ML之kNNC:基于iris莺尾花数据集(PCA处理+三维散点图可视化)利用kNN算法实现分类预测

ML之kNNC:基于iris莺尾花数据集(PCA处理+三维散点图可视化)利用kNN算法实现分类预测
目录
基于iris莺尾花数据集(PCA处理+三维散点图可视化)利用kNN算法实现分类预测
相关文章
ML之kNNC:基于iris莺尾花数据集(PCA处理+三维散点图可视化)利用kNN算法实现分类预测
ML之kNNC:基于iris莺尾花数据集(PCA处理+三维散点图可视化)利用kNN算法实现分类预测实现
基于iris莺尾花数据集(PCA处理+三维散点图可视化)利用kNN算法实现分类预测
设计思路

输出结果
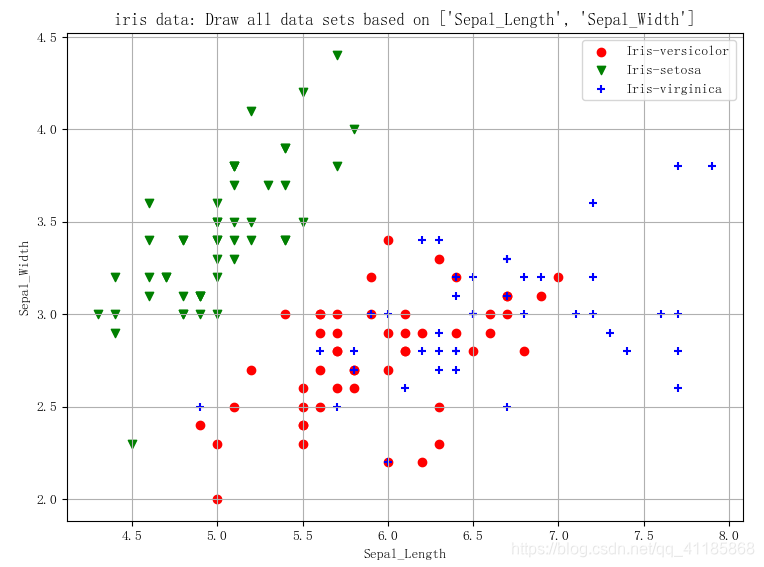
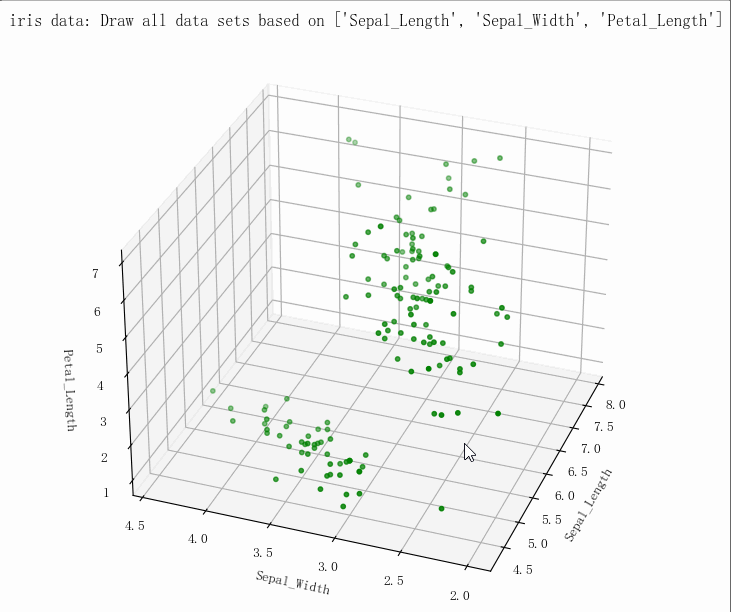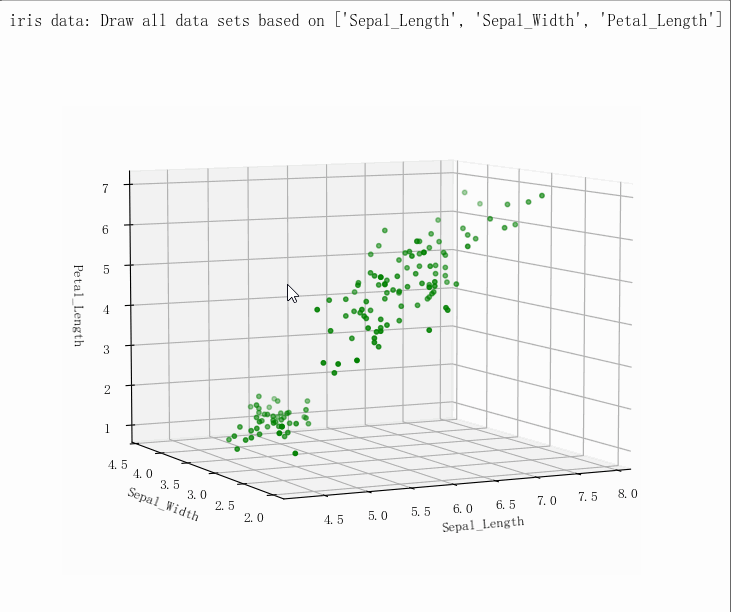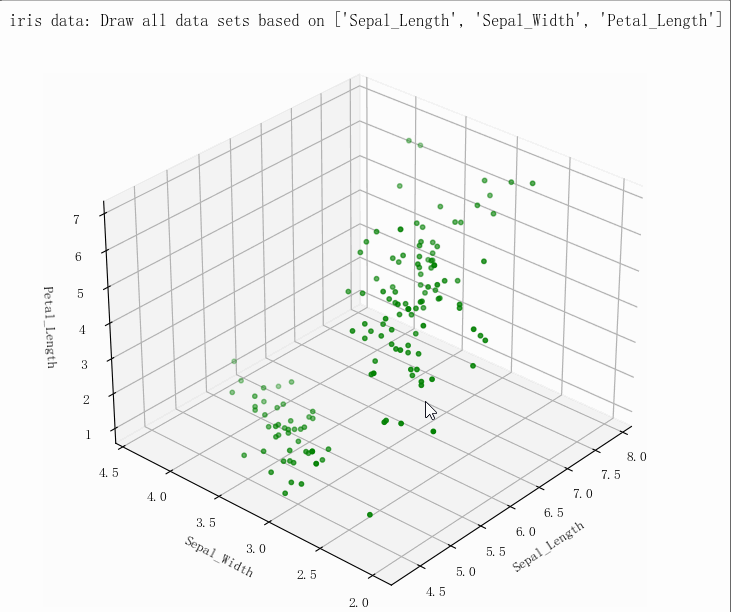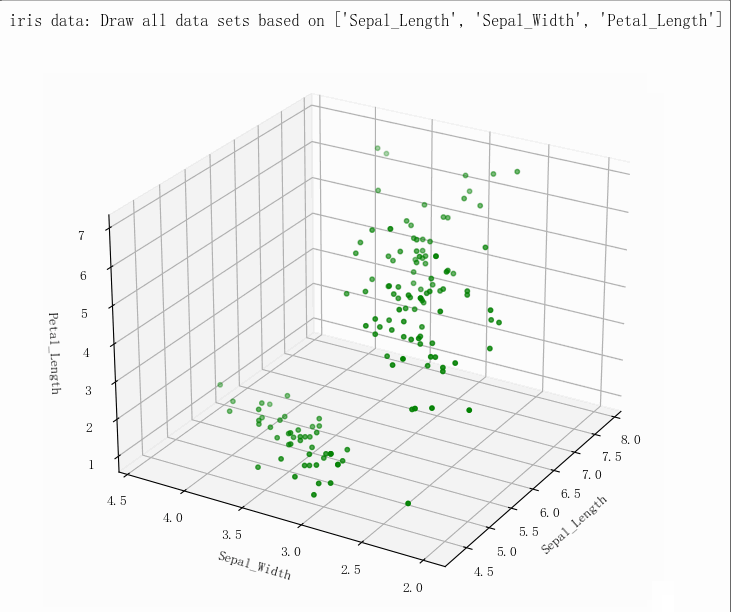
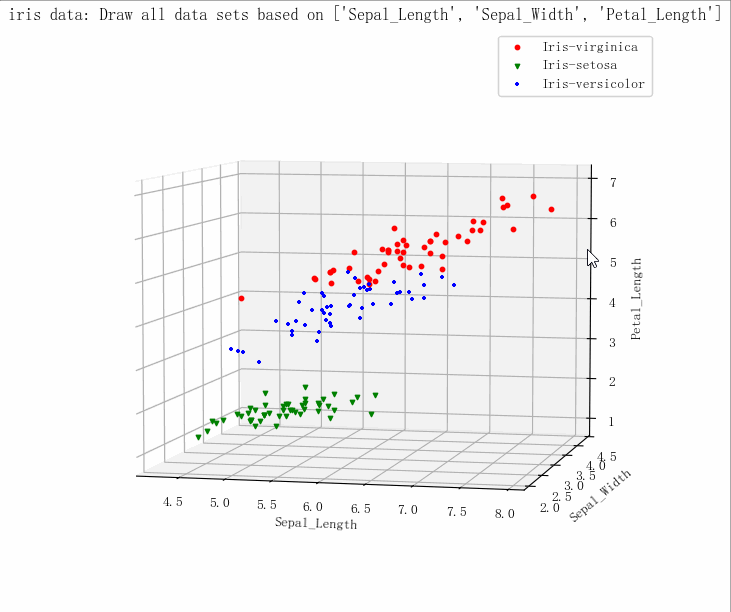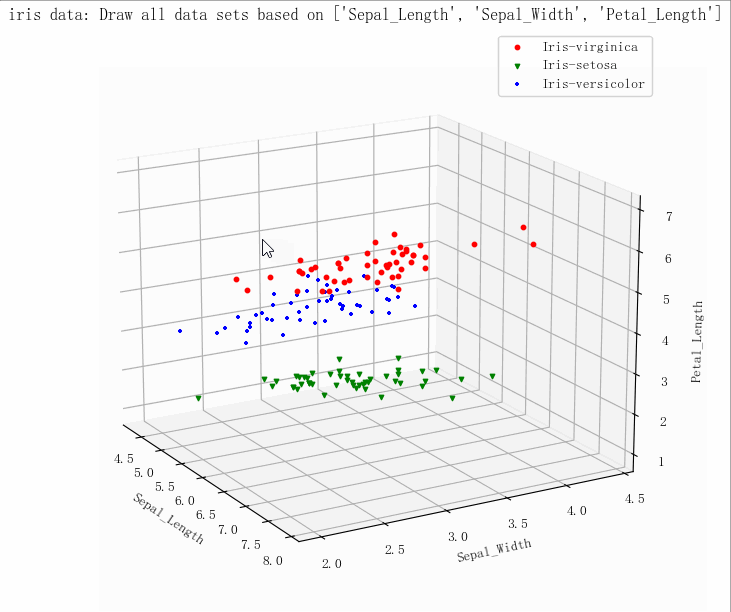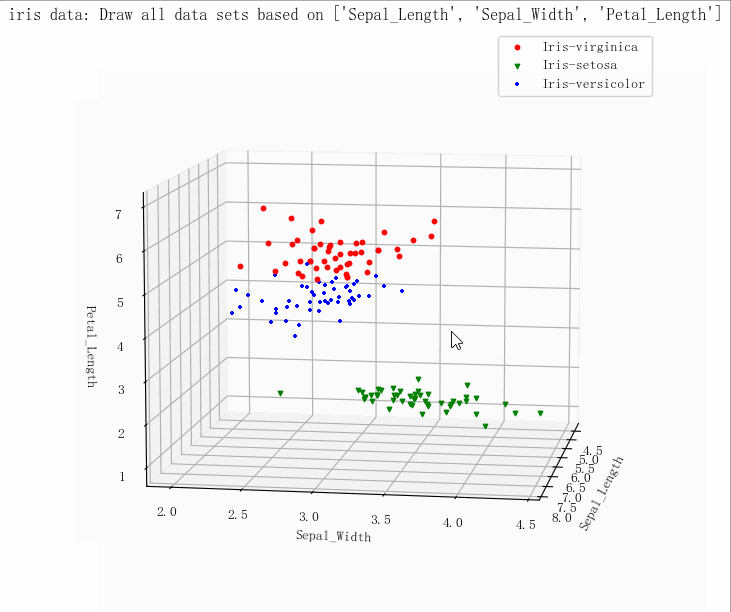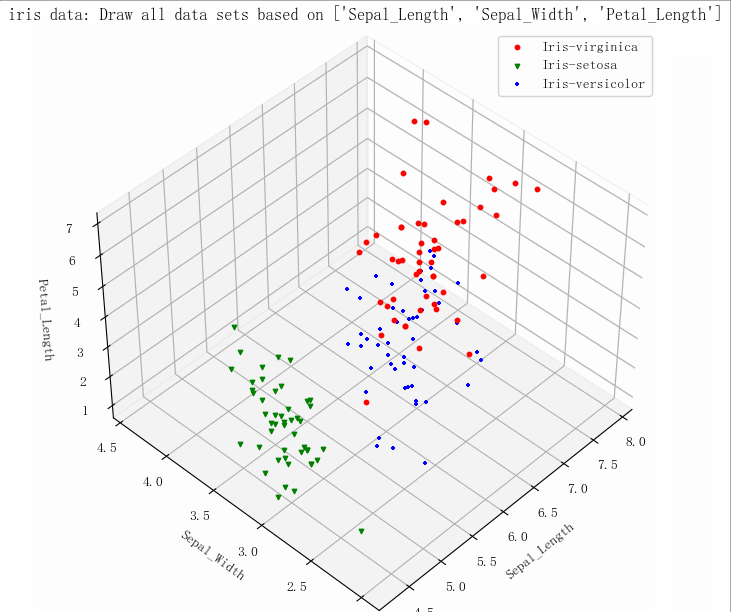
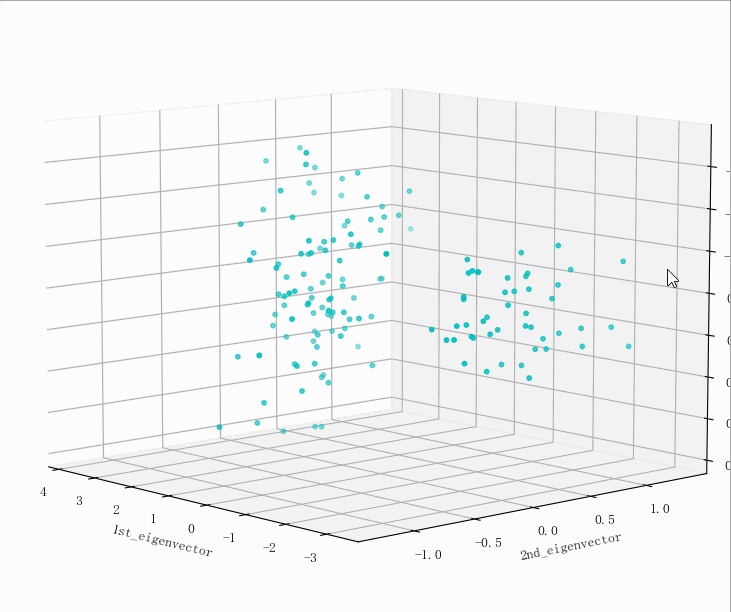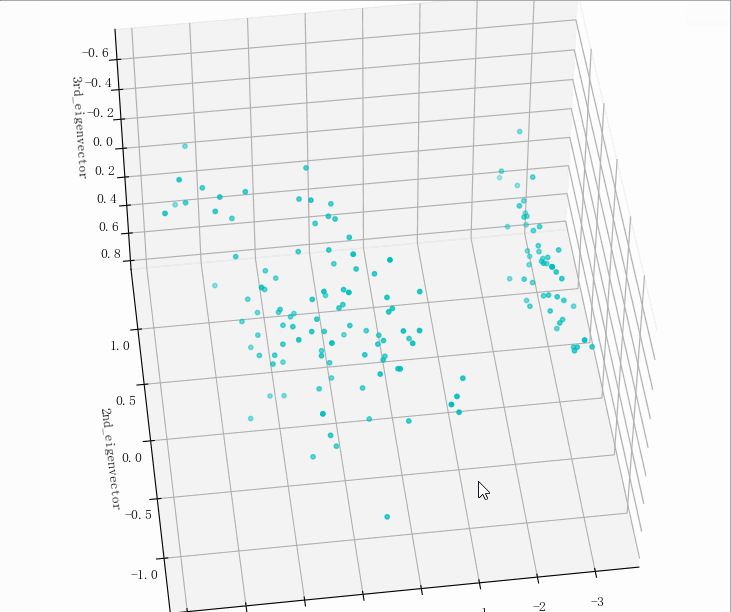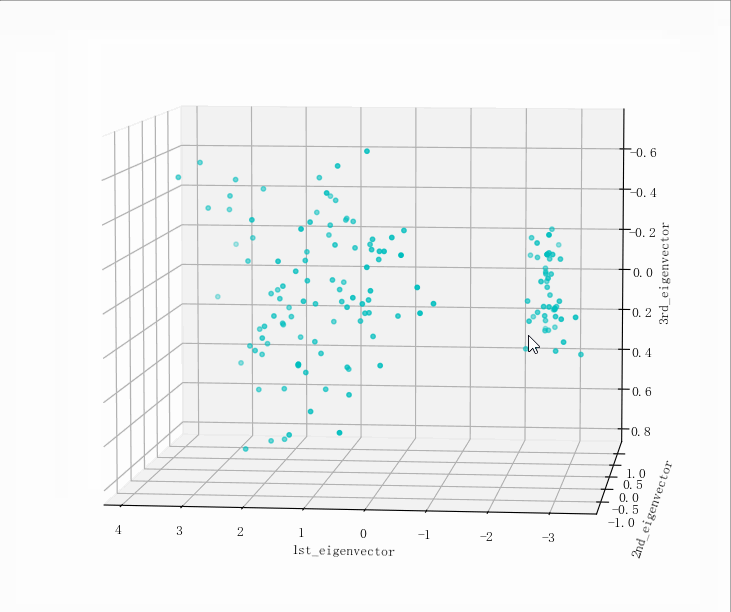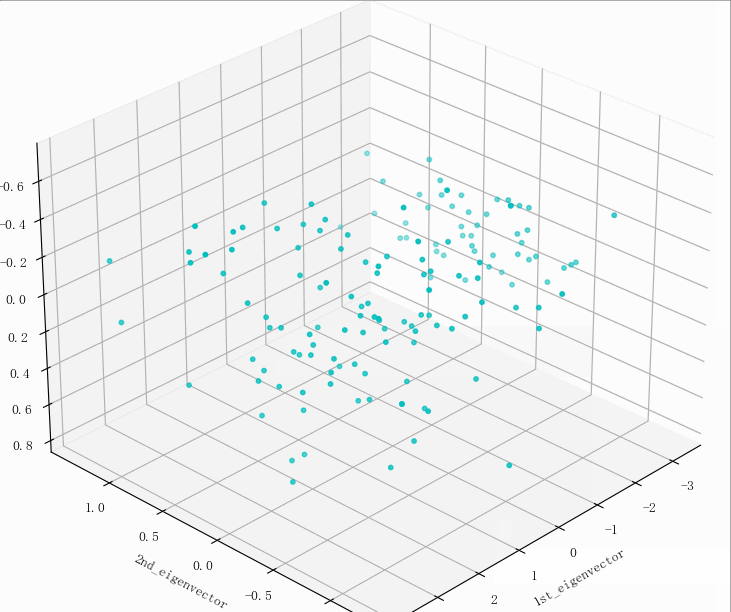
- (149, 5)
- 5.1 3.5 1.4 0.2 Iris-setosa
- 0 4.9 3.0 1.4 0.2 Iris-setosa
- 1 4.7 3.2 1.3 0.2 Iris-setosa
- 2 4.6 3.1 1.5 0.2 Iris-setosa
- 3 5.0 3.6 1.4 0.2 Iris-setosa
- 4 5.4 3.9 1.7 0.4 Iris-setosa
- (149, 5)
- Sepal_Length Sepal_Width Petal_Length Petal_Width type
- 0 4.5 2.3 1.3 0.3 Iris-setosa
- 1 6.3 2.5 5.0 1.9 Iris-virginica
- 2 5.1 3.4 1.5 0.2 Iris-setosa
- 3 6.3 3.3 6.0 2.5 Iris-virginica
- 4 6.8 3.2 5.9 2.3 Iris-virginica
- 切分点: 29
- label_classes: ['Iris-setosa', 'Iris-versicolor', 'Iris-virginica']
- kNNDIY模型预测,基于原数据: 0.95
- kNN模型预测,基于原数据预测: [0.96666667 1. 0.93333333 1. 0.93103448]
- kNN模型预测,原数据PCA处理后: [1. 0.96 0.95918367]
核心代码
- class KNeighborsClassifier Found at: sklearn.neighbors._classification
-
- class KNeighborsClassifier(NeighborsBase, KNeighborsMixin,
- SupervisedIntegerMixin, ClassifierMixin):
- """Classifier implementing the k-nearest neighbors vote.
-
- Read more in the :ref:`User Guide <classification>`.
-
- Parameters
- ----------
- n_neighbors : int, default=5
- Number of neighbors to use by default for :meth:`kneighbors` queries.
-
- weights : {'uniform', 'distance'} or callable, default='uniform'
- weight function used in prediction. Possible values:
-
- - 'uniform' : uniform weights. All points in each neighborhood
- are weighted equally.
- - 'distance' : weight points by the inverse of their distance.
- in this case, closer neighbors of a query point will have a
- greater influence than neighbors which are further away.
- - [callable] : a user-defined function which accepts an
- array of distances, and returns an array of the same shape
- containing the weights.
-
- algorithm : {'auto', 'ball_tree', 'kd_tree', 'brute'}, default='auto'
- Algorithm used to compute the nearest neighbors:
-
- - 'ball_tree' will use :class:`BallTree`
- - 'kd_tree' will use :class:`KDTree`
- - 'brute' will use a brute-force search.
- - 'auto' will attempt to decide the most appropriate algorithm
- based on the values passed to :meth:`fit` method.
-
- Note: fitting on sparse input will override the setting of
- this parameter, using brute force.
-
- leaf_size : int, default=30
- Leaf size passed to BallTree or KDTree. This can affect the
- speed of the construction and query, as well as the memory
- required to store the tree. The optimal value depends on the
- nature of the problem.
-
- p : int, default=2
- Power parameter for the Minkowski metric. When p = 1, this is
- equivalent to using manhattan_distance (l1), and euclidean_distance
- (l2) for p = 2. For arbitrary p, minkowski_distance (l_p) is used.
-
- metric : str or callable, default='minkowski'
- the distance metric to use for the tree. The default metric is
- minkowski, and with p=2 is equivalent to the standard Euclidean
- metric. See the documentation of :class:`DistanceMetric` for a
- list of available metrics.
- If metric is "precomputed", X is assumed to be a distance matrix and
- must be square during fit. X may be a :term:`sparse graph`,
- in which case only "nonzero" elements may be considered neighbors.
-
- metric_params : dict, default=None
- Additional keyword arguments for the metric function.
-
- n_jobs : int, default=None
- The number of parallel jobs to run for neighbors search.
- ``None`` means 1 unless in a :obj:`joblib.parallel_backend` context.
- ``-1`` means using all processors. See :term:`Glossary <n_jobs>`
- for more details.
- Doesn't affect :meth:`fit` method.
-
- Attributes
- ----------
- classes_ : array of shape (n_classes,)
- Class labels known to the classifier
-
- effective_metric_ : str or callble
- The distance metric used. It will be same as the `metric` parameter
- or a synonym of it, e.g. 'euclidean' if the `metric` parameter set to
- 'minkowski' and `p` parameter set to 2.
-
- effective_metric_params_ : dict
- Additional keyword arguments for the metric function. For most
- metrics
- will be same with `metric_params` parameter, but may also contain the
- `p` parameter value if the `effective_metric_` attribute is set to
- 'minkowski'.
-
- outputs_2d_ : bool
- False when `y`'s shape is (n_samples, ) or (n_samples, 1) during fit
- otherwise True.
-
- Examples
- --------
- >>> X = [[0], [1], [2], [3]]
- >>> y = [0, 0, 1, 1]
- >>> from sklearn.neighbors import KNeighborsClassifier
- >>> neigh = KNeighborsClassifier(n_neighbors=3)
- >>> neigh.fit(X, y)
- KNeighborsClassifier(...)
- >>> print(neigh.predict([[1.1]]))
- [0]
- >>> print(neigh.predict_proba([[0.9]]))
- [[0.66666667 0.33333333]]
-
- See also
- --------
- RadiusNeighborsClassifier
- KNeighborsRegressor
- RadiusNeighborsRegressor
- NearestNeighbors
-
- Notes
- -----
- See :ref:`Nearest Neighbors <neighbors>` in the online
- documentation
- for a discussion of the choice of ``algorithm`` and ``leaf_size``.
-
- .. warning::
-
- Regarding the Nearest Neighbors algorithms, if it is found that two
- neighbors, neighbor `k+1` and `k`, have identical distances
- but different labels, the results will depend on the ordering of the
- training data.
-
- https://en.wikipedia.org/wiki/K-nearest_neighbor_algorithm
- """
- -meta"> @_deprecate_positional_args
- def __init__(self, n_neighbors=5,
- *, weights='uniform', algorithm='auto', leaf_size=30,
- p=2, metric='minkowski', metric_params=None, n_jobs=None, **
- kwargs):
- super().__init__(n_neighbors=n_neighbors, algorithm=algorithm,
- leaf_size=leaf_size, metric=metric, p=p, metric_params=metric_params,
- n_jobs=n_jobs, **kwargs)
- self.weights = _check_weights(weights)
-
- def predict(self, X):
- """Predict the class labels for the provided data.
- Parameters
- ----------
- X : array-like of shape (n_queries, n_features), \
- or (n_queries, n_indexed) if metric == 'precomputed'
- Test samples.
- Returns
- -------
- y : ndarray of shape (n_queries,) or (n_queries, n_outputs)
- Class labels for each data sample.
- """
- X = check_array(X, accept_sparse='csr')
- neigh_dist, neigh_ind = self.kneighbors(X)
- classes_ = self.classes_
- _y = self._y
- if not self.outputs_2d_:
- _y = self._y.reshape((-1, 1))
- classes_ = [self.classes_]
- n_outputs = len(classes_)
- n_queries = _num_samples(X)
- weights = _get_weights(neigh_dist, self.weights)
- y_pred = np.empty((n_queries, n_outputs), dtype=classes_[0].
- dtype)
- for k, classes_k in enumerate(classes_):
- if weights is None:
- mode, _ = stats.mode(_y[neigh_indk], axis=1)
- else:
- mode, _ = weighted_mode(_y[neigh_indk], weights, axis=1)
- mode = np.asarray(mode.ravel(), dtype=np.intp)
- y_pred[:k] = classes_k.take(mode)
-
- if not self.outputs_2d_:
- y_pred = y_pred.ravel()
- return y_pred
-
- def predict_proba(self, X):
- """Return probability estimates for the test data X.
- Parameters
- ----------
- X : array-like of shape (n_queries, n_features), \
- or (n_queries, n_indexed) if metric == 'precomputed'
- Test samples.
- Returns
- -------
- p : ndarray of shape (n_queries, n_classes), or a list of n_outputs
- of such arrays if n_outputs > 1.
- The class probabilities of the input samples. Classes are ordered
- by lexicographic order.
- """
- X = check_array(X, accept_sparse='csr')
- neigh_dist, neigh_ind = self.kneighbors(X)
- classes_ = self.classes_
- _y = self._y
- if not self.outputs_2d_:
- _y = self._y.reshape((-1, 1))
- classes_ = [self.classes_]
- n_queries = _num_samples(X)
- weights = _get_weights(neigh_dist, self.weights)
- if weights is None:
- weights = np.ones_like(neigh_ind)
- all_rows = np.arange(X.shape[0])
- probabilities = []
- for k, classes_k in enumerate(classes_):
- pred_labels = _y[:k][neigh_ind]
- proba_k = np.zeros((n_queries, classes_k.size))
- a simple ':' index doesn't work right
- for i, idx in enumerate(pred_labels.T): loop is O(n_neighbors)
- proba_k[all_rowsidx] += weights[:i]
-
- normalize 'votes' into real [0,1] probabilities
- normalizer = proba_k.sum(axis=1)[:np.newaxis]
- normalizer[normalizer == 0.0] = 1.0
- proba_k /= normalizer
- probabilities.append(proba_k)
-
- if not self.outputs_2d_:
- probabilities = probabilities[0]
- return probabilities
网站声明:如果转载,请联系本站管理员。否则一切后果自行承担。
赞同 0
评论 0 条
- 上周热门
- 如何使用 StarRocks 管理和优化数据湖中的数据? 2672
- 【软件正版化】软件正版化工作要点 2637
- 统信UOS试玩黑神话:悟空 2532
- 信刻光盘安全隔离与信息交换系统 2216
- 镜舟科技与中启乘数科技达成战略合作,共筑数据服务新生态 1092
- grub引导程序无法找到指定设备和分区 743
- WPS City Talk · 校招西安站来了! 15
- 金山办公2024算法挑战赛 | 报名截止日期更新 15
- 看到某国的寻呼机炸了,就问你用某水果手机发抖不? 14
- 有在找工作的IT人吗? 13
- 本周热议
- 我的信创开放社区兼职赚钱历程 40
- 今天你签到了吗? 27
- 信创开放社区邀请他人注册的具体步骤如下 15
- 如何玩转信创开放社区—从小白进阶到专家 15
- 方德桌面操作系统 14
- 我有15积分有什么用? 13
- 用抖音玩法闯信创开放社区——用平台宣传企业产品服务 13
- 如何让你先人一步获得悬赏问题信息?(创作者必看) 12
- 2024中国信创产业发展大会暨中国信息科技创新与应用博览会 9
- 中央国家机关政府采购中心:应当将CPU、操作系统符合安全可靠测评要求纳入采购需求 8
热门标签更多
