ML:MLOps系列讲解之《MLOps的定义与发展—你为什么可能想使用机器学习》解读

ML:MLOps系列讲解之《MLOps的定义与发展—你为什么可能想使用机器学习》解读
目录
1、《MLOps的定义与发展—你为什么可能想使用机器学习》解读
1.2、Scenarios of Change That Need to be Managed需要管理的变化的场景
1、《MLOps的定义与发展—你为什么可能想使用机器学习》解读
根据Statista《2019年数字经济指南》,两大趋势将扰乱经济和我们的生活:
- (1)、数据驱动的世界,这与呈指数增长的数字化收集数据量有关。
- (2)、人工智能/机器学习/数据科学的重要性日益增加,它们从大量的数据中获得洞察力。
为了保持一致性,我们将使用术语机器学习(ML),然而,这些概念适用于人工智能和数据科学领域。
每一个机器学习管道都是一组操作,执行这些操作以产生一个模型。ML模型粗略地定义为现实世界过程的数学表示。我们可以将ML模型看作是一个函数,它接受一些输入数据并产生输出(分类、情感分析、推荐或聚类)。每个模型的性能都是通过使用评估指标来评估,例如precision & recall, or accuracy(精确率、召回率、准确性)。
作为一个强大的工具,机器学习可以解决很多实际问题。与任何其他软件工具类似,我们需要确定“正确的nail钉子”(用例或问题),才能使用这个“hammer锤子”(机器学习算法)。
我们对将机器学习纳入软件系统很感兴趣,因为机器学习可以解决一些过于复杂而无法用传统方法解决的问题。对于这类问题,通过机器学习实现的概率(随机)解决方案可能是正确的方法。例如,会话UI中的感知问题可以通过语音识别或情感分析等技术来解决。机器学习(deep learning)似乎是最合适的方法,因为这类问题有大量不同表示形式的元素。另一类适合ML的问题是多参数问题。例如,我们应用机器学习方法来生成股票价格预测,这是股票交易决策的基础。
将模型放到生产环境中意味着您的模型可用于软件系统。实际上,通过部署ML模型,我们可以提供以下功能:
- (1)、推荐:它根据产品描述或用户以前的交互在一个大集合中识别相关的产品。
- (2)、Top-K项选择:它以适合用户的特定顺序组织一组项目(例如搜索结果)。
- (3)、分类:它将输入示例分配给先前定义的类之一(例如“垃圾邮件”/“非垃圾邮件”)。
- (4)、预测:将一些最可能的值赋给相关实体,如股票价值。
- (5)、内容生成:通过学习现有的示例来产生新的内容,例如学习Bach以前的作品来完成Bach chorale cantata(巴赫的赞美诗康塔塔)。
- (6)、问答:它回答一个明确的问题,例如:“这段内容描述了这个图像吗?”
- (7)、自动化:可以是一组自动执行的用户步骤,例如股票交易
- (8)、欺诈和异常检测:识别一个行为或交易是欺诈或可疑的
- (9)、信息提取和注释:用于识别文本中的重要信息,如人名、职位描述、公司和地点。
在下表中,我们总结了ML/AI的能力:
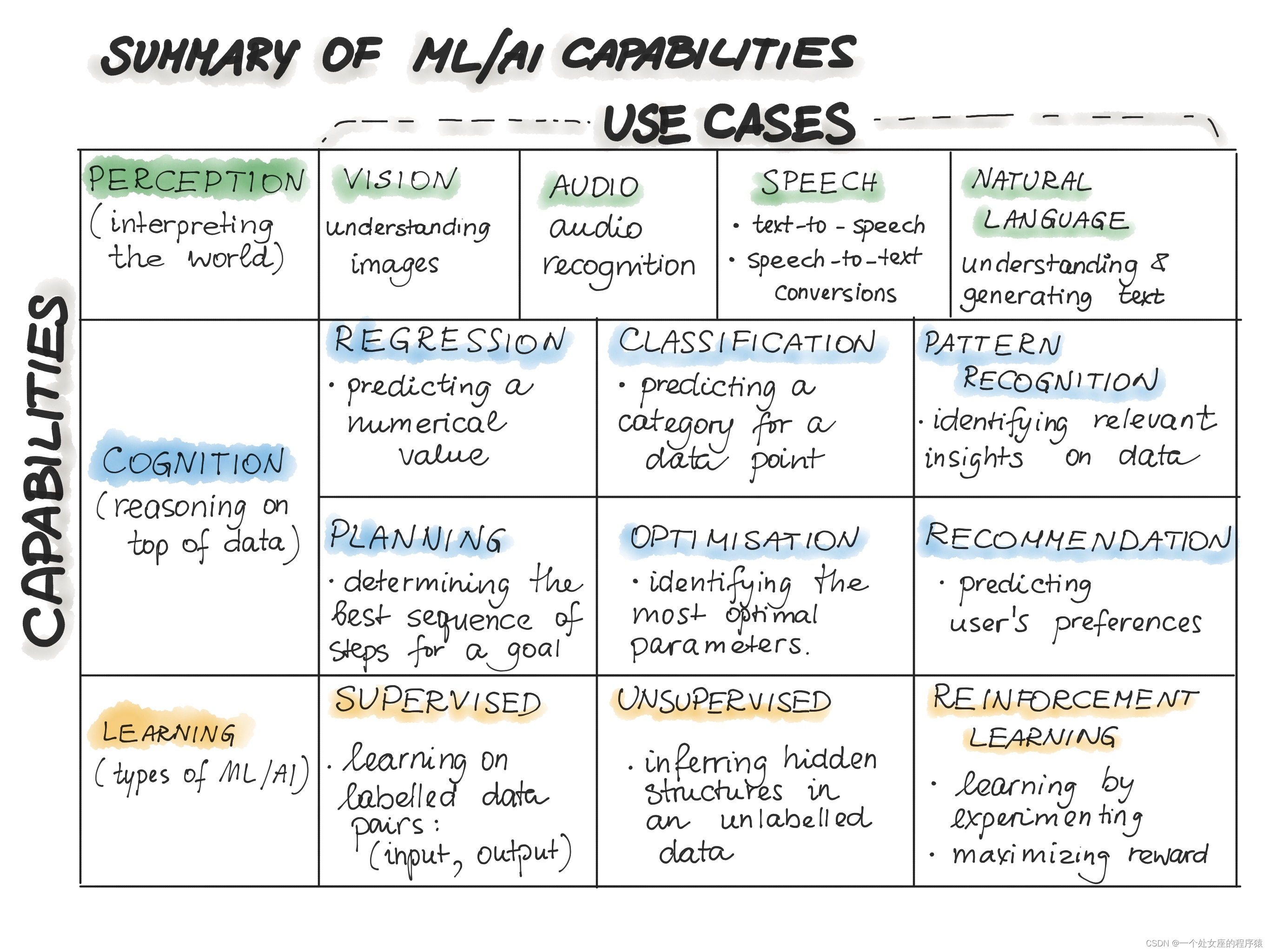
表来源:David Carmona《The AI Organization》
https://learning.oreilly.com/library/view/the-ai-organization/9781492057369/
相关文章
Statista 《Digital Economy Compass 2019》
https://cdn.statcdn.com/download/pdf/DigitalEconomyCompass2019.pdf
1.1、Deployment GapML部署的差距
越来越多的企业正在试验ML。将模型引入现实世界不仅仅是构建它。为了充分利用构建的ML模型,使其可用于我们的核心软件系统,我们需要将训练有素的ML模型合并到核心代码库中。这意味着,我们需要将ML模型部署到生产中。通过部署模型,其他软件系统可以向这些模型提供数据并获得预测,这些预测又被重新填充到软件系统中。因此,只有通过ML模型的部署才能充分发挥ML模型的优势。
然而,根据Algorithmia的一份《2020年企业机器学习状况》报告,许多公司还没有想出如何实现他们的ML/AI目标。因为在ML模型构建和实际部署之间搭建桥梁仍然是一个具有挑战性的任务。在Jupyter Notebook模型中构建ML模型,与将ML模型部署到产生业务价值的生产系统中是有根本区别的。尽管AI预算在增加,但只有22%的使用机器学习的公司成功地将机器学习模型部署到生产中。
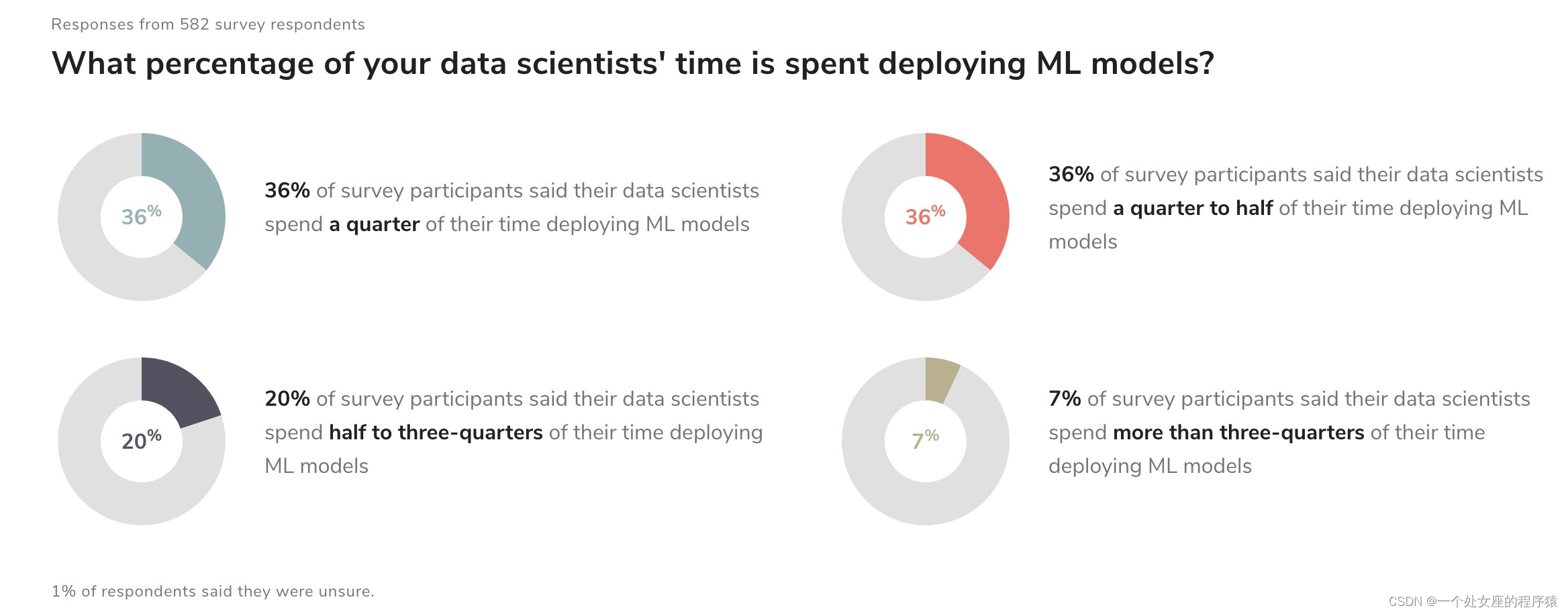
源自Algorithmia公司的《2020 state of enterprise machine learning》
AI:Algorithmia《2021 enterprise trends in machine learning 2021年机器学习的企业趋势》翻译与解读_一个处女座的程序猿-CSDN博客
《2020年企业机器学习状况》报告是基于对近750人的调查,包括机器学习从业者、机器学习项目经理和科技公司高管。一半的受访者回答说,他们的公司需要一周到三个月的时间来部署一个ML模型。大约18%的人表示需要3个月到1年的时间。根据这份报告,“人们在开发ML功能时面临的主要挑战是规模、版本控制、模型可重复性和利益相关者的协调一致。
1.2、Scenarios of Change That Need to be Managed需要管理的变化的场景
出现上述部署差距的原因在于,基于机器学习的应用程序的开发与传统软件的开发有着根本的不同。完整的开发管道包括三个级别的变更:数据、ML模型和代码。这意味着,在基于机器学习的系统中,构建的触发器可能是代码更改、数据更改或模型更改的组合。这也被称为“改变任何事物就改变一切”原则。
在下面,我们列出了机器学习应用中可能发生变化的一些场景:
- (1)、在将ML模型部署到软件系统之后,我们可能会意识到,随着时间的推移,模型开始衰退并出现异常行为,因此我们需要新的数据来重新训练我们的ML模型。
- (2)、在检查可用的数据之后,我们可能会意识到很难获得解决我们之前定义的问题所需的数据,因此我们需要重新制定问题。
- (3)、在ML项目的某些阶段,我们可能会回到过程中,或者收集更多的数据,或者收集不同的数据并重新标记训练数据。这应该会触发ML模型的重新训练。
- (4)、在将模型提供给最终用户之后,我们可能会意识到我们为训练模型所做的假设是错误的,因此我们必须更改我们的模型。
- (5)、有时候,在项目开发过程中,业务目标可能会发生变化,我们决定改变机器学习算法来训练模型。
此外,有三个常见的问题会影响ML模型投入生产后的价值。
- 第一个是数据质量:由于ML模型是建立在数据之上的,它们对传入数据的语义、数量和完整性很敏感。
- 第二种是模型衰减:因为在模型训练期间未看到的真实数据发生了变化,ML模型在生产中的性能随着时间的推移而退化。
- 第三是局部性:当将ML模型转移到新的业务客户时,这些模型已经根据不同的用户统计数据进行了预先训练,根据质量指标可能无法正常工作。
由于ML/AI正在扩展到新的应用和塑造新的行业,因此构建成功的ML项目仍然是一个具有挑战性的任务。如上所示,需要围绕设计、构建和部署ML模型到生产环境中建立有效的实践和流程—MLOps。
1.3、MLOps Definition定义
我们看到了应用机器学习可以解决现实世界中的问题。我们确定了将ML模型投入生产的挑战。最后,我们定义术语MLOps:
术语MLOps被定义为:MLOps是“DevOps方法论的扩展,将机器学习和数据科学资产作为DevOps生态系统的“一等公民”。”(来源:MLOps SIG)。
或者,我们可以使用机器学习工程(MLE)的定义,其中,MLE是使用机器学习和传统软件工程的科学原理、工具和技术来设计和构建复杂的计算系统。MLE包括从数据收集到模型构建的所有阶段,以使模型可供产品或消费者使用。”(由A.Burkov)。
MLOps 与 DevOps 一样,源于这样一种理解,即将 ML 模型开发与交付它的过程(ML 操作)分开会降低整个智能软件的质量、透明度和敏捷性。
相关文章
《MLOps SIG》:
https://github.com/cdfoundation/sig-mlops/blob/master/roadmap/2020/MLOpsRoadmap2020.md
1.4、MLOps Evolution进化
在21世纪初,当企业需要实施机器学习解决方案时,他们使用了供应商的授权软件,如SAS、SPSS和FICO。随着开源软件的兴起和数据的可用性,越来越多的软件从业者开始使用Python或R库来训练ML模型。然而,这些模型在生产中的使用仍然是个问题。随着集装箱化(containerization)技术的兴起,Docker容器和Kubernetes解决了模型的可扩展部署问题。最近,我们看到了这些解决方案向ML部署平台的演变,这些平台覆盖了模型实验、训练、部署和监控的整个迭代。下图显示了MLOps的演化过程。

1.5、The Evolution of MLOps
| Pre-History Age | Proprietary Inference Servers 专有推理服务器 | using proprietary tools to perform modeling and inference SAS SPSS FICO 使用专有工具进行建模和推理 SAS SPSS FICO |
| 2000 Stone Age | The Rise of Open Source Data Science Tools 开源数据科学工具的兴起 | ...attempt to wrap the data science stack in a lightweight web service framework, and put it into production ..尝试将数据科学堆栈包装在轻量级 Web 服务框架中,并将其投入生产 Python: SciPy stack scitkit-learn is TensorFlow etc. R: dplyr ggplot2 I etc. I Spark, H2O, others... |
| 2015 Bronze Age | Containerization to-the-rescue 容器化救援 | Containerization of the "Stone Age" approach, making it easy to scale, robust, etc. “容器化时代”方法的容器化,使其易于扩展、健壮等。 Dockerized 开源 ML 堆栈。 |
| 2018 MLOps Gold Rush Age | "MLOps Platforms" “MLOps 平台” | Dockerized open-source ML stacks Deployed them on-premise or in the cloud via Kubernetes and providing some manageability ("ML Ops"). 通过 Kubernetes 将它们部署在本地或云中,并提供一些可管理性(“ML Ops”)。 |
The content of this site was created by Dr. Larysa Visengeriyeva, Anja Kammer, Isabel Bär, Alexander Kniesz, and Michael Plöd (DDD Advisor). Design made by Sebastian Eberstaller.
It is published under Creative Commons Attribution 4.0 International Public License and can therefore be shared and adapted with attribution ("INNOQ").
网站声明:如果转载,请联系本站管理员。否则一切后果自行承担。
- 上周热门
- 如何使用 StarRocks 管理和优化数据湖中的数据? 2966
- 【软件正版化】软件正版化工作要点 2885
- 统信UOS试玩黑神话:悟空 2856
- 信刻光盘安全隔离与信息交换系统 2743
- 镜舟科技与中启乘数科技达成战略合作,共筑数据服务新生态 1277
- grub引导程序无法找到指定设备和分区 1244
- 华为全联接大会2024丨软通动力分论坛精彩议程抢先看! 169
- 2024海洋能源产业融合发展论坛暨博览会同期活动-海洋能源与数字化智能化论坛成功举办 168
- 点击报名 | 京东2025校招进校行程预告 164
- 华为纯血鸿蒙正式版9月底见!但Mate 70的内情还得接着挖... 161
- 本周热议
- 我的信创开放社区兼职赚钱历程 40
- 今天你签到了吗? 27
- 信创开放社区邀请他人注册的具体步骤如下 15
- 如何玩转信创开放社区—从小白进阶到专家 15
- 方德桌面操作系统 14
- 我有15积分有什么用? 13
- 用抖音玩法闯信创开放社区——用平台宣传企业产品服务 13
- 如何让你先人一步获得悬赏问题信息?(创作者必看) 12
- 2024中国信创产业发展大会暨中国信息科技创新与应用博览会 9
- 中央国家机关政府采购中心:应当将CPU、操作系统符合安全可靠测评要求纳入采购需求 8
