本文继续体验AntDB-S流式数据库的,AntDB-S目前还未开放社区版,可以联系AntDB小助手进行体验。
流式数据库是把流处理引擎的能力合并到数据库内核,与数据库SQL引擎、存储引擎融合在一起,完全以数据库的习惯使用流处理引擎,甚至可以和数据库的功能混合使用。比如流对象与表对象联合JOIN。
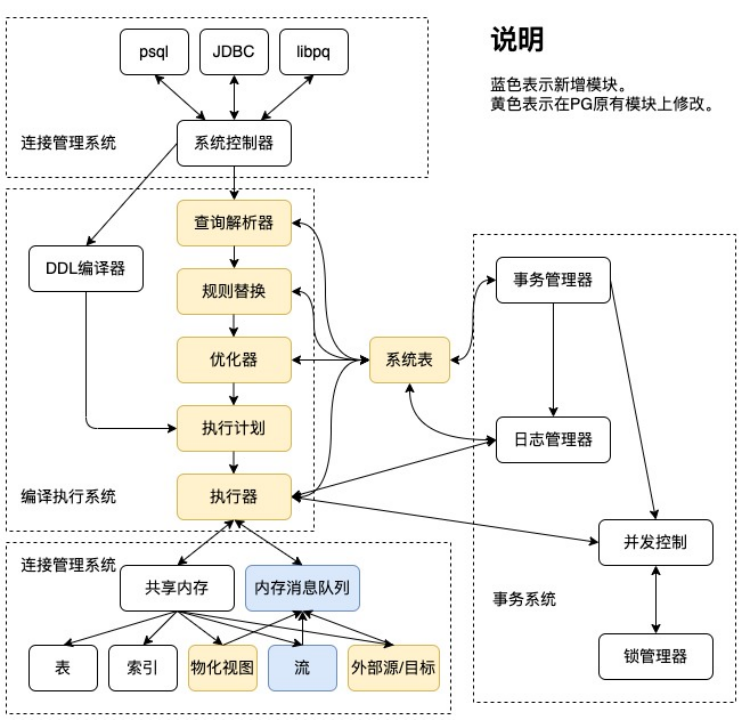
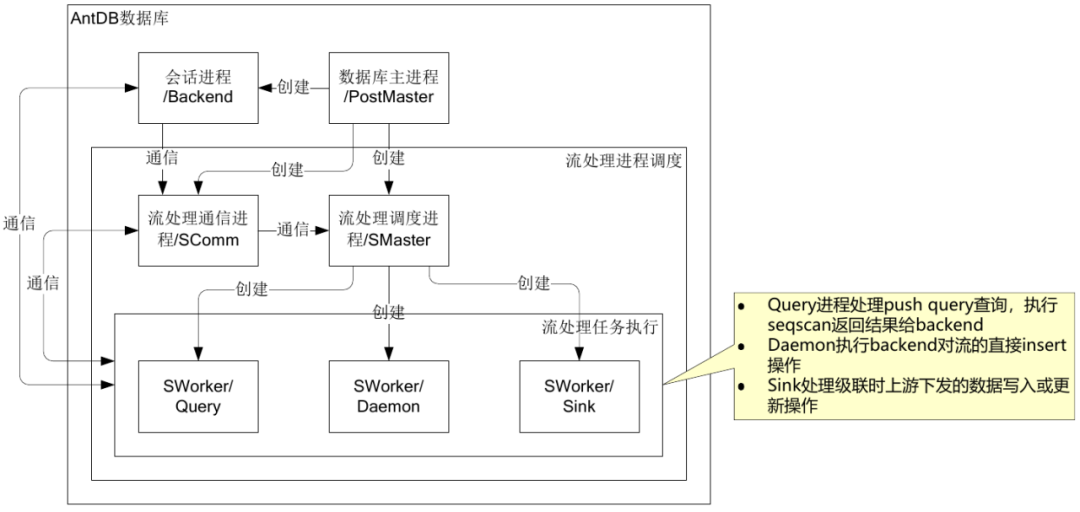
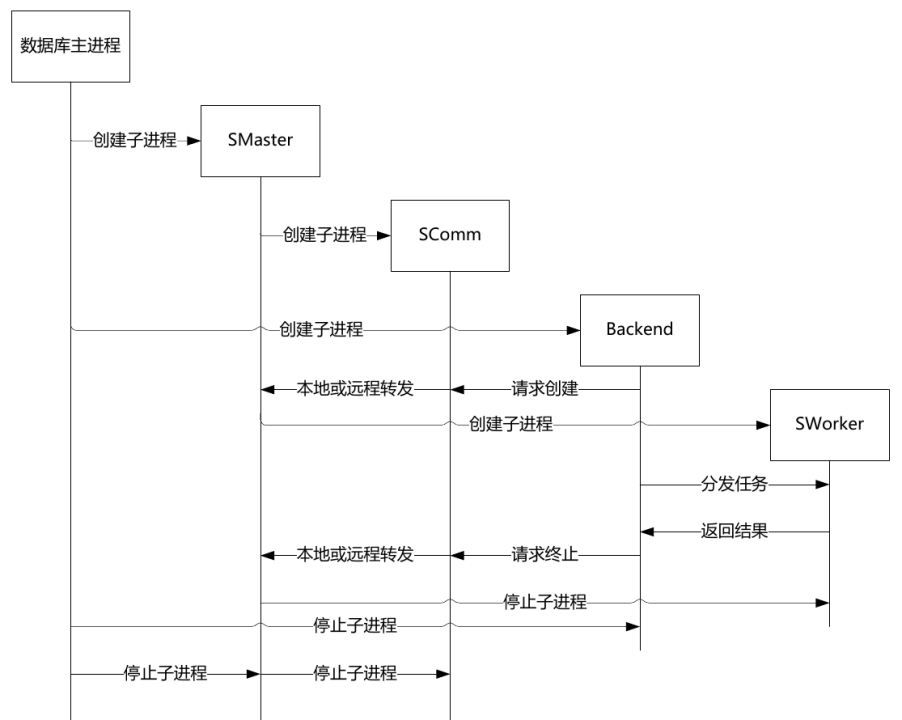
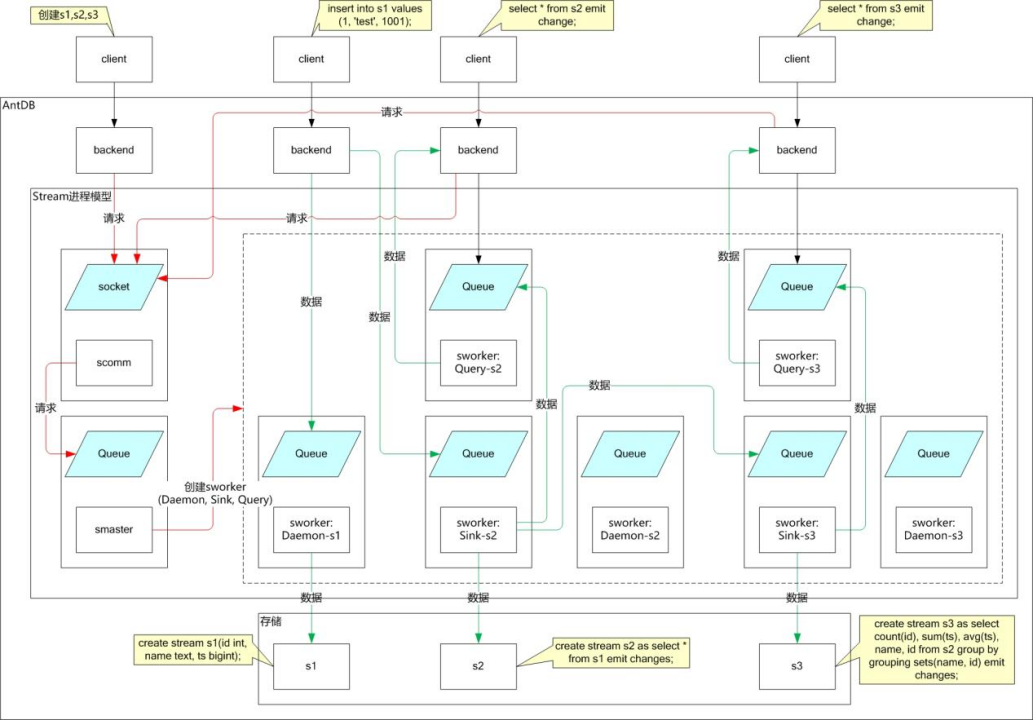
下面几幅图是流式数据库的架构、以及AntDB-S在PostgreSQL数据库基础上进行改造的说明。
从上面几幅图可以看出AntDB-S是在PostgreSQL内核上加入流处理引擎功能,把流数据的存储融合进PostgreSQL的存储引擎,把流处理的进程体系结构融合进PostgreSQL的进程体系结构中。
-
-
学习和维护成本低,只需掌握数据库的使用和维护即可。
-
纯SQL操作,使用简单方便,可快速响应业务的复杂多变性。
-
流数据处理支持数据UPDATE和DELETE、事务ACID以及流对象与表对象联合JOIN。
流
流是一种日益增长(ever-growing)的、并且可能形成无序(但有效)的、本质上无限(essentially infinite)的数据集。
流具有三个特性:数据无边界(Unbounded data)、处理无边界(Unbounded data processing)、低延时(Low-latency)。
流对象
流对象就是流式数据库里用于保存流数据的对象,类似PostgreSQL里的表。流对象具有表的特性,可以对其流数据进行增删改查且满足事务ACID;可以对其流数据进行流式计算;同时具有物化视图的特性,可以从一个流对象的处理结果生成另一个流对象。
PULL和PUSH查询
传统数据库的查询模式称为PULL模式,客户端执行查询语句,数据库把查询结果返回给客户端,结果集全部返回则查询语句执行结束。流对象的查询会长期运行,流数据被处理后实时推送给客户端,这种查询模式不同于传统的数据库查询模式,称之为PUSH模式。
时间概念
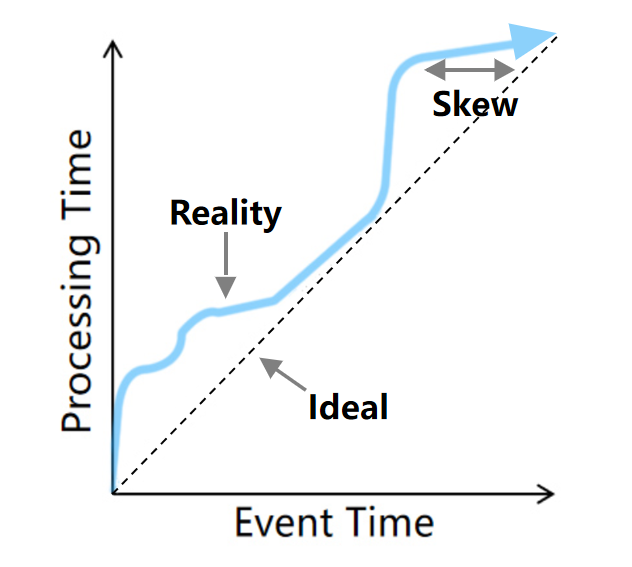
对于流式数据处理,最大的特点就是数据具有时间属性。流数据库根据时间产生的位置把时间划分为三钟类型:事件生成时间(Event Time)、事件接入时间(Ingestion Time)和事件处理时间(Processing Time)。用户可以根据具体业务灵活选择时间类型。
事件生成时间(简称事件时间),是每个独立事件在产生它的设备上发生的时间,这个时间通常在事件进入流数据库前就已经进入事件当中了,即事件时间是从原始的消息中提取的。
事件接入时间(简称入库时间),是数据进入流数据库的时间,它主要依赖接入节点所在主机的系统时钟。
事件处理时间(简称处理时间),是指数据在算子计算过程中获取到的所在主机时间,这个时间是由流数据库自己提供的。
在三种时间概念中,事件时间和处理时间是最重要的。在理想情况下,事件时间等于处理时间,也就是事件一发生就立即被处理。但是在现实世界中,这是不可能发生的。由于网络延时、前端数据积压、流处理本身耗时等因素都会导致事件时间和处理时间不一致,甚至有可能会乱序到达。
针对延迟和乱序的情况,一般建议使用事件时间进行流式处理。对于时间计算精度要求不是特别高的计算场景,如延时比较高的日志数据,可使用处理时间。
窗口
窗口操作是流式系统进行数据流处理的核心,通过窗口操作,可以将一个无限的数据流拆分成很多个有限大小的“桶”,然后在这些桶上执行计算。
流式数据库提供了四种窗口定义:滚动窗口、滑动窗口、会话窗口和全局窗口。
-
滚动窗口(Tumbling Window),在时间维度上按照固定长度将无边界数据流切片,彼此紧邻而不交叉的出现,对于一个到来的数据,根据时间属性取得其时间戳,即可计算出它所对应的时间窗口。
-
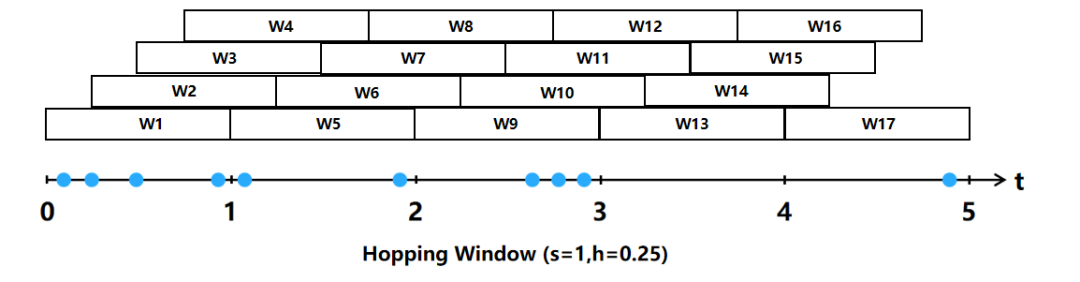
滑动窗口(Hopping Window),也是采用固定相同间隔分配窗口,只不过每个窗口之间有重叠。滑动窗口有两个参数,分别是窗口大小(Window Size)和滑动步长(Slide),后者决定了窗口每次向前滑动的距离。当滑动步长小于窗口大小时,将会发生多个窗口的重叠,即一个元素可能被分配到多个窗口里去。当滑动步长等于窗口大小时,就变成了滚动窗口。当滑动步长大于窗口大小时,就会出现窗口不连续的情况,数据可能不属于任何窗口。
-
会话窗口(Session Window)根据会话间隙(Session Gap)切分不同的窗口,当一个窗口在大于会话间隙的时间内没有接收到新数据时,窗口将关闭。在这种模式下,窗口的长度是可变的,每个窗口的开始和结束时间并不是确定的。
-
全局窗口(Global Window)只有一个窗口且窗口无限大,也就是无窗口定义,因为没有窗口结束时间所以不能等窗口结束后输出统计结果,一有数据立即计算输出结果。
水位线
前面提到流处理系统为实时计算提供了三种时间,即事件时间、入库时间和处理时间。在进行窗口计算,理想情况下事件时间和处理时间一致,但是在实际应用中,由于网络或者系统等外部因素影响,事件数据往往不能及时到达流处理系统,从而造成数据乱序或者延迟到达等问题。针对这两个问题,流数据库主要采用了以水位线(Watermater)为核心的机制来应对。正确地处理乱序事件,通常是结合窗口和水位线这两种机制来实现的。
在流处理过程中,从时间产生,到流经数据库,到流经算子,中间是有一个过程和时间的。虽然在大部分情况下,流到算子的数据都是按照事件产生的时间顺序到达的,但是也不排除由于网络、系统等原因,导致乱序的产生和迟到数据。但是对于迟到数据,不能无限期地等下去,必须要有个机制来保证在经过一个特定的时间后,触发窗口计算。此时由水位线来发挥作用,它表示当达到水位线后,在水位线之前的数据已经全部到达(即使后面还有延迟的数据),系统可以触发相应的窗口计算。也就是说,只有水位线越过窗口对应的结束时间,窗口才会关闭和计算。只有以下两个条件同时成立,才会触发窗口计算。
-
-
条件T2:在[窗口开始时间,窗口结束时间)中有数据存在。
在理想情况下,水位线应该与处理时间一致,并且处理时间与事件时间只相差常数时间甚至为0。当水位线与处理时间完全重合时,就意味着消息产生后马上被处理,不存在消息迟到的情况。然而,由于网络拥塞或系统原因,消息尝尝存在迟到的情况,因此,在设置水位线时,总是考虑一定的延时,从而给予迟到的数据一些机会。具体的延迟大小由用户根据业务情况在流处理SQL语句中指定。
allowedLateness
在默认情况下,当水位线超过窗口结束时间后,再有之前的数据到达时,这些数据会被删除。为了避免有些迟到的数据被删除,产生了allowedLateness的概念。简单来讲,allowedLateness就是针对事件时间而言,对于水位线超过窗口结束时间后,还允许有一段时间(也是以时间来衡量)来等待之前的数据到达,以便再次处理这些数据。在默认情况下,如果没有在流处理SQL语句中指定allowedLateness,那么它的默认值是0,即对于水位线超过窗口结束时间后,如果还有属于此窗口的数据到达时,这些数据就会被删除。
另外,对于窗口计算,如果没有设置allowedLateness,窗口触发计算以后就会被销毁;设置了allowedLateness以后,只有水位线大于“窗口结束时间 + allowedLateness”时,窗口才会被销毁。
1.连接数据库
psql -h x.x.x.x -d postgres -P pager=off
-P pager=off表示关闭翻页显示,流式查询需要加上。
create database mydb;
\c mydb
2.创建流对象
流对象为流数据的入口点,下面创建流对象instructor
CREATE STREAM instructor (id text, name text, dept_name text, salary float);
STREAM关键字表示创建流对象,流对象也具备流式物化视图的能力。
例如从流对象instructor过滤年薪80000美元的流数据物化成super_instructor:
CREATE STREAM super_instructor AS SELECT * FROM instructor WHERE salary >= 80000 EMIT CHANGES;
demodb=# \dt
List of relations
Schema | Name | Type | Owner
--------+------------------+--------+-------
public | instructor | stream | demo
public | super_instructor | stream | demo
(2 rows)
3.删除流对象
DROP STREAM super_instructor;
4.往流对象插入数据
INSERT INTO instructor VALUES('10101', 'Srinivasan', 'Comp. Sci.', 65000);
INSERT INTO instructor VALUES('12121', 'Wu', 'Finance', 90000);
INSERT INTO instructor VALUES('15151', 'Mozart', 'Music', 40000);
INSERT INTO instructor VALUES('22222', 'Einstein', 'Physics', 95000);
INSERT INTO instructor VALUES('32343', 'El Said', 'History', 60000);
5.查询流对象
流对象的查询操作包括:传统的PULL模式查询以及新增的PUSH模式查询。
-
PULL模式把流对象当做表对象处理,查询语法和表的查询一样。
-
PUSH模式查询,流对象的查询长期运行着,一旦有增量数据立即执行后续的查询操作。
SELECT * FROM instructor;
SELECT * FROM instructor WHERE salary >= 80000 EMIT CHANGES;
当其它进程往instructor流对象插数据,PUSH查询会实时显示增量处理结果。
6.修改流对象数据
先使用带pg_state(xmax)的PUSH查询显示流数据状态
SELECT pg_state(xmax),* FROM instructor WHERE salary >= 80000 EMIT CHANGES;
UPDATE instructor SET salary = 98000 WHERE id='22222';
此时PUSH查询显示两条增量数据,一条pg_state状态为’-‘的老数据,表示删除的老数据;一条pg_state状态为’+'的新数据,表示新增的数据。
7.删除流对象数据
同样使用pg_state(xmax)的PUSH查询显示流数据状态
DELETE FROM instructor WHERE id='22222';
此时PUSH查询显示一条pg_state状态为’-'的老数据,表示删除老数据。
8.常规聚合
常规聚集就是全局窗口聚集,和普通窗口聚集表现形式不一样,常规聚集因为窗口无限大,所以聚集结果无需显示窗口开始时间和结束时间。
SELECT count(id), sum(salary), dept_name
FROM instructor
GROUP BY dept_name
EMIT CHANGES;
例如:把各个各个科系教师的人数和薪资总额实时统计结果物化成dept_cost流对象
CREATE STREAM dept_cost
AS
SELECT count(id), sum(salary), dept_name
FROM instructor
GROUP BY dept_name EMIT CHANGES;
9.窗口聚合
前面流处理基本术语介绍过窗口操作,可以将一个无限的数据流拆分成很多个有限大小的“桶”,然后在这些桶上执行计算。根据窗口定义可以分为:滚动窗口、滑动窗口、会话窗口、全局窗口。
全局窗口上面已经介绍过,会话窗口暂不支持,滚动窗口和滑动窗口的流式聚集语法如下:
SELECT expression [ [ AS ] output_name ] [, ...] ,
window_begin(*) [[ AS ] output_name,
window_end(*) [[AS] output_name]
FROM <stream_name> [ WHERE condition ]
GROUP BY grouping_element
[ HAVING condition ]
[ { TUMBLE ( event_time_field, <window_size> ) | HOP ( event_time_field, <window_size>, <slide> ) }
[ { WATERMARK | DELAY } <watermark_size>]
EMIT CHANGES]
<window_size> <slide> <watermark_size> are interval 'quantity unit'
其中窗口的大小、步长、水位线都是以INTERVAL ‘quantity unit’ 间隔时长表示,单位支持如下简称或全称:
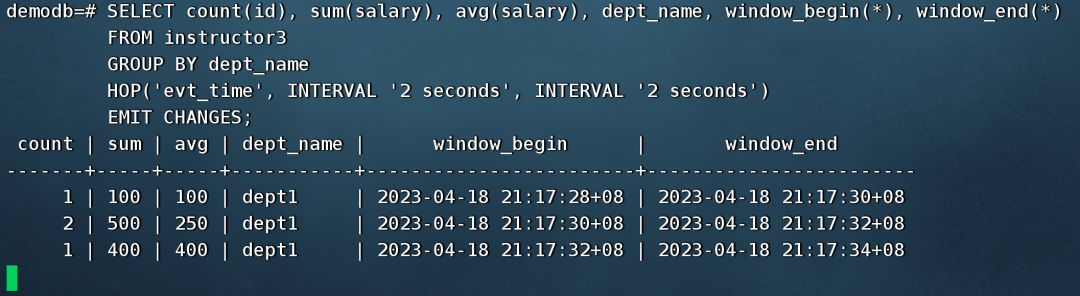
滚动窗口示例:每隔10秒实时统计各个科系新增教师的人数、薪资总额和平均薪资,延后5秒输出结果。
CREATE STREAM instructor2 (
id text,
name text,
dept_name text,
salary float,
evt_time timestamp with time zone default now()
);
指定滚动窗口大小为10秒,水位线5秒,按科系统计每个窗口周期内新增教师的人数、薪资总额和平均薪资。
SELECT count(id), sum(salary), avg(salary), dept_name, window_begin(*), window_end(*)
FROM instructor2
GROUP BY dept_name
TUMBLE('evt_time', INTERVAL '10 seconds')
WATERMARK INTERVAL '5s'
EMIT CHANGES;
模拟流数据接入,一条一条往instructor2插入数据,看窗口聚集的输出结果。
INSERT INTO instructor2(id, name, dept_name, salary) VALUES('33456', 'Gold', 'Physics', 87000);
SELECT pg_sleep(3);
INSERT INTO instructor2(id, name, dept_name, salary) VALUES('45565', 'Katz', 'Comp. Sci.', 75000);
SELECT pg_sleep(11);
INSERT INTO instructor2(id, name, dept_name, salary) VALUES('22222', 'Einstein', 'Physics', 95000);
CREATE STREAM instructor3 (
id text, name text,
dept_name text,
salary float,
evt_time timestamp with time zone default now()
);
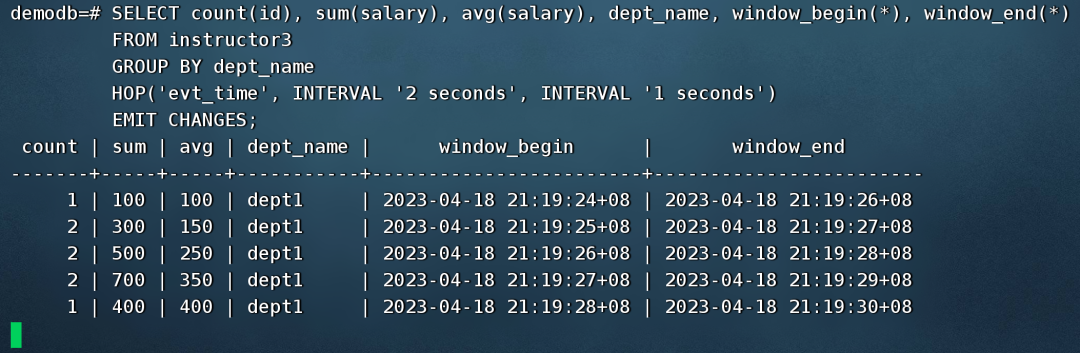
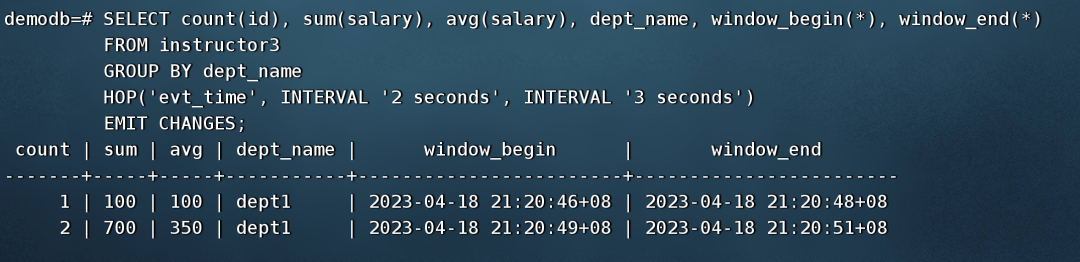
指定滑动窗口大小为3秒(第一个间隔类型参数),滑动步长为3秒(第二个间隔类型参数),按科系统计每个窗口周期内新增教师的人数、薪资总额和平均薪资。
SELECT count(id), sum(salary), avg(salary), dept_name, window_begin(*), window_end(*)
FROM instructor3
GROUP BY dept_name
HOP('evt_time', INTERVAL '2 seconds', INTERVAL '3 seconds')
EMIT CHANGES;
模拟流数据接入,每秒一条往instructor3插入数据,看窗口聚集的输出结果。
INSERT INTO instructor3(id, name, dept_name, salary) VALUES('001', 'name1', 'dept1', 100);
SELECT pg_sleep(1);
INSERT INTO instructor3(id, name, dept_name, salary) VALUES('002', 'name2', 'dept1', 200);
SELECT pg_sleep(1);
INSERT INTO instructor3(id, name, dept_name, salary) VALUES('003', 'name3', 'dept1', 300);
SELECT pg_sleep(1);
INSERT INTO instructor3(id, name, dept_name, salary) VALUES('004', 'name4', 'dept1', 400);
SELECT pg_sleep(1);
INSERT INTO instructor3(id, name, dept_name, salary) VALUES('005', 'name5', 'dept1', 500);
...
第二个间隔类型参数滑动步长与第一个间隔类型参数窗口大小相等时,滑动窗口变成了滚动窗口。
第二个间隔类型参数滑动步长小于第一个间隔类型参数窗口大小时,数据元素可能被分配到多个窗口,窗口会出现重叠。
第二个间隔类型参数滑动步长大于第一个间隔类型参数窗口大小时,数据元素可能不属于任何窗口,窗口可能会不连续。
10.流对象和表对象JOIN
流式数据库的JOIN包括流对象与表对象JOIN、流对象与流对象JOIN,当前版本仅支持流表JOIN。
示例:实时查询新增的教师所属的科系以及所在办公楼信息。
CREATE TABLE department(id text, dept_name text, building text, budget float);
INSERT INTO department VALUES('01', 'Biology', 'Watson', 90000), ('02', 'Comp. Sci.', 'Taylor', 100000), ('03', 'Elec. Eng.', 'Taylor', 85000), ('04', 'Finance', 'Painter', 120000), ('05', 'History', 'Painter', 50000), ('06', 'Music', 'Packard', 80000), ('07', 'Physics', 'Watson', 70000);
CREATE STREAM instructor3 (id text, name text, dept_name text, salary float);
教师信息流对象instructor3和科系表department做流表join。
SELECT instructor3.id, name,salary, department.dept_name, building FROM instructor3 JOIN department ON instructor3.dept_name = department.dept_name EMIT CHANGES;
往教师信息流对象instructor3中插数据,看流表join的结果显示
INSERT INTO instructor3 VALUES('12121', 'Wu', 'Finance', 90000);
INSERT INTO instructor3 VALUES('15151', 'Mozart', 'Music', 40000);
AntDB-S流式数据库上手比较容易,技术栈简单,纯SQL操作,简单方便,支持数据UPDATE、DELETE、事务ACID以及流表JOIN。