Linux 操作系统状态查看及调优


- 查看 Memory 运行状态相关工具
- 查看 IO 运行状态相关工具
- 查看 Network 运行状态相关工具
- 查看系统整体运行状态
-
系统调优思路
-
性能优化就是找到系统处理中的瓶颈以及去除这些的过程,性能优化其实是对 OS 各子系统达到一种平衡的定义。
- 具体步骤如下:
-
系统的运行状况: CPU -> MEM -> DISK-> NETWORK -> application
-
-
分析是否有瓶颈(依据当前应用需求)
-
调优(采取一定措施使变得优异)
- 这些子系统之间关系是相互彼此依赖的,任何一个高负载都会导致其他子系统出现问题.比如:
- 大量的网页调入请求导致内存队列的拥塞;
- 网卡的大吞吐量可能导致更多的 CPU 开销;
- 大量的 CPU 开销又会尝试更多的内存使用请求;
- 大量来自内存的磁盘写请求可能导致更多的 CPU 以及 IO 问题;
- 所以要对一个系统进行优化,查找瓶颈来自哪个方面是关键,虽然看似是某一个子系统出现问题,其实有可能是别的子系统导致的。
- 调优就像医生看病,因此需要你对服务器所有地方都了解清楚。
-
查看 CPU 负载相关工具
- 使用 uptime 命令查看系统 cpu 负载
- uptime
07:38:47 up 16:41, 1 user, load average: 0.04, 0.04, 0.08 - 其内容如下:
07:38:47 当前时间
up 16:41 当前系统运行时间,上次开机(重启)到目前的运行时间
1 user 当前登录用户数
load average: 0.04, 0.04, 0.08
系统负载,即任务队列的平均长度。 三个数值分别为 1 分钟、5分钟、15 分钟前到现在的平均值

- 例:找出前当系统中,CPU 负载过高的服务器?
服务器 1: load average: 0.15, 0.08, 0.01 1 核
服务器 2: load average: 4.15, 6.08, 6.01 1 核
服务器 3: load average: 7.15, 7.08, 7.01 4 核
答案:服务器 2 负载过高。 - 经验:单核心,1 分钟的系统平均负载不要超过 3,就可以,4 核心不要超过 12,这是个经验值。
- 所以如果服务器的 CPU 为 1 核心,则 load average 中的数字 >=3 负载过高,如果服务器的 CPU 为4 核心,则 load average 中的数字 >=12 负载过高。
- 任务队列的平均长度是:是系统等待运行队列的长度与当前所有 CPU 中正在运行的工作的和。
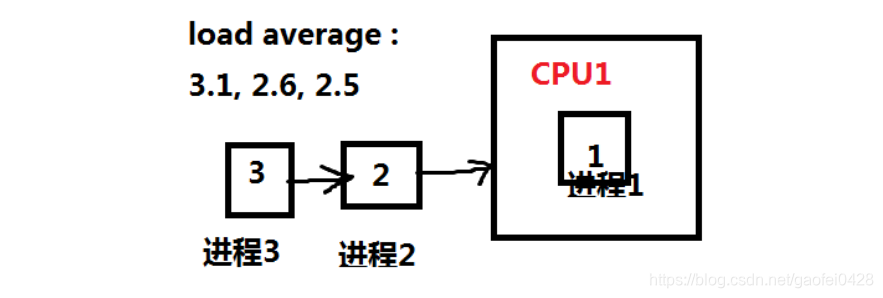
- 就像如图大家正在 3 号窗口排队买票,3 号窗口的队列就是 4 人。
大厅排除买票:

- 如下图单核 cpu 的任何队列长度为 3,包括正在运行的进程
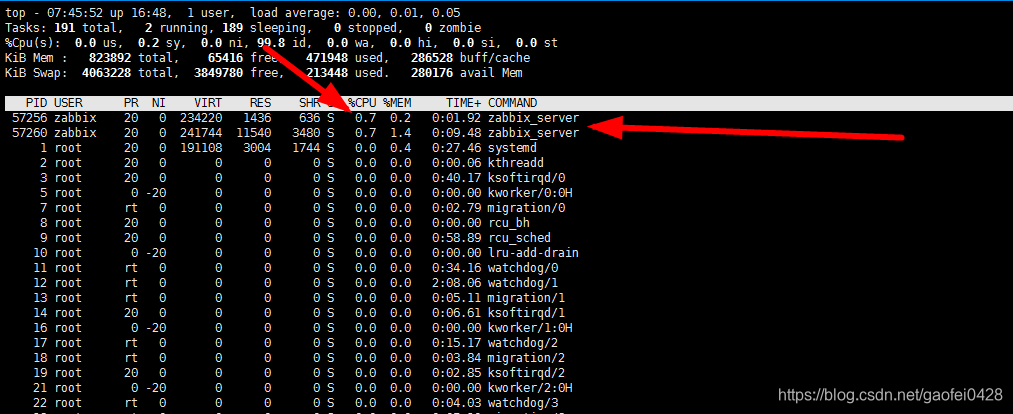
- 找出系统中使用 CPU 最多的进程
运行 top 命令,按下大写的 P,可以按 CPU 使用率来排序显示
-
top 中 VIRT、RES 和 SHR 的含意:
VIRT:virtual memory usage 虚拟内存
进程“需要的”虚拟内存大小,包括进程使用的库、代码、数据等;
假如进程申请 70m 的内存,但实际只使用了 7m,那么它会增长 70m,而不是实际的使用量。 -
RES:resident memory usage 常驻内存
进程当前使用的内存大小,但不包括 swap out;
包含其他进程的共享;
如果申请 70m 的内存,实际使用 7m,它只增长 7m,与 VIRT 相反;
关于库占用内存的情况,它只统计加载的库文件所占内存大小。 -
SHR:shared memory 共享内存
除了自身进程的共享内存,也包括其他进程的共享内存;
虽然进程只使用了几个共享库的函数,但它包含了整个共享库的大小;
计算某个进程所占的物理内存大小公式:RES – SHR;
swap out 后,它将会降下来。 -
-
htop 工具
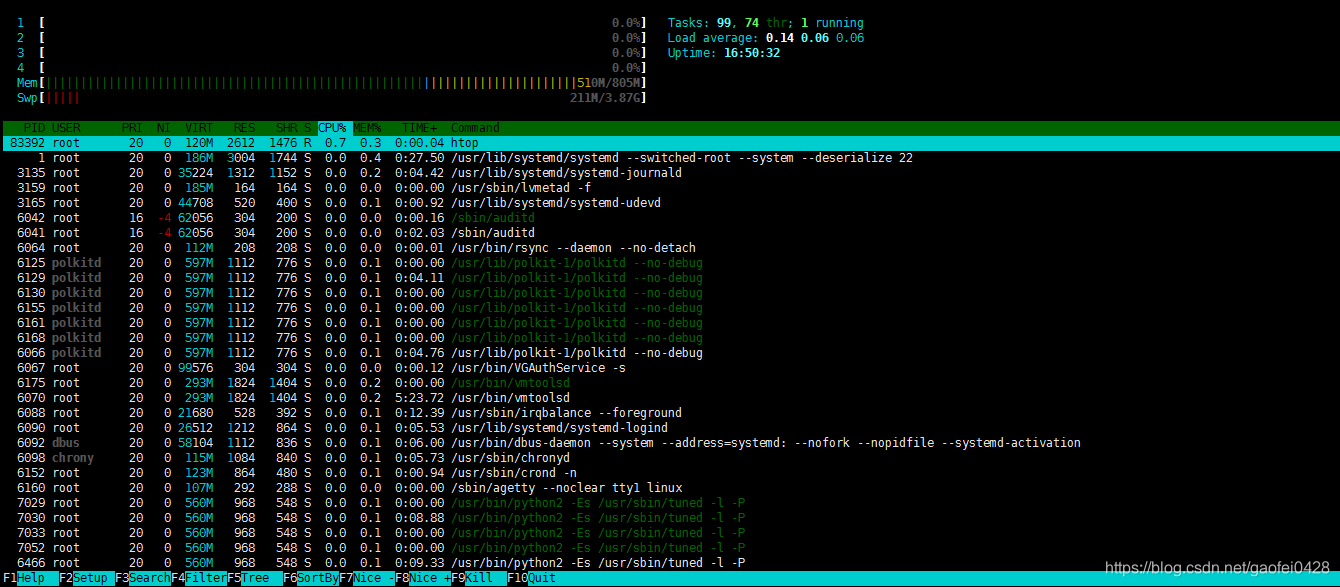
- 在上图中将输出的界面划分成了四个区域,其中:
- 上左区:显示了CPU、物理内存和交换分区的信息
- 上右区:显示了任务数量、平均负载和连接运行时间等信息
- 进程区域:显示出当前系统中的所有进程
- 操作提示区:显示了当前界面中F1-F10功能键中定义的快捷功能
- M:按照内存使用百分比排序,对应MEM%列;
- P:按照CPU使用百分比排序,对应CPU%列;
- T:按照进程运行的时间排序,对应TIME+列;
- K:隐藏内核线程;
- H:隐藏用户线程;
- :快速定位光标到PID所指定的进程上。
- F1:显示帮助信息;
- F2:配置界面中的显示信息
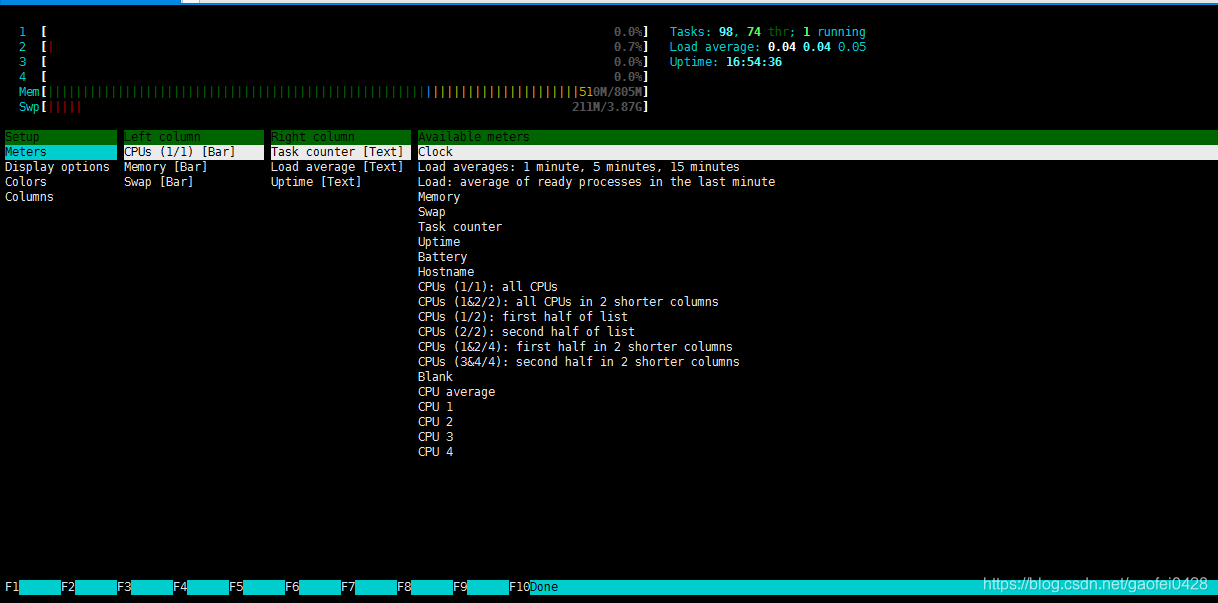
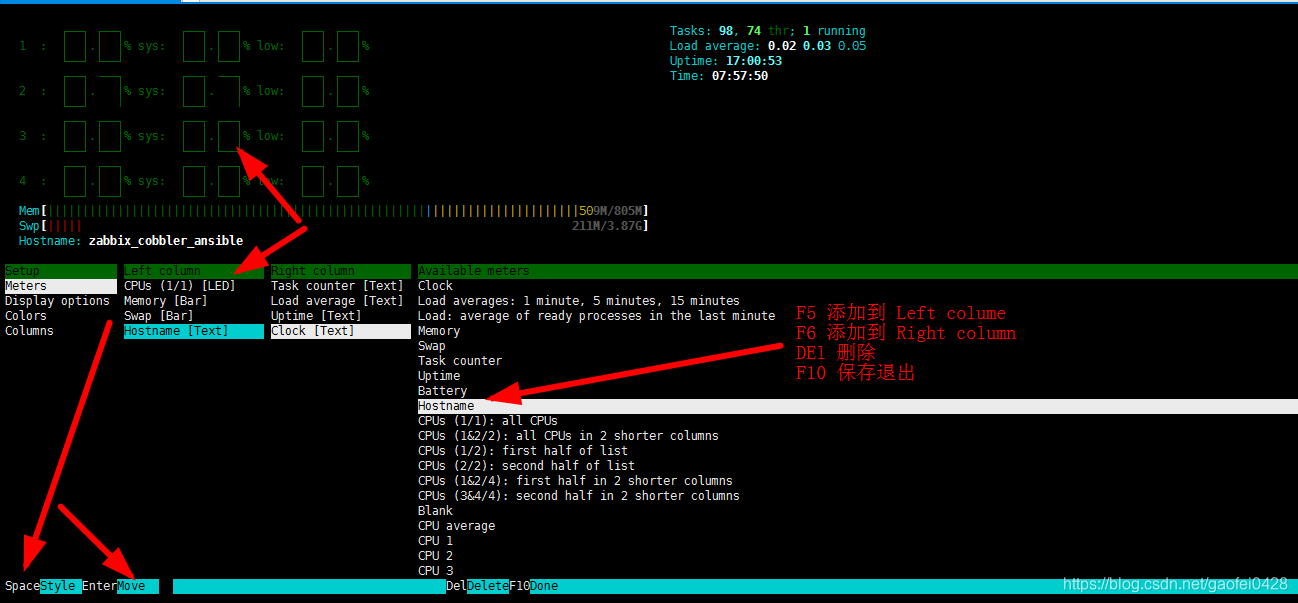
- 可以根据自己的需要修改显式模式以及想要显示的内容
- 比如:以LED的形式显示CPU的使用情况,并且在左边的区域添加hostname,在右边的区区域添加clock
- 方向键选择左右上下
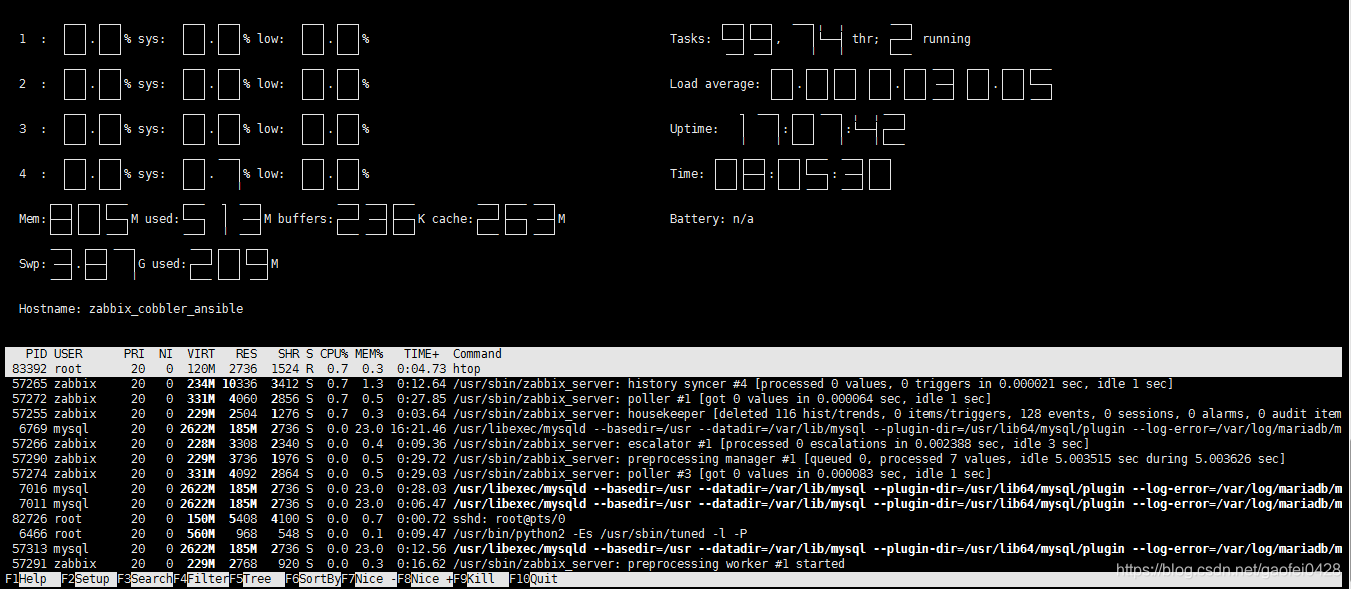
- F3:进程搜索;
- 再次按下 F3 搜索下一个
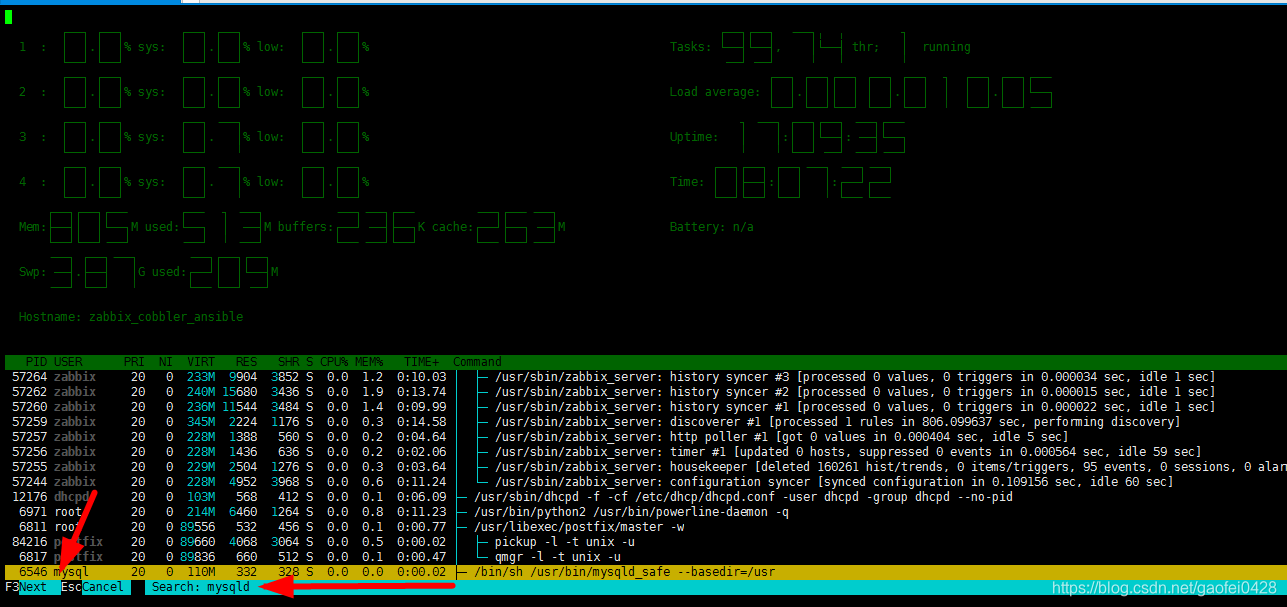
- F4:进程过滤器; 从上面的结果可以看出search和filter的区别: search会将光标定位到符合条件的进程上,通过F3键进行逐个查找;而filter会直接将符合条件的进程筛选出来。 search和filter都使用ESC键来取消功能。
- F5:显示进程树;
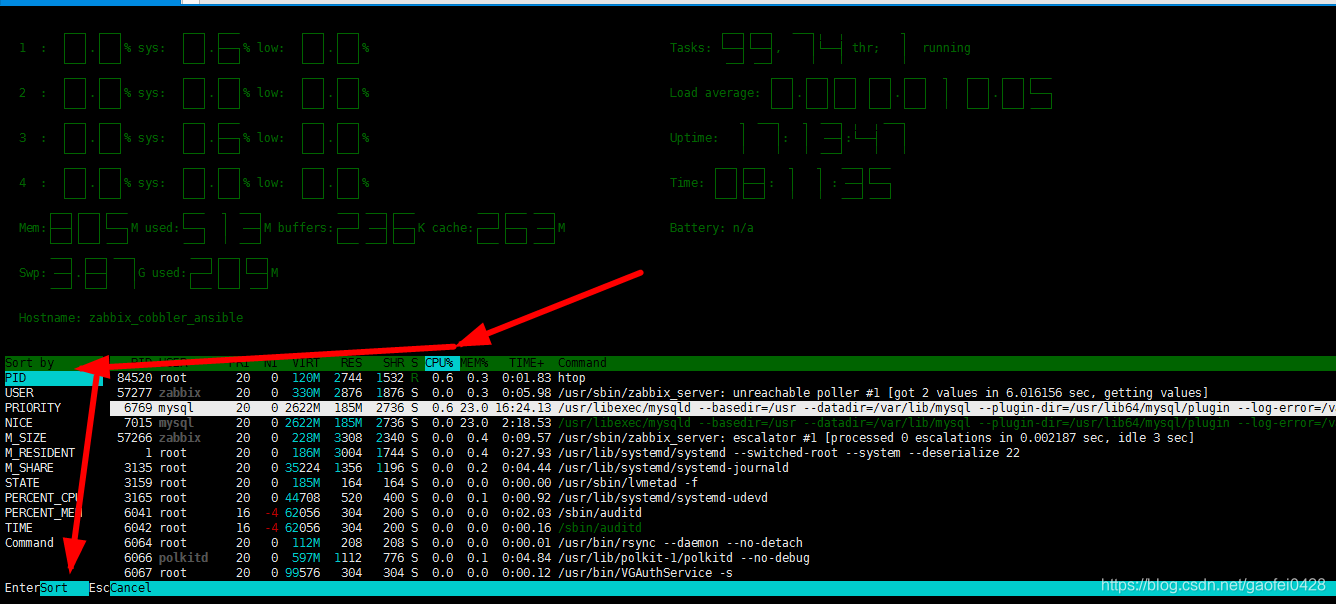
- F6:排序:
- 比如 P 选择 CPU 列,按照 PID 回车排序
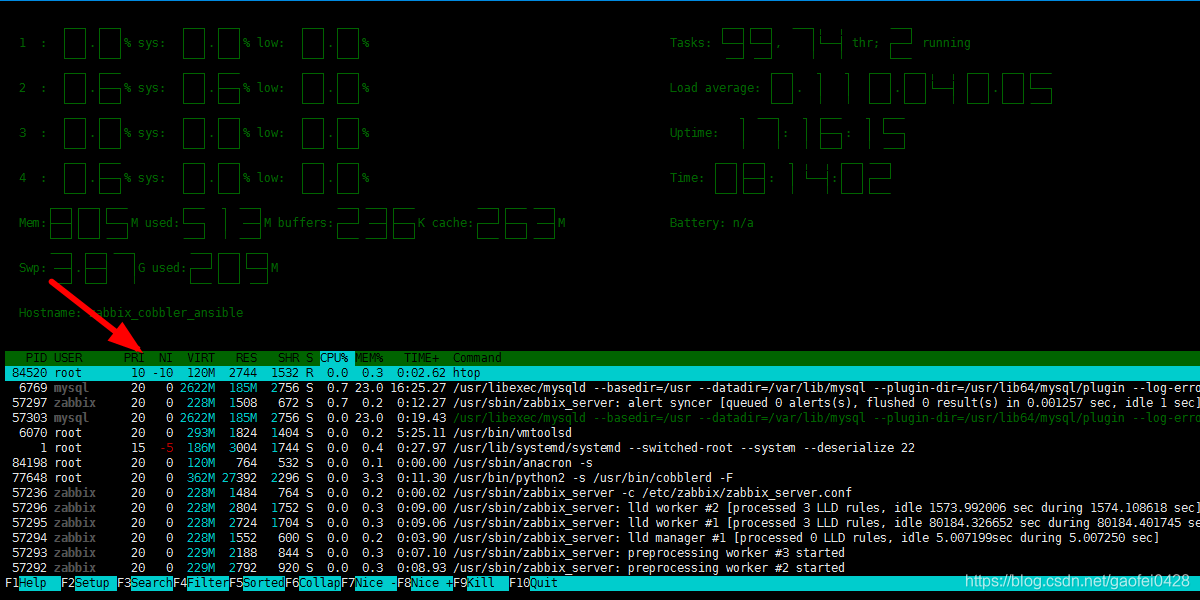
- F7:减小nice值; F8:增加nice值; 直接修改光标选取的进程的nice值:
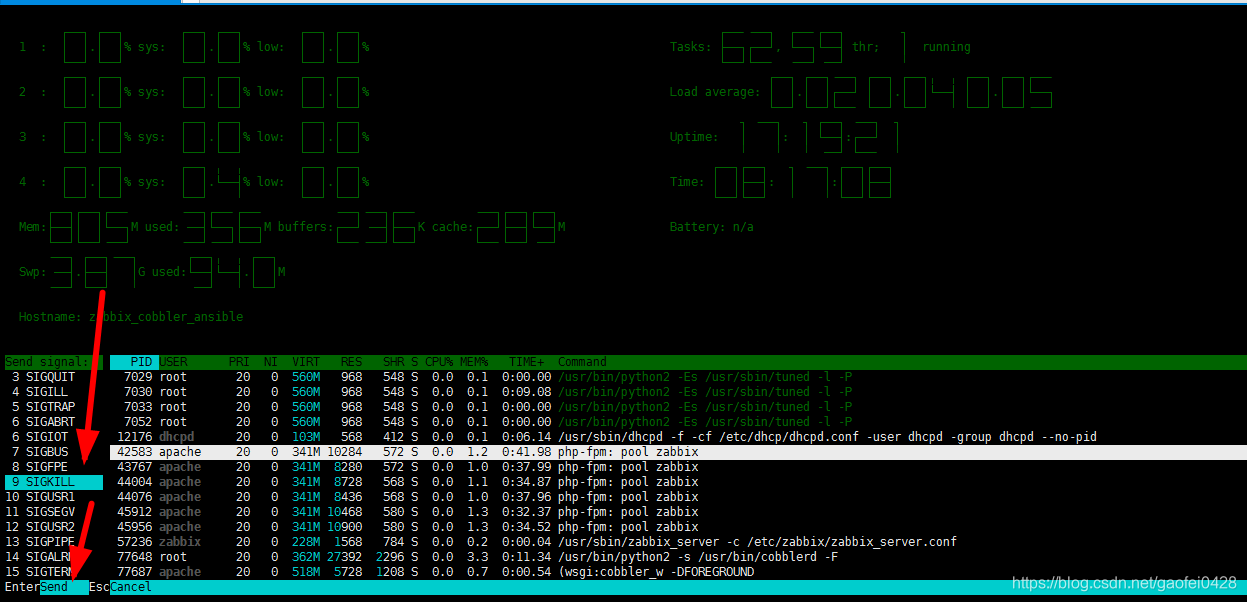
- F9:杀掉指定进程;
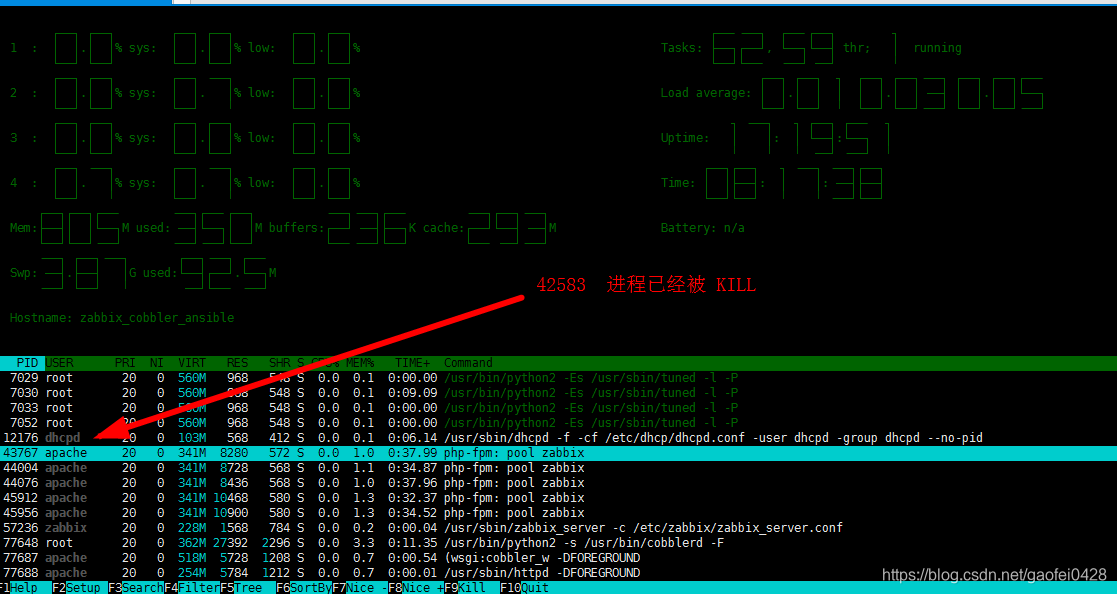
- F10:退出htop。 空格键:用于标记选中的进程,用于实现对多个进程同时操作;
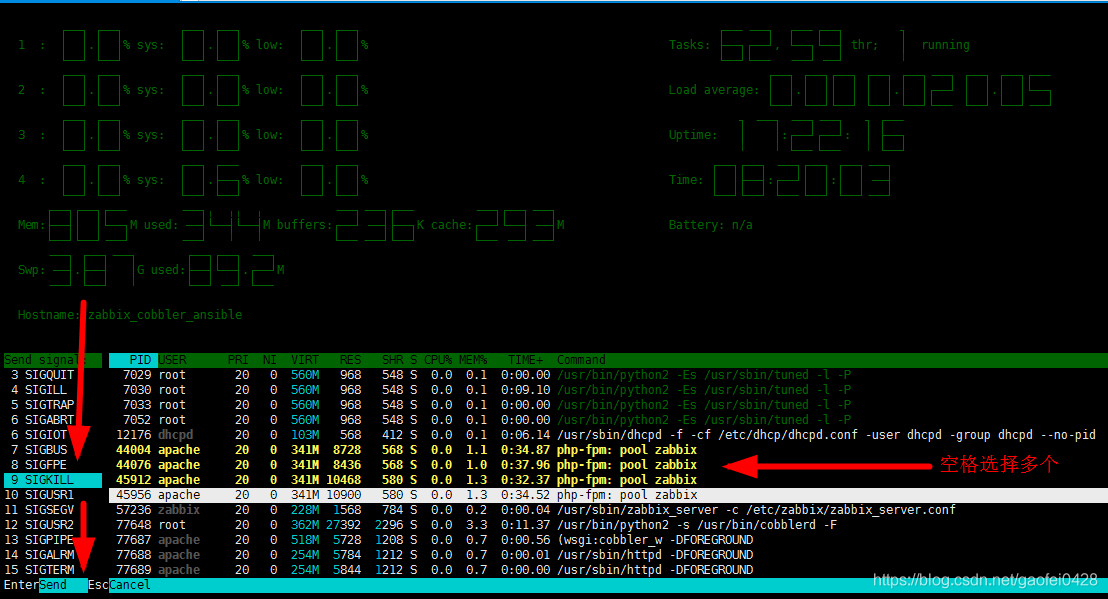

- -u:显示指定用户的进程;
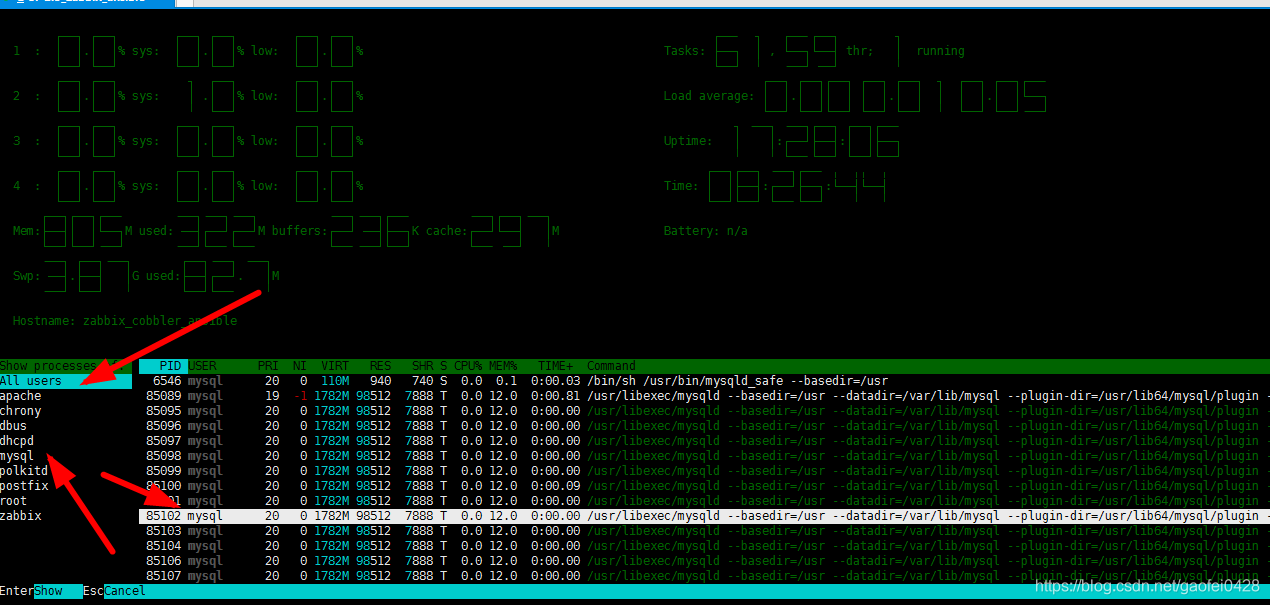
- l:显示光标所在进程的文件列表;
- 大写 i 反转显示
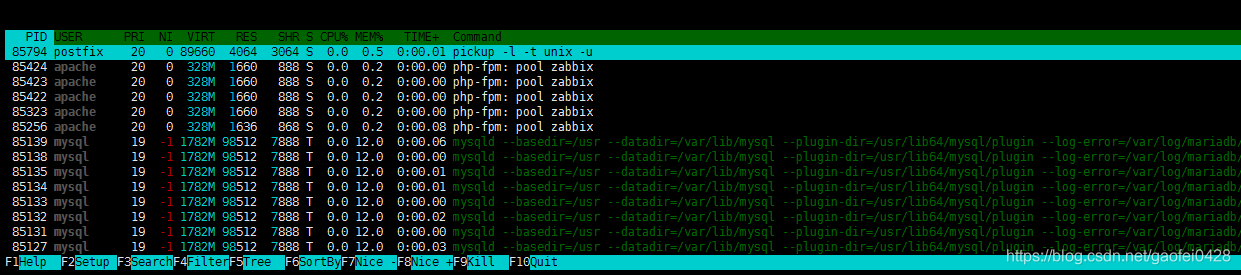
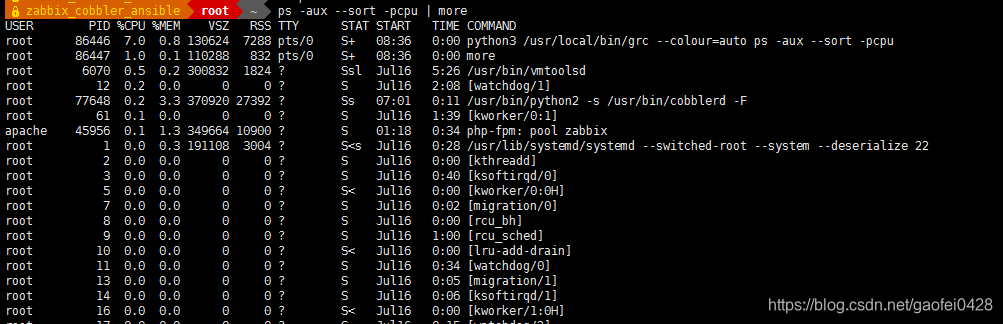
- 按照实际使用 CPU,从大到小排序显示所有进程列表
ps -aux --sort -pcpu | more 按 cpu 降序排序(使用率) - 注: -pcpu 可以显示出进程绝对的路径,方便找出木马程序运行的路径。
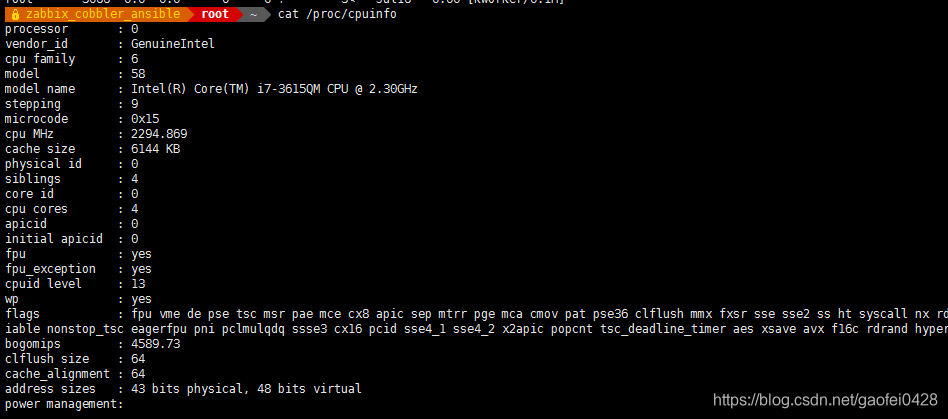
- 查看 CPU 信息
-
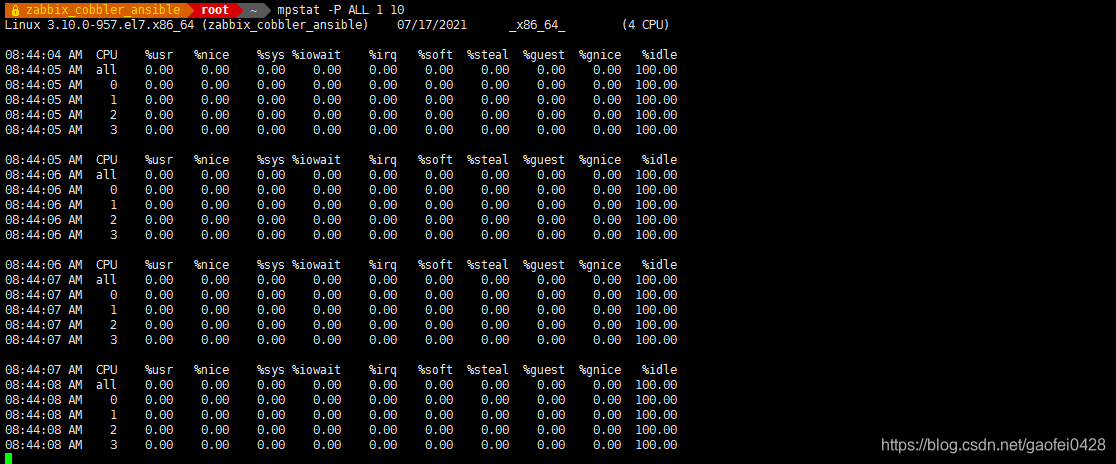
使用 mpstat 查看 CPU 运行情况
rpm -qf `which mpstat` 查看安装 mpstat 命令的安装包。
sysstat-10.1.5-19.el7.x86_64 此软件包,包括很多查看系统状态的软件包。
mpstat

- 注:每列参数说明
usr:用户空间 CPU 使用占比。
nice:低优先级进程使用 CPU 占比。nice 值大于 0。
sys:内核空间 CPU 使用占比。
iowait:CPU 等待 IO 占比。
irq:CPU 处理硬中断占比。
soft:CPU 处理软中断占比。
idle:CPU 空闲时间占比。
guest 与 steal 与虚拟机有关,暂不涉及。 - mpstat -P ALL 查看所有 CPU 运行状态

- mpstat -P ALL 1 10 # 一秒钟刷新一次 连续刷新 10 次
-
查看 Memory 运行状态相关工具
free 命令查看内存使用情况 - 注:在 centos7 系统中 available 这一列是真正可用内存。
- available 包括了 buff/cache 中一些可以被释放的内存。当物理内存不够用的时候,内核会把非活跃的数据清空。

- 通过/proc 目录,查看非活跃的内存:
/proc 文件系统下的多种文件提供的系统信息不是针对某个特定进程的,而是能够在整个系统范围的上下文中使用。可以使用的文件随系统配置的变化而变化。
cat /proc/meminfo
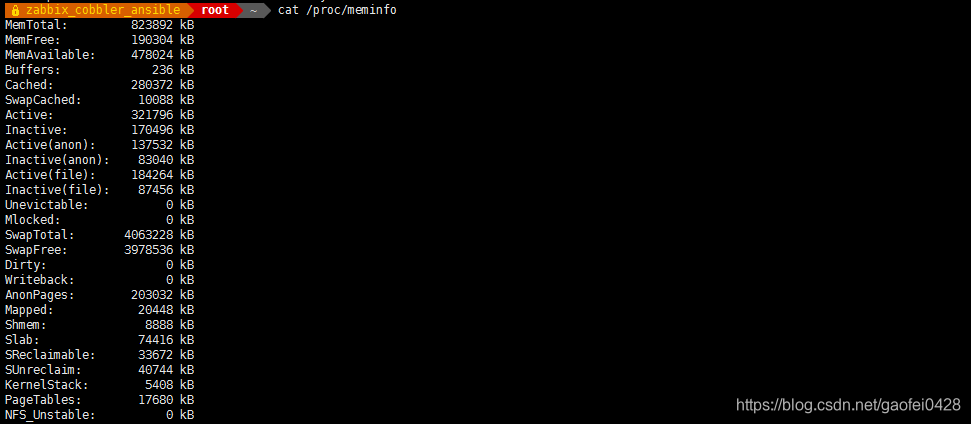
- 注:当内存不够用时,kernel 总是把不活跃的内存交换到 swap 空间。如果 inactive 内存多时,加swap 空间可以解决问题,而 active 多,则考虑加内存。
-
找出系统中使用内存最多的进程?
方法 1:运行 top,然后按下大写的 M 可以按内存使用率来排序显示
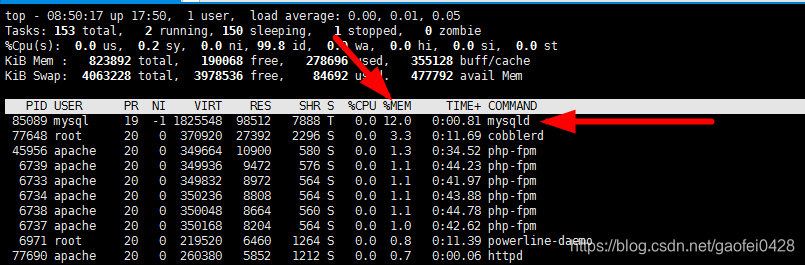
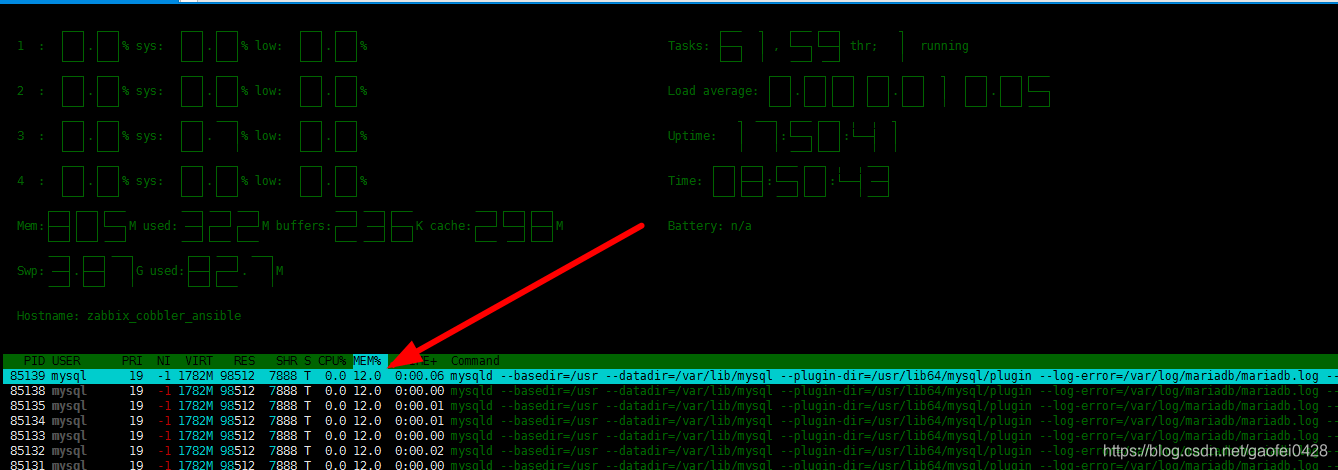
-
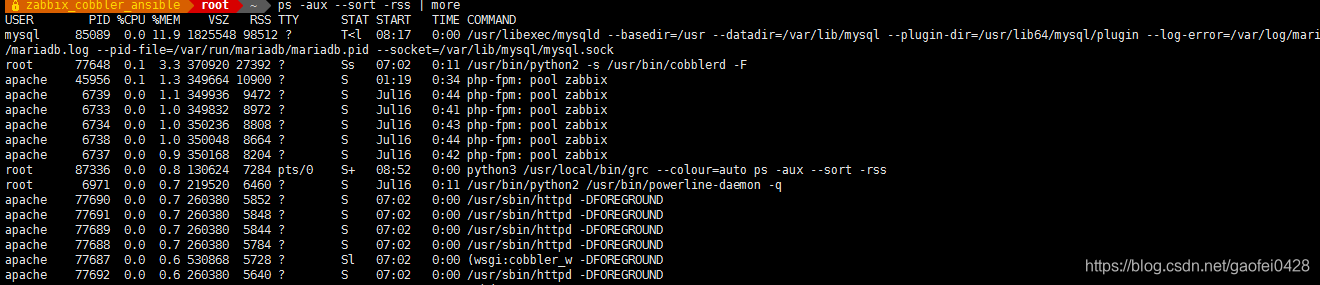
方法 2:按照实际使用内存,从大到小排序显示所有进程列表
- ps -aux --sort -rss | more 内存降序排序(去掉减号就是升序)
- 或:
- ps -aux --sort -rss > a.log

- 对于 xfs 文件系统,查看文件系统块大小
xfs_growfs -l /dev/sda1 |grep bsize

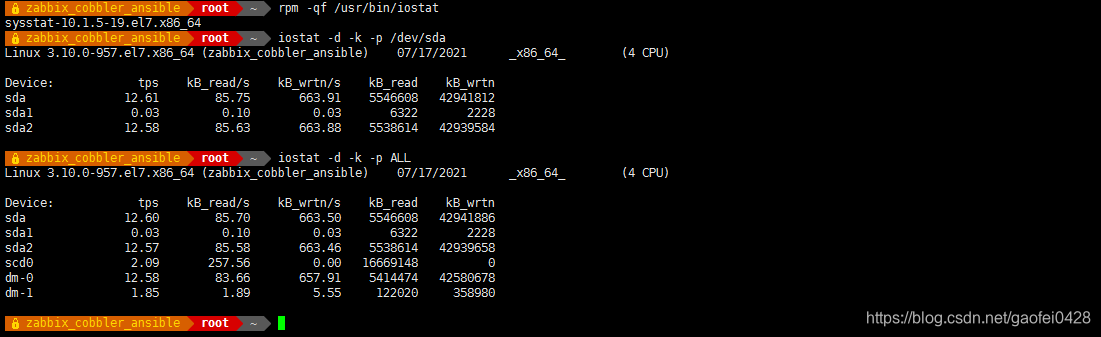
- 常用参数:
-d 仅显示磁盘统计信息。
-k 以K为单位显示每秒的磁盘请求数,默认单位块。
-p device | ALL 用于显示块设备及系统分区的统计信息。
- 注:
每列含意:
kB_read/s 每秒从磁盘读入的数据量,单位为K.
kB_wrtn/s 每秒向磁盘写入的数据量,单位为K.
kB_read 读入的数据总量,单位为K.
kB_wrtn 写入的数据总量,单位为K. - 测试,给磁盘写入一些内容, 写入时尽可能不读磁盘?
dd if=/dev/zero of=/tmp/test.txt bs=10M count=500 ; sync
读入的数据用/dev/zero,/dev/zero不会读磁盘的。
sync 把内存中的数据快速写到磁盘上。 只做dd不执行sync,不容易看不出写入效果 - 另外开一个 shell
- watch iostat -p sda -dk




-
如果服务器很卡,查看CPU使用率不高,内存也够用,但就是卡,尤其是打开新程序或文件时,更卡。此时是哪出问题了?
-
这时系统的瓶颈在哪里? 在磁盘IO上。使用iotop命令,查看哪个进程使用磁盘读写最多。
-
iotop的参数:
-o, -only 只显示在读写硬盘的程序
-d SEC, -delay=SEC 设定显示时间间隔。 刷新时间
iotop 常用快捷键:
<- / ->:左右箭头:改变排序方式,默认是按 IO 排序。
r:改变排序顺序。
o:只显示有 IO 输出的进程。
p:进程/线程的显示方式的切换。
a:显示累积使用量。
q:退出,按 q 或 ctrl+C -
例1:找出使用磁盘最多的进程
- iotop -o -d 1 显示正在使用磁盘的进程

- 在另一个终端对磁盘进行大量读操作,执行:
find /
查看结果:

yum install nload -y
- 开始监控
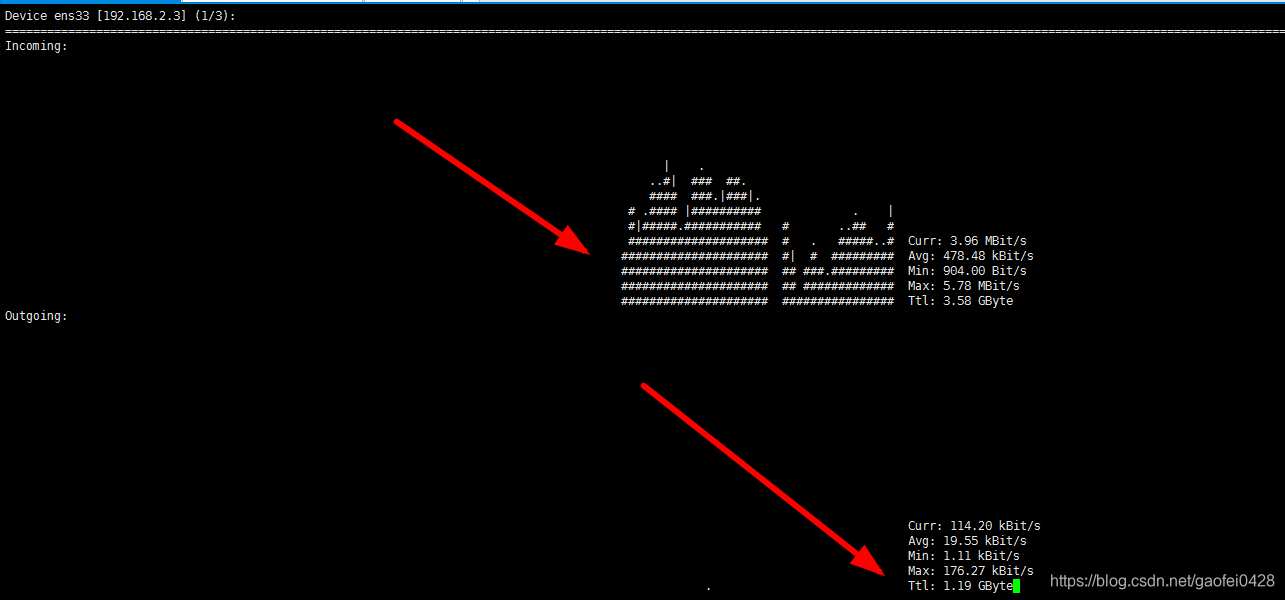
nload

- 然后另一个终端上运行ab,开始测试:
- ab -n 700 -c 2 http://www.baidu.com/index.html 产生一些测试数据
查看结果:


- 在另一个终端生成一些数据:
wget http://issuecdn.baidupcs.com/issue/netdisk/yunguanjia/BaiduNetdisk_5.5.3.exe
查看结果,找出wget是使用流量最多的进程


-
查看系统整体运行状态
使用 vmstat 查看内存及系统整体运行状态 - vmstat :命令是最常见的 Linux/Unix 监控工具,可以展现给定时间间隔的服务器的状态值,包括服务器的 CPU 使用率,MEM 内存使用,VMSwap 虚拟内存交换情况,IO 读写情况。
- 使用 vmstat 可以看到整个机器的 CPU,内存,IO 的使用情况,而不是单单看到各个进程的 CPU 使用率和内存使用率。 比 top 命令节省资源。
- 注:当机器运行比较慢时,建议大家使用 vmstat 查看运行状态,不需要使用 top,因 top 使用资源比较多。
- 例:

- 每一列参数作用:
r 运行状态的进程个数 。展示了正在执行和等待 cpu 资源的任务个数。当这个值超过了 cpu 个数,就会出现 cpu 瓶颈 - b 不可中断睡眠 正在进行 i/o 等待--阻塞状态的进程个数 进程读取外设上的数据,等待时
free 剩余内存,单位是 KB
buff 内存从磁盘读出的内容
cache 内存需要写入磁盘的内容
si swapin swap 换入到内存
so swapout 内存换出到 swap 换出的越多,内存越不够用
bi blockin 从硬盘往内存读。 单位是块。 把磁盘中的数据读入内存
bo blockout 从内存拿出到硬盘 (周期性的有值) 写到硬盘
判断是读多还是写多,是否有 i/o 瓶颈
in 系统的中断次数,cpu 调度的次数多
cs 每秒的上下文切换速度
CPU 上下文切换--程序在运行的时候,CPU 对每个程序切换的过程。
更多内存参以一下表格: vmstat 每个字段含义说明
- 使用 sar 命令记录系统一段时间的运行状态
- sar 工具可以把检查到的信息保存下来,存在/var/log/sa 目录下。
- sar 默认显示每10分钟统计一次状态信息(从装 sysstat 包开始)
- sar 命令行的常用格式: sar [options] [-A] [-o file] t [n]
在命令行中,n 和 t 两个参数组合起来定义采样间隔和次数,t 为采样间隔,是必须有的参数,n 为采样次数,是可选的,默认值是 1,-o file 表示将命令结果以二进制格式存放在文件中,file 在此处不是关键字,是文件名。options 为命令行选项 - sar 命令的选项很多 下面只列出常用选项:
- 下面只列出常用选项:
-A:所有报告的总和。
-n:网络接口的情况。
-u:CPU 利用率
-v:进程、I 节点、文件和锁表状态。
-d:硬盘使用报告。
-r:没有使用的内存页面和硬盘块。
-g:串口 I/O 的情况。
-b:缓冲区使用情况。
-a:文件读写情况。
-c:系统调用情况。
-R:进程的活动情况。
-y:终端设备活动情况。
-w:系统交换活动。
-o 文件名:打印到屏幕并将采样结果以二进制形式存入当前目录下的文件中。
-f 文件名:查看之前保存的二进制文件。
-d:显示磁盘。
-d 1 70 必须得指定次数。
-c:每秒创建进程的个数。
-i 1 7 指定时间间隔。
-P:查看 cpu。
-r:查看内存。
-w:每秒上下文切换次数。
-o /cpu.sar 保存并显示。
-f cpu.sar 读取。 - 每 2 秒采样一次,连续采样 5 次,观察 CPU 的使用情况,并将采样结果以二进制形式存入当前目录下的文件 cpu.sar 中
sar -u 2 5 -o cpu.sar 屏幕显示以一下内容,同时内容也会写到当前目录的./cpu.sar 中
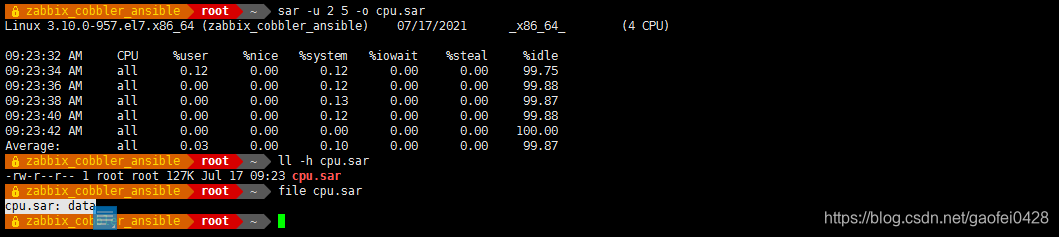
- 在显示内容包括:
%usr:CPU 处在用户模式下的时间百分比。
%system:CPU 处在系统模式下的时间百分比。
%iowait:CPU 等待输入输出完成时间的百分比。
%idle:CPU 空闲时间百分比。
在所有的显示中,我们应主要注意%iowail 和%idle - %iowail 的值过高,表示硬盘存在 I/O 瓶颈,%idle 值高,表示 CPU 较空闲,如果%idle 值高但系统响应慢时,有可能是 CPU 等待分配内存,此时应加大内存容量
- %idle 值如果持续低于 7,那么系统的 CPU 处理能力相对较低,表明系统中最需要解决的资源是 CPU
- 查看二进制文件 cpu.sar 中的内容
sar -u -f cpu.sar
注:sar 命令即可以实时采样,又可以对以往的采样结果进行查询

- 查看 sar 的计划任务并读取日志
查看 sar 的计划任务cat /etc/cron.d/sysstat ???127?
Run system activity accounting tool every 10 minutes
*/10 * * * * root /usr/lib64/sa/sa1 1 1 默认每10分钟执行一次
0 * * * * root /usr/lib64/sa/sa1 600 6 &
Generate a daily summary of process accounting at 23:53
53 23 * * * root /usr/lib64/sa/sa2 -A

- 注:生成的日志位置:
- ls /var/log/sa

- 读取日志
ls /var/log/sa 只要安装 sar 后就会定期收集系统信息。 - 注:sa 开头的文件不能使用 cat 命令进行查看,只能使用 sar -f 进行查看,文件名命名规则 sa+日期,sa01 表示这个月的第一天。文件名会根据日期进行排序,sa01、sa02 ……
- 使用参数-n 查看网络接口流量情况:
sar -n DEV -f /var/log/sa/sa16 查看网络相关信息。
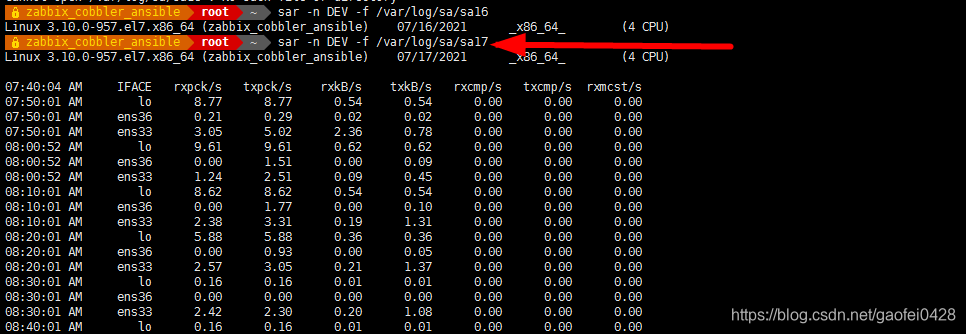
- 查看内存和硬盘
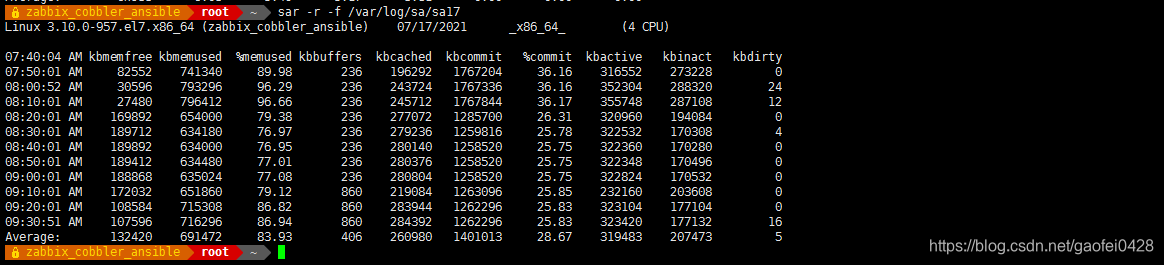
sar -r -f /var/log/sa/sa17
-r 查看内存
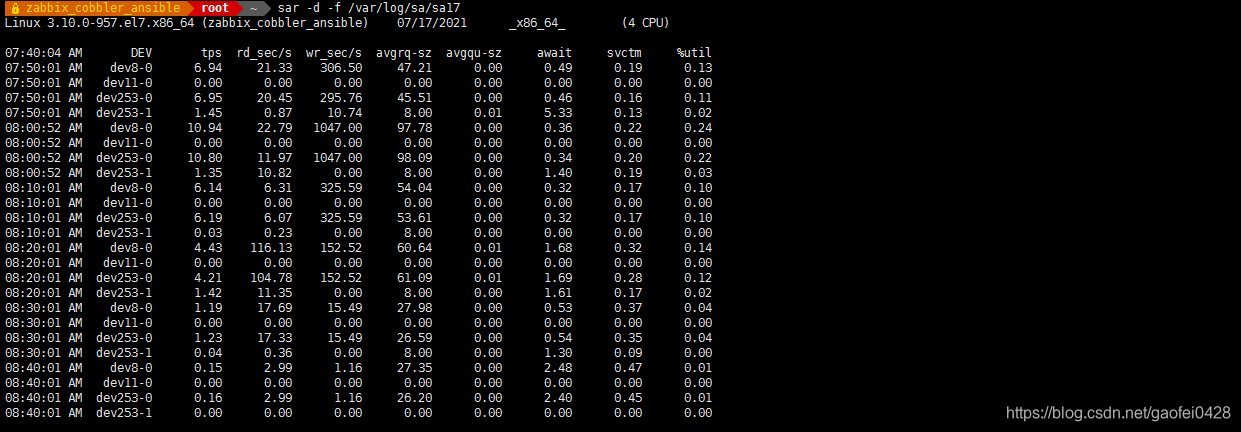
- sar -d -f /var/log/sa/sa17
-d:硬盘使用报告
-
sar 最大特点是可以监控所有状态,sar 的其他使用方法如下:
sar -r 1 查看内存
sar -n ALL 查看所有
sar -b 1 7 缓冲区使用情况,每秒刷新一次,查看 7 次
sar -I ALL 1 7
sar -r -f /tmp/file -n -r -b -m
sar -s 15:00:00 -e 15:30:00 查看某个时间段,系统运行情况
sar -s 15:00:00 -e 15:30:20 -f /var/log/sa/sa17
sar -r -s 15:00:00 -e 15:30:20 -f /var/log/sa/sa17
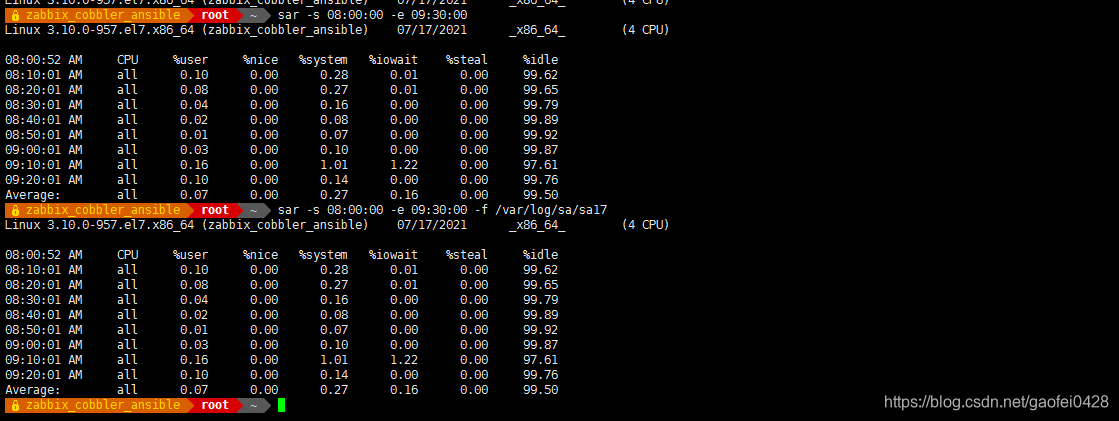
-
CPU-IO-网络-内核参数的调优
- 调 整 nice 值 改 变 进 程 优 先 级
nice 概述:在 LINUX 系统中,Nice 值的范围从-20 到+19(不同系统的值范围是不一样的),正值表示低优先级,负值表示高优先级,值为零则表示不会调整该进程的优先级。具有最高优先级的程序,其 nice 值最低,所以在 LINUX 系统中,值-20 使得一项任务变得非常重要;与之相反,如果任务的 nice为+19,则表示它是一个高尚的、无私的任务,允许所有其他任务比自己享有宝贵的 CPU 时间的更大使用份额,这也就是 nice 的名称的来意。默认优先级是 0 - 在命令运行前,调整进程 nice 值,让进程使用更多的 CPU
- 语法: nice -n 优先级数字 命令
- 例:将 vim test.txt 命令的优先级,从默认的 0 级别调高到-5 级别
- pidof vim 得到进程的 PID
- top -p PID 只查看某进程
- 看得出默认 nice 值为 0
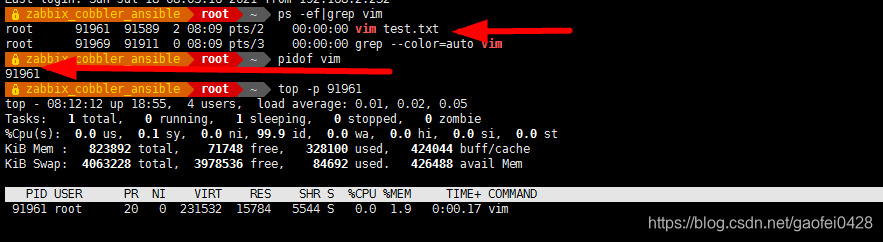
- nice -n -5 vim test.txt 先不要退出这个 vim 命令,另外打开一个shell
- NI 值 为5

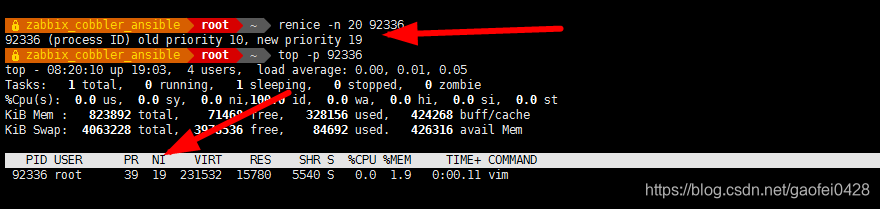
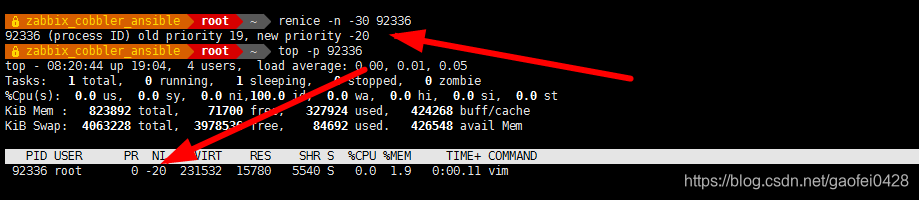
- 使用 renice 修改正在运行的进程的优先级
语法:renice -n [NUM] PID 修改进程优先级 - 将先前 vim 的 PID 92336 优先级调整为级别 10
- renice -n 10 92336

- 设 置 进 程 的 CPU 亲 和 力
taskset 作用:在多核的情况下,可以认为指定一个进程在哪颗 CPU 上执行程序,减少进程在不同CPU 之前切换的开销。
安装 taskset 命令: - yum -y install util-linux

- taskset 语法: taskset -cp [CPU ID 号] 命令或进程 ID
常用参数:
-p, --pid 在已经存在的 pid 上操作
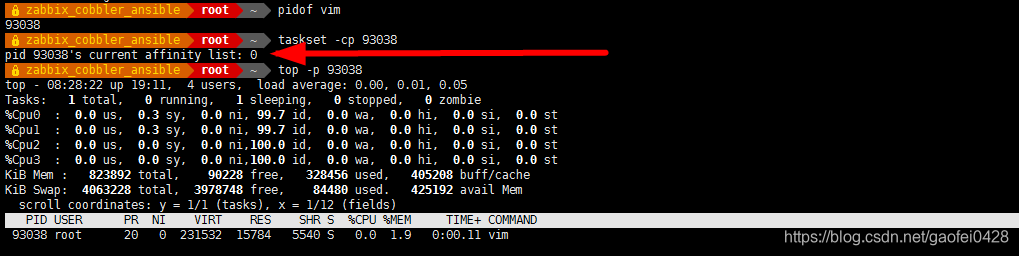
-c, --cpu-list 以列表格式显示和指定 CPU - 服务器是 4 核 CPU ,指定 vim 命令在第一个 CPU 上运行
- taskset -c 0 vim test.txt 第一个 CPU 的 ID 是 0。
- 查 sshd 进程运行在哪几个 CPU 上
- pidof sshd
91909 91586 87896 82726 6471
taskset -cp 91586
pid 91586's current affinity list: 0-3 0-3 说明 sshd 进程可以使用 4 个 CPU 核心处理数据。

- 指定 vim c.txt 程序运行在第 2 和第 4 个 CPU 上
taskset -c 1,3 vim test.txt

65% 70% User Time 用户态(通常指我们运行的服务和程序)。
30% 35% System Time 内核态。
0% 5% Idle Time 空闲。
- Context Switches 上下文切换的数目直接关系到 CPU 的使用率,如果 CPU 利用率保持在上述均衡状态时,有大量的上下文切换是正常的。
- 上下文切换指的就是 cpu 中寄存器数据的写入和读出。每个进程在使用 cpu 时,都需要把自己的数据先写入 cpu 的缓存(寄存器)中,然后 cpu 才能根据缓存中的数据来计算。
- 一台 4 核心,8G 内存的服务器,根据 vmstat 运行的结果,来分析系统中存在的问题。
学会这个思路,后期就可以很轻松分析出 8 核心,16G 或 8 核心,32G 服务器的瓶颈。
-
vmstat 输出每列字段的意义:
- Procs(进程):
r: The number of processes waiting for run time. 等待运行的进程数。如果等待运行的进程数越多,意味着 CPU 非常繁忙。另外,如果该参数长期大于 cpu 核心数 3 倍,说明 CPU 资源可能存在较大的瓶颈。
b: The number of processes in uninterruptible sleep.处在非中断睡眠状态的进程数。即等待 IO 的进程数量。 - Memory(内存):
swpd: the amount of virtual memory used.已使用的虚拟内存大小。如果虚拟内存使用较多,可能系统的物理内存比较吃紧,需要采取合适
的方式来减少物理内存的使用。swapd 不为 0,并不意味物理内存吃紧,如果 swapd 没变化,si、so 的值长期为 0,这也是没有问题的 。
free: the amount of idle memory.空闲的物理内存的大小
buff: the amount of memory used as buffers.用来做 buffer(缓存,主要用于块设备缓存)的内存数,单位:KB
cache: the amount of memory used as cache.用作缓存的内存大小,如果 cache 的值大的时候,说明 cache 处的文件数多,如果频繁访问到
的文件都能被 cache 处,那么磁盘的读 IO bi 会非常小。单位:KB
- Swap(交换分区)
- si: Amount of memory swapped in from disk (/s).
从磁盘写入到 swap 虚拟内存的交换页数量,单位:KB/秒。如果这个值大于 0,表示物理内存不够用或者内存泄露了。
so: Amount of memory swapped to disk (/s).
从 swap 虚拟内读出的数据。即从 swap 中的数据写入到磁盘的交换页数量,单位:KB/秒,
如果这个值大于 0,表示物理内存不够用或者内存泄露了。
内存够用的时候,si so 2 个值都是 0,如果这 2 个值长期大于 0 时,系统性能会受到影响,磁盘 IO和 CPU 资源都会被消耗。
当看到空闲内存(free)很少的或接近于 0 时,就认为内存不够用了,这个是不正确的。不能光看这一点,还要结合 si 和 so。如果 free 很少,但是 si 和 so 是 0,那么不用担心,系统性能这时不会受到影响的。
IO(这里指 Input/Output Memery 的数据,即 bi:进入内存,bo:从内存中出去)
bi: Blocks received from a block device (blocks/s).
每秒从块设备接收到的块数,单位:块/秒 也就是读块设备。bi 通常是读磁盘的数据
bo: Blocks sent to a block device (blocks/s).
每秒发送到块设备的块数,单位:块/秒 也就是写块设备。bo 通常是写磁盘的数据
- System(系统)
in: The number of interrupts per second, including the clock.
每秒的中断数,包括时钟中断。
cs: The number of context switches per second.
每秒的环境(上下文)切换次数。比如我们调用系统函数,就要进行上下文切换,而过多的上下文切换会浪费较多的 cpu 资源,这个数值应该越小越好。 - CPU(使用 cpu 时间的百分比%,最大 100%)
us: Time spent running non-kernel code. (user time, including nice time)
用户 CPU 时间(非内核进程占用时间)(单位为百分比)。 us 的值比较高时,说明用户进程消耗的 CPU 时间多
sy: Time spent running kernel code. (system time)
系统使用的 CPU 时间(单位为百分比)。sy 的值高时,说明系统内核消耗的 CPU 资源多,这并不是良性表现,我们应该检查原因。
id: Time spent idle. Prior to Linux 2.5.41, this includes IO-wait time.
空闲的 CPU 的时间(百分比),在 Linux 2.5.41 之前,这部分包含 IO 等待时间。
wa: Time spent waiting for IO. Prior to Linux 2.5.41, shown as zero.
等待 IO 的 CPU 时间,这个值为 0 .这个指标意味着 CPU 在等待硬盘读写操作的时间,用百分比表示。wait 越大则机器 io 性能就越差。说明 IO 等待比较严重,这可能由于磁盘大量作随机访问造成,也有可能磁盘出现瓶颈(块操作)。
st: 虚拟机占用 cpu 时间的百分比。如果 centos 系统上运行了 kvm 虚拟机,而 kvm 虚拟上又运行了几个虚拟机,那么这个值将显示这个几个正在运行的虚拟机从物理机中窃取 CPU 运行时间的百分比。 - 当系统刚开机后,一切正常时,vmstat 的状态。
vmstat 1 10
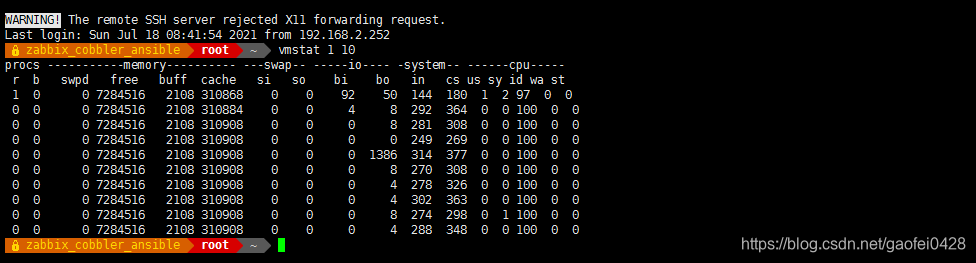
- 注:根据观察值,我们可以得到以下结论:
1、第 1 列 r(run),有个 1,很多次是 0,说明当前系统中正在运行的进程不多,此值大于 cpu核心数 3 倍时,我们认为是 cpu 是繁忙的。当前情况下: r > 12,才算忙。
2、第 4 列 free 是物理内存剩余数。默认单位是 KB,现还有 7284516KB,所以内存肯定够用。
3、第 7 和 8 列 swap 是 swap 内存交换分区使用情况。如果这两列有数据,说明我们已经使用了 swap交换分区了,那么系统的内存肯定不够用了,需要加内存。
4、第 9 和 10 列 io,如果 io 这组数据中 bi 比较大,说明从磁盘读进内存的数据比较大,即读磁盘数据多。bo 比较大,说明从内存写入到磁盘的数据比较多,即说明写磁盘比较多。
5、第 13 和 15 列 cpu 数据组中的 us 是用户太进程使用 cpu 时间的百分比。如果 us 列数据比较大,说明用户态的进程如 apache,mysql 等服务使用 cpu 比较多。 id 这列是 cpu 空闲时间(%)。此列最大值是 100%
6、第 16 列,即倒数第二列 wa(等待 IO 所消耗的 CPU 时间百分比),如果此占用 cpu 的百分比比较大,如到达了 40%,说明磁盘读写速度太慢,IO 有瓶颈了。具体是 bi 或 bo 的问题,可以查看一下 bi和 bo 列的数值。如果 bi 列值很大,说明进程在等待写入磁盘数据时,占用了大量 cpu。
上传一个比较大的文件到 linux 系统中,分析系统资源使用情况。上传文件是只写磁盘,不读磁盘。
vmstat 1 1000 开始长时间监控系统。
然后开始上传一些文件系统中。上传的文件大家可以随意找一些文件上传,只要大于 1G 就可以了。大于 1G,可以上传的时间长一些,方便看出来效果。
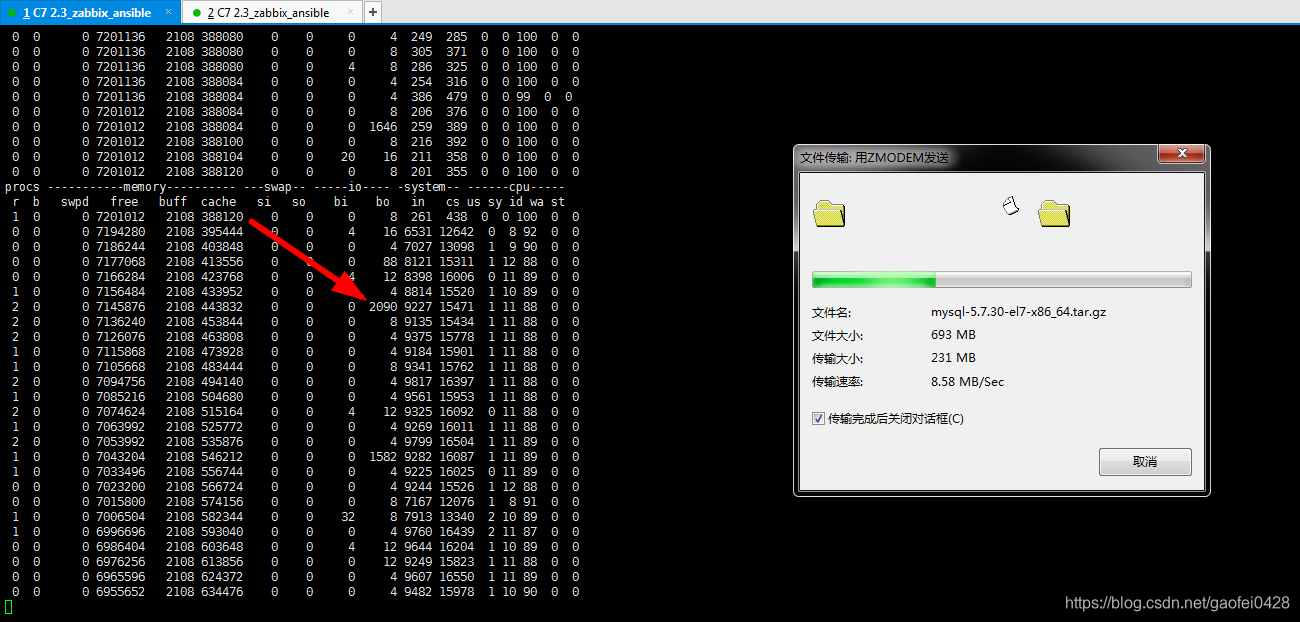
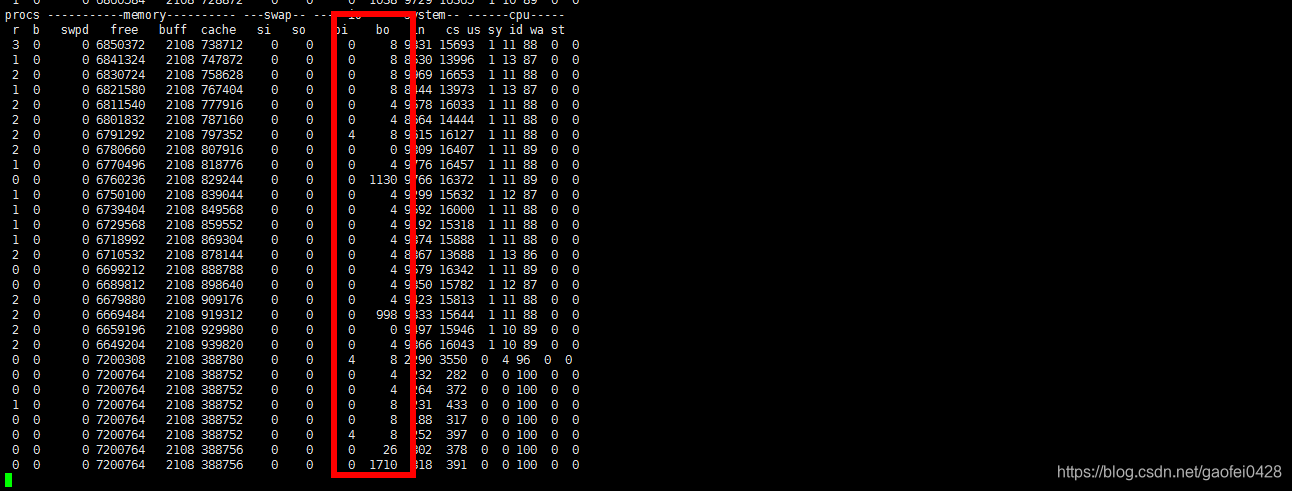
- 注:根据观察值,我们可以得出结论:
- 因为只是上传文件到 linux 系统中,在上传文件过程中没有读磁盘,所以 bi 的值一直为 0;
- 但是上传文件时会写入磁盘,所以 bo 这列会有大量数据。
- r 列,free 列,us 列,id 列,wa 列数据不多,说明 cpu,内存,io 都还可以,压力不大。
- 将/lib64 目录复制到/opt 下,模拟生产环境下备份数据的情景。在复制的过程中查看一下系统的状态。
- du -sh /lib64/
228M /lib64/
cp -r /lib64/ /opt/
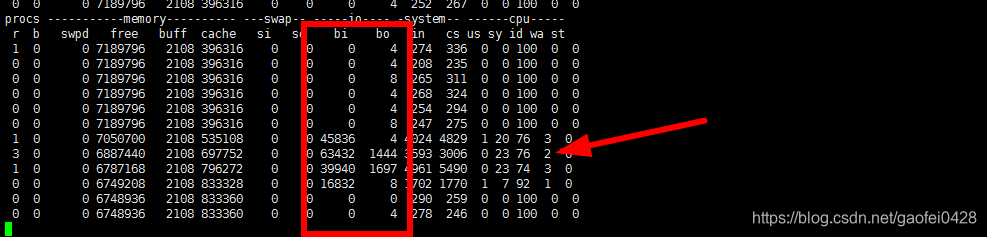
- 注:根据观察值,我们可以得出结论:
因为我们是复制文件,所以 bi 和 bo 都会有大量数据。
r 列,free 列数据不大,说明正在运行的进程数不多,内存也够用。
查看 r 列最大数据是 3,r 列如果超过 12 则认为 cpu 核心数不够用。所以当前运行的进程不多,cpu 核心数够用。 - 查看 us 列、sy 列、wa列、使用 cpu 不多,如果 wa 列使用 cpu 很多。说明当前系统的瓶颈是磁盘读写太慢。因为大量进程都处在等待读写磁盘上这件事上。
- 总结:通过 wa 列是最容易看出磁盘读写速度是否太慢。
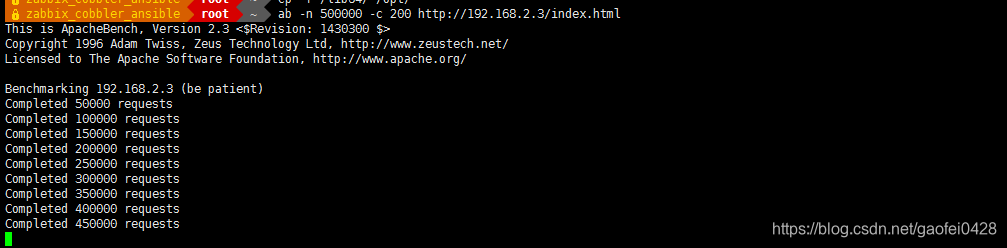
- 使用 apache 的压测工具 ab 对系统进行测试
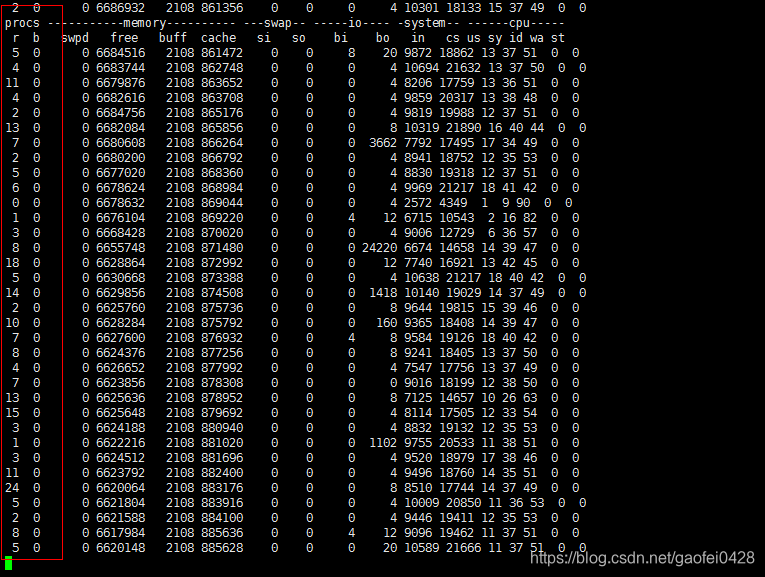
- ab -n 500000 -c 200 http://192.168.2.3/index.html
-
注:根据观察值,我们可以得出结论:
r 列有几个数值已经超过 12 了,说明 cpu 核心数不够用了。 - wa 列为 0,说明在读写磁盘等待上,没有占用 cpu。
- 这样情况就是服务器上运行了大量进程,在消耗 cpu。可以使用 ps 查看一下有哪个进程,另外,也可以运行 top 命令再按 P,来查看一下哪些进程在大量使用 cpu。
- 扩展:关于 buff 和 cache 内存
BUFFER inode 节点索引缓存; CACHE block 块/页缓存。
buffers 缓存从磁盘读出的内容 ,这种理解是片面的
cached 缓存需要写入磁盘的内容 ,这种理解是片面的
不过现在在 centos7 下,free 命令已有变化,free 直接给出了可用空余内存 available。增加了-h选项,支持以人性化的单位(K/M/G)显示各个数值。如下:

-
有关磁盘 I/O 的调优
ulimit 资 源 限 制 - 限制用户资源配置文件:/etc/security/limits.conf
- 每行的格式:用户名/@用户组名 类型(软限制/硬限制) 选项 值
- 永久修改一个进程可以打开的最大文件数
- vim /etc/security/limits.conf 在文件的最后追加以下内容
- * - nofile 655350 理论上大于 65535 即可
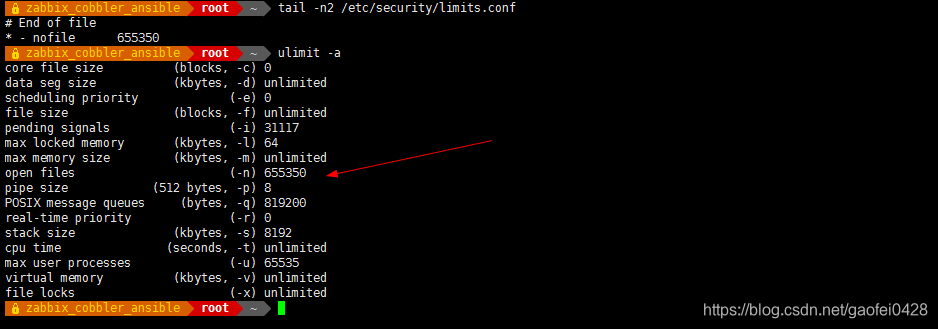
- 注:soft 是一个警告值,而 hard 则是一个真正意义的阀值,超过就会报错。一般把 soft 和 hard 都配置成一样的值。 最大打开的文件数以文件描叙符 file descripter 计数)。
- ulimit -n 查看一个进程可以打开的文件数,默认是 1024
- init 6 想要刚修改的 limits.conf 中配置永久生效,必须重启系统
- 临时修改
ulimit -n 655350 不用重启系统。
ulimit -n
-
nproc 配置一个用户可以打开的最大进程数
vim /etc/security/limits.d/20-nproc.conf
改:
5 * soft nproc 4096
为:
5 * soft nproc 65535
6 * hard nproc 65535

- 临时修改
- ulimit -u 65535
- 注:如果默认一个用户,比如 apache 可用的最大进程数是 1024.那么 apache 用户启动的进程就数就不能大于 1024了。
-
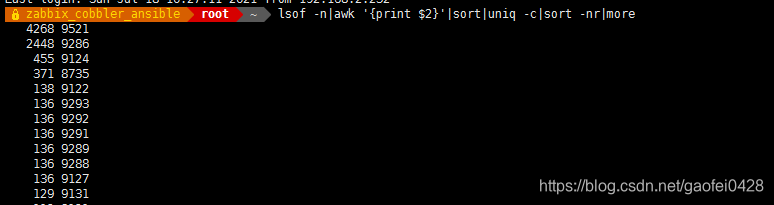
查询系统中进程占用的句柄数
使用的命令是:
-
lsof -n|awk '{print $2}'|sort|uniq -c|sort -nr|more
- 查 看 所 有 的 资 源 限 制 信 息

- core file size (blocks, -c) 0 kdump 转储功能打开后产生的 core file 大小限制
data seg size (kbytes, -d) unlimited 数据段大小限制
scheduling priority (-e) 0
file size (blocks, -f) unlimited 文件大小限制
pending signals (-i) 31117
max locked memory (kbytes, -l) 64
max memory size (kbytes, -m) unlimited
open files (-n) 655350 打开的文件个数限制
pipe size (512 bytes, -p) 8 管道大小的限制
POSIX message queues (bytes, -q) 819200 消息队列大小real-time priority (-r) 0
stack size (kbytes, -s) 8192 栈大小
cpu time (seconds, -t) unlimited CPU 时间使用限制
max user processes (-u) 65535 最大的用户进程数限制
virtual memory (kbytes, -v) unlimited 虚拟内存限制
file locks (-x) unlimited
- 测 试 硬 盘 速 度
一般情况下使用 hdparm 来测试磁盘顺序读的速度。dd 命令用来测试磁盘顺序写的速度。
hdparm 命令常用参数
参数:
-t perform device read timings 不使用预先的数据缓冲, 标示了 Linux 下没有任何文件系统开销时磁盘可以支持多快的连续数据读取. perform [pəˈfɔ:m] 执行
--direct Use O_DIRECT to bypass page cache for timings 直接绕过缓存进行统计数据 - hdparm -t --direct /dev/sda
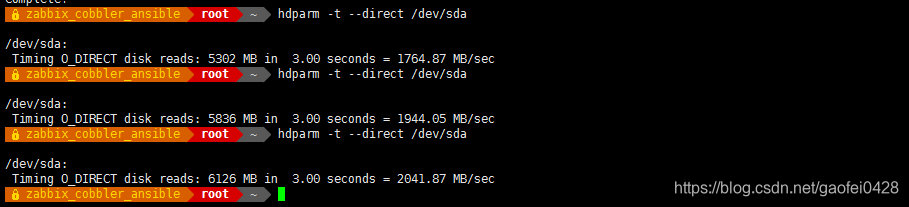
- 注: 弹出的含意是 3.00 秒中从硬盘缓存中读 5302M,平均每秒读 1764.87MB/sec
- 使用 dd 命令测试磁盘 IO 的顺序写和读速度
在使用前首先了解两个特殊设备:/dev/null 伪设备,回收站.写该文件不会产生 IO 开销;/dev/zero 伪设备,会产生空字符流,读该文件不会产生 IO 开销 - dd if=/dev/zero of=/tmp/test.dbf bs=1M count=5000 oflag=direct,nonblock
5000+0 records in
5000+0 records out
5242880000 bytes (5.2 GB) copied, 23.4296 s, 224 MB/s

- 注:可以看到,在 23.4296 秒的时间里,生成 5000M 的一个文件,IO 写的速度约为 224 MB/秒,这就是硬盘顺序写速度了。当然这个速度可以多测试几遍取一个平均值。
注:oflag=direct,nonblock 中的 direct 表示读写数据采用直接 IO 方式;nonblock 表示读写数据采用非阻塞 IO 方式,这样绕开缓存,测试的更准确。
总结:在生产环境下,建议使用 hdparm 来测试磁盘读,使用 dd 来测试磁盘写速度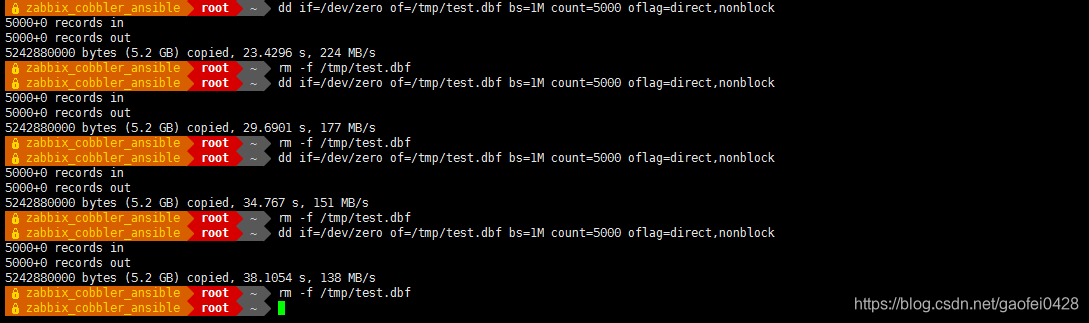
- time 命 令 测 试 进 程 运 行 时 间
time 命令: 执行命令并计时
测试 dd 命令使用时间和开销 - time dd if=/dev/zero of=/tmp/test.dbf bs=1M count=5000 oflag=direct,nonblock

- 1)实际时间(real time): 从 command 命令行开始执行到运行终止的消逝时间;
2)用户 CPU 时间(user CPU time): 命令执行完成花费的用户 CPU 时间,即命令在用户态中执行时间总和;
3)系统 CPU 时间(system CPU time): 命令执行完成花费的系统 CPU 时间,即命令在核心态中执行时间总和。
其中,用户 CPU 时间和系统 CPU 时间之和为 CPU 时间,即命令占用 CPU 执行的时间总和。实际时间要大于 CPU 时间,因为 Linux 是多任务操作系统,往往在执行一条命令时,系统还要处理其它任务。
排队时间没有算在里面。
另一个需要注意的问题是即使每次执行相同命令,但所花费的时间也是不一样,其花费时间是与系统运行相关的
-
内核参数调优
- 使用netstat命令去查TIME_WAIT状态的连接状态,输入下面的组合命令,查看当前TCP连接的状态和对应的连接数量:
netstat -n | awk '/^tcp/ {++S[$NF]} END {for(a in S) print a, S[a]}'
ESTABLISHED 1
SYN_SENT 2
TIME_WAIT 49 -
调整下Linux的TCP内核参数,让系统更快的释放TIME_WAIT连接。
用vim打开配置文件:vim /etc/sysctl.conf在这个文件中,加入下面的几行内容:
net.ipv4.tcp_syncookies = 1
net.ipv4.tcp_tw_reuse = 1
net.ipv4.tcp_tw_recycle = 1
net.ipv4.tcp_fin_timeout = 30输入下面的命令,让内核
网站声明:如果转载,请联系本站管理员。否则一切后果自行承担。
- 上周热门
- 如何使用 StarRocks 管理和优化数据湖中的数据? 2959
- 【软件正版化】软件正版化工作要点 2878
- 统信UOS试玩黑神话:悟空 2843
- 信刻光盘安全隔离与信息交换系统 2737
- 镜舟科技与中启乘数科技达成战略合作,共筑数据服务新生态 1270
- grub引导程序无法找到指定设备和分区 1235
- 华为全联接大会2024丨软通动力分论坛精彩议程抢先看! 165
- 点击报名 | 京东2025校招进校行程预告 164
- 2024海洋能源产业融合发展论坛暨博览会同期活动-海洋能源与数字化智能化论坛成功举办 163
- 华为纯血鸿蒙正式版9月底见!但Mate 70的内情还得接着挖... 159
- 本周热议
- 我的信创开放社区兼职赚钱历程 40
- 今天你签到了吗? 27
- 信创开放社区邀请他人注册的具体步骤如下 15
- 如何玩转信创开放社区—从小白进阶到专家 15
- 方德桌面操作系统 14
- 我有15积分有什么用? 13
- 用抖音玩法闯信创开放社区——用平台宣传企业产品服务 13
- 如何让你先人一步获得悬赏问题信息?(创作者必看) 12
- 2024中国信创产业发展大会暨中国信息科技创新与应用博览会 9
- 中央国家机关政府采购中心:应当将CPU、操作系统符合安全可靠测评要求纳入采购需求 8
