ是我们的声学模型P的参数,它将时间t,st的声学观测映射到一个概率,P (ht|st;θ ')的“正确”HMM状态ht,它是通过与正确的单词序列强制对齐来确定的。该模型采用分布随机梯度下降法进行训练。 |
| We use an architecture with 8 hidden layers each containing 2560 rectified linear units and a final softmax layer with 14,000 labels (HMM targets ht). The input is 26 frames of 40 Mel-scaled filter- bank coefficients with a 10ms advance per frame and we predict the HMM state of 21st frame. The total number of parameters is about 85M. This is a slightly outdated version of the acoustic model used by Android voice search, and should be considered as a very strong baseline. To train the DNN acoustic model we use about 2000 hours of spoken English data, which yields about 700M training examples. This system achieves a frame accuracy of 58.9%, and a Word Error Rate (WER) of 10.9% on our development set. | 我们使用的架构有8个隐藏层,每层包含2560个修正线性单元,最后的softmax层包含14000个标签(HMM目标ht)。输入26帧,每帧40个梅尔缩放滤波器组系数,每帧10毫秒,预测第21帧的HMM状态。参数总数约85M。这是Android语音搜索使用的声学模型的一个稍微过时的版本,应该被认为是一个非常强的基线。为了训练DNN声学模型,我们使用了大约2000小时的英语口语数据,这产生了大约700万个训练示例。该系统的帧正确率为58.9%,文字错误率(WER)为10.9%。 |
|
Table 1: Frame classification accuracy and WER showing that the distilled single model performs about as well as the averaged predictions of 10 models that were used to create the soft targets. | 表1:帧分类精度和WER显示,蒸馏的单个模型的性能大约与用于创建软目标的10个模型的平均预测一样好。 |

4.1、Results
| We trained 10 separate models to predict P (ht|st; θ), using exactly the same architecture and train- ing procedure as the baseline. The models are randomly initialized with different initial parameter values and we find that this creates sufficient diversity in the trained models to allow the averaged predictions of the ensemble to significantly outperform the individual models. We have explored adding diversity to the models by varying the sets of data that each model sees, but we found this to not significantly change our results, so we opted for the simpler approach. For the distillation we tried temperatures of [1, 2, 5, 10] and used a relative weight of 0.5 on the cross-entropy for the hard targets, where bold font indicates the best value that was used for table 1 . | 我们训练了10个不同的模型来预测P (ht|st;θ),使用完全相同的架构和训练程序作为基线。这些模型是用不同的初始参数值随机初始化的,我们发现这在训练的模型中产生了足够的多样性,从而允许集合的平均预测显著优于单个模型。我们已经探索了通过改变每个模型看到的数据集来增加模型的多样性,但我们发现这不会显著改变我们的结果,所以我们选择了更简单的方法。对于蒸馏,我们尝试了[1,2,5,10]的温度,并在硬目标的交叉熵上使用了0.5的相对权重,其中粗体字体表示表1中使用的最佳值。 |
| Table 1 shows that, indeed, our distillation approach is able to extract more useful information from the training set than simply using the hard labels to train a single model. More than 80% of the improvement in frame classification accuracy achieved by using an ensemble of 10 models is trans- ferred to the distilled model which is similar to the improvement we observed in our preliminary experiments on MNIST. The ensemble gives a smaller improvement on the ultimate objective of WER (on a 23K-word test set) due to the mismatch in the objective function, but again, the im- provement in WER achieved by the ensemble is transferred to the distilled model. We have recently become aware of related work on learning a small acoustic model by matching the class probabilities of an already trained larger model [8]. However, they do the distillation at a temperature of 1 using a large unlabeled dataset and their best distilled model only reduces the error rate of the small model by 28% of the gap between the error rates of the large and small models when they are both trained with hard labels. | 表1显示,实际上,我们的蒸馏方法能够从训练集中提取更多有用的信息,而不是简单地使用硬标签来训练单个模型。使用10个模型的集合所获得的帧分类精度提高的80%以上被转移到蒸馏模型中,这与我们在MNIST上的初步实验中观察到的改进类似。由于目标函数不匹配,集成对WER的最终目标(在23K-word测试集上)的改进较小,但同样,集成对WER的改进被转移到蒸馏模型中。 我们最近了解到,通过匹配已训练的较大模型[8]的类概率来学习一个小型声学模型的相关工作。然而,他们使用大型未标记数据集在1的温度下进行蒸馏,他们最好的蒸馏模型在使用硬标签训练时仅将小模型的错误率降低了大模型和小模型错误率之间的差距的28%。 |
5、Training ensembles of specialists on very big datasets
| Training an ensemble of models is a very simple way to take advantage of parallel computation and the usual objection that an ensemble requires too much computation at test time can be dealt with by using distillation. There is, however, another important objection to ensembles: If the individual models are large neural networks and the dataset is very large, the amount of computation required at training time is excessive, even though it is easy to parallelize. In this section we give an example of such a dataset and we show how learning specialist models that each focus on a different confusable subset of the classes can reduce the total amount of computation required to learn an ensemble. The main problem with specialists that focus on making fine-grained distinctions is that they overfit very easily and we describe how this overfitting may be prevented by using soft targets. | 训练模型的集合是利用并行计算的一种非常简单的方法,而集合在测试时需要太多的计算这一常见的反对意见可以通过使用精馏来处理。然而,对于集成还有另一个重要的反对意见:如果单个模型是大型神经网络,并且数据集非常大,那么在训练时所需的计算量是过多的,尽管它很容易并行化。 在本节中,我们将给出这样一个数据集的示例,并展示学习专家模型(每个专注于类的不同可混淆子集)如何减少学习集成所需的总计算量。专注于细粒度区分的专家的主要问题是,他们很容易过拟合,我们描述了如何使用软目标来防止这种过拟合。 |
5.1、The JFT dataset
| JFT is an internal Google dataset that has 100 million labeled images with 15,000 labels. When we did this work, Google’s baseline model for JFT was a deep convolutional neural network [7] that had been trained for about six months using asynchronous stochastic gradient descent on a large number of cores. This training used two types of parallelism [2]. First, there were many replicas of the neural net running on different sets of cores and processing different mini-batches from the training set. Each replica computes the average gradient on its current mini-batch and sends this gradient to a sharded parameter server which sends back new values for the parameters. These new values reflect all of the gradients received by the parameter server since the last time it sent parameters to the replica. Second, each replica is spread over multiple cores by putting different subsets of the neurons on each core. Ensemble training is yet a third type of parallelism that can be wrapped around the other two types, but only if a lot more cores are available. Waiting for several years to train an ensemble of models was not an option, so we needed a much faster way to improve the baseline model. | JFT是一个内部谷歌数据集,有1亿张带15000个标签的标记图像。当我们做这项工作时,谷歌对于JFT的基线模型是一个深度卷积神经网络[7],它已经在大量核上使用异步随机梯度下降训练了大约6个月。这个训练使用了两种类型的并行性[2]。首先,有许多神经网络的副本运行在不同的核心集和处理不同的小批量从训练集。每个副本计算其当前小批处理上的平均梯度,并将这个梯度发送给分片参数服务器,后者返回参数的新值。这些新值反映了参数服务器自上次向副本发送参数以来接收到的所有梯度。其次,通过在每个核上放置不同的神经元子集,每个副本分布在多个核上。集成训练是第三种并行方式,它可以与其他两种并行方式相结合,但前提是有更多的核心可用。等待几年来训练一个模型集合是不可取的,所以我们需要一种更快的方法来改进基线模型。 |
|
Table 2: Example classes from clusters computed by our covariance matrix clustering algorithm | 表2:由协方差矩阵聚类算法计算的集群中的示例类 |

5.2、Specialist Models
| When the number of classes is very large, it makes sense for the cumbersome model to be an en- semble that contains one generalist model trained on all the data and many “specialist” models, each of which is trained on data that is highly enriched in examples from a very confusable subset of the classes (like different types of mushroom). The softmax of this type of specialist can be made much smaller by combining all of the classes it does not care about into a single dustbin class. To reduce overfitting and share the work of learning lower level feature detectors, each specialist model is initialized with the weights of the generalist model. These weights are then slightly modi- fied by training the specialist with half its examples coming from its special subset and half sampled at random from the remainder of the training set. After training, we can correct for the biased train- ing set by incrementing the logit of the dustbin class by the log of the proportion by which the specialist class is oversampled. | 当类的数量非常大时,将繁琐的模型作为一个集合是有意义的,它包含一个训练于所有数据的全能型模型和许多“专家”模型,其中每个模型都训练于从一个非常容易混淆的类子集(如不同类型的蘑菇)中富含示例的数据。这类专家的softmax可以通过将它不关心的所有类合并到一个垃圾箱类中来变得更小。 为了减少过拟合,分担低级特征检测器的学习工作,每个专业模型都使用通才模型的权值进行初始化。然后对这些权重稍加修改,方法是用一半来自其特殊子集的示例来训练专家,另一半则从训练集的其余部分随机抽样。训练后,我们可以通过将垃圾桶类的对数乘以专家类的过采样比例的对数来校正有偏差的训练集。 |
5.3、Assigning classes to specialists
| In order to derive groupings of object categories for the specialists, we decided to focus on categories that our full network often confuses. Even though we could have computed the confusion matrix and used it as a way to find such clusters, we opted for a simpler approach that does not require the true labels to construct the clusters. In particular, we apply a clustering algorithm to the covariance matrix of the predictions of our generalist model, so that a set of classes Sm that are often predicted together will be used as targets for one of our specialist models, m. We applied an on-line version of the K-means algorithm to the columns of the covariance matrix, and obtained reasonable clusters (shown in Table 2). We tried several clustering algorithms which produced similar results. | 为了为专家提供对象类别的分组,我们决定专注于我们的整个网络经常混淆的类别。尽管我们可以计算混淆矩阵并使用它来找到这样的集群,但我们选择了一种更简单的方法,不需要真正的标签来构建集群。 特别地,我们对我们的通才模型的预测的协方差矩阵应用了一种聚类算法,因此一组经常被一起预测的类Sm将被用作我们的一个专家模型m的目标。我们对协方差矩阵的列应用了一个在线版本的K-means算法,得到了合理的聚类(如表2所示)。我们尝试了几种聚类算法,产生了类似的结果。 |
5.4、Performing inference with ensembles of specialists
| Before investigating what happens when specialist models are distilled, we wanted to see how well ensembles containing specialists performed. In addition to the specialist models, we always have a generalist model so that we can deal with classes for which we have no specialists and so that we can decide which specialists to use. Given an input image x, we do top-one classification in two steps: Step 1: For each test case, we find the n most probable classes according to the generalist model. Call this set of classes k. In our experiments, we used n = 1. Step 2: We then take all the specialist models, m, whose special subset of confusable classes, Sm, has a non-empty intersection with k and call this the active set of specialists Ak (note that this set may be empty). We then find the full probability distribution q over all the classes that minimizes:
| 在研究提取专家模型时发生的情况之前,我们想看看包含专家的集合的表现如何。除了专家模型之外,我们总是有一个多面手模型,这样我们就可以处理那些没有专家的类,这样我们就可以决定使用哪些专家。给定一个输入图像x,我们分两步进行上面的分类: 步骤1:对于每个测试用例,我们根据通才模型找到n个最可能的类。将这个类集合称为k。在我们的实验中,我们使用n = 1。 步骤2:然后我们取所有的专家模型,m,它的可混淆类的特殊子集Sm,与k有一个非空的交集,并称之为活跃的专家集合Ak(注意这个集合可能是空的)。然后我们找到所有类中最小值的完整概率分布q: |
| where KL denotes the KL divergence, and pm pg denote the probability distribution of a specialist model or the generalist full model. The distribution pm is a distribution over all the specialist classes of m plus a single dustbin class, so when computing its KL divergence from the full q distribution we sum all of the probabilities that the full q distribution assigns to all the classes in m’s dustbin. | 其中KL表示KL散度,pm pg表示专家模型或全能型模型的概率分布。分布pm是所有专业类m加上一个垃圾箱类的分布,所以当计算其与全q分布的KL散度时,我们将全q分布分配给m垃圾箱中所有类的所有概率相加。 |
|
Table 4: Top 1 accuracy improvement by of specialist models covering correct class on the JFT test set. | 表4:通过在JFT测试集中覆盖正确的类,专家模型的精度提高了1。 |
| Eq. 5 does not have a general closed form solution, though when all the models produce a single probability for each class the solution is either the arithmetic or geometric mean, depending on whether we use KL(p, q) or KL(q, p)). We parameterize q = sof tmax(z) (with T = 1) and we use gradient descent to optimize the logits z w.r.t. eq. 5. Note that this optimization must be carried out for each image. | Eq. 5没有一个一般的封闭形式的解决方案,尽管当所有的模型产生一个单一的概率为每个类的解决方案是算术或几何平均值,取决于我们是否使用KL(p, q)或KL(q, p))。我们参数化q = sof tmax(z)(与T = 1),我们使用梯度下降来优化logits z w.r.t eq。注意,必须对每个图像进行这种优化。 |
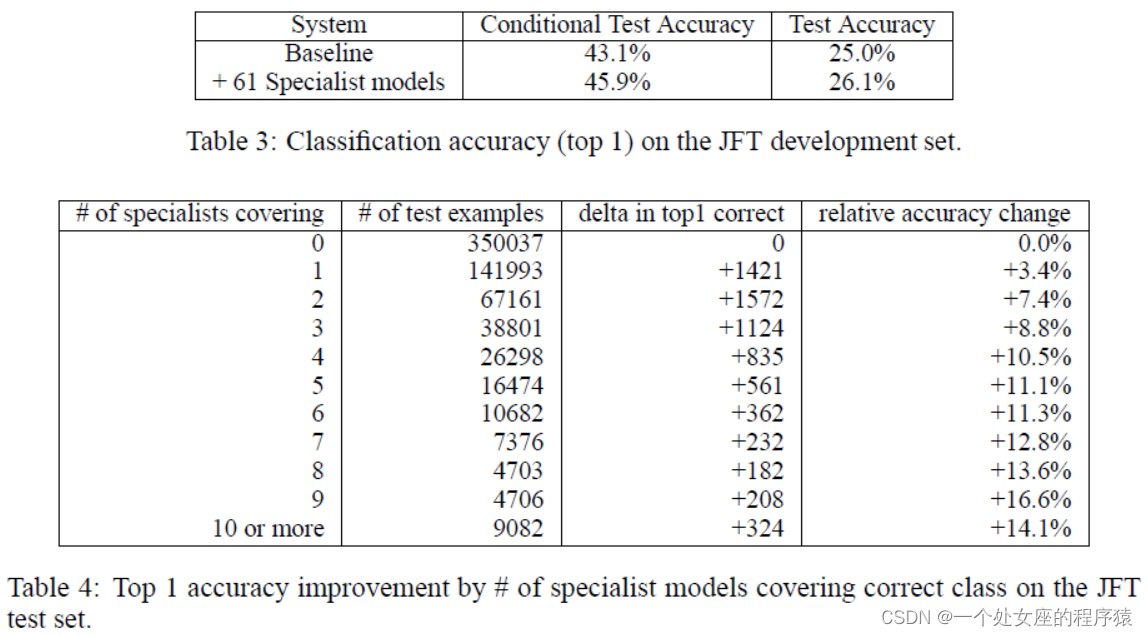
5.5、Results
| Starting from the trained baseline full network, the specialists train extremely fast (a few days in- stead of many weeks for JFT). Also, all the specialists are trained completely independently. Table 3 shows the absolute test accuracy for the baseline system and the baseline system combined with the specialist models. With 61 specialist models, there is a 4.4% relative improvement in test ac- curacy overall. We also report conditional test accuracy, which is the accuracy by only consider |
网站声明:如果转载,请联系本站管理员。否则一切后果自行承担。
- 上周热门
- 如何使用 StarRocks 管理和优化数据湖中的数据? 2944
- 【软件正版化】软件正版化工作要点 2863
- 统信UOS试玩黑神话:悟空 2823
- 信刻光盘安全隔离与信息交换系统 2717
- 镜舟科技与中启乘数科技达成战略合作,共筑数据服务新生态 1251
- grub引导程序无法找到指定设备和分区 1217
- 华为全联接大会2024丨软通动力分论坛精彩议程抢先看! 163
- 点击报名 | 京东2025校招进校行程预告 162
- 2024海洋能源产业融合发展论坛暨博览会同期活动-海洋能源与数字化智能化论坛成功举办 160
- 华为纯血鸿蒙正式版9月底见!但Mate 70的内情还得接着挖... 157
- 本周热议
- 我的信创开放社区兼职赚钱历程 40
- 今天你签到了吗? 27
- 信创开放社区邀请他人注册的具体步骤如下 15
- 如何玩转信创开放社区—从小白进阶到专家 15
- 方德桌面操作系统 14
- 我有15积分有什么用? 13
- 用抖音玩法闯信创开放社区——用平台宣传企业产品服务 13
- 如何让你先人一步获得悬赏问题信息?(创作者必看) 12
- 2024中国信创产业发展大会暨中国信息科技创新与应用博览会 9
- 中央国家机关政府采购中心:应当将CPU、操作系统符合安全可靠测评要求纳入采购需求 8
