k8s 控制器:Daemonset 和 Job


-
-
DaemonSet 概述
- DaemonSet 控制器能够确保 k8s 集群所有的节点都运行一个相同的 pod 副本,当向 k8s 集群中增加 node 节点时,这个 node 节点也会自动创建一个 pod 副本,当 node 节点从集群移除,这些 pod 也会自动删除;删除 Daemonset 也会删除它们创建的 pod
-
DaemonSet 工作原理:如何管理 Pod?
- daemonset 的控制器会监听 kuberntes 的 daemonset 对象、pod 对象、node 对象,这些被监听的对象之变动,就会触发 syncLoop 循环让 kubernetes 集群朝着 daemonset 对象描述的状态进行演进。
此部分代码位于 pkg/kubelet/kubelet.go
- Daemonset 典型的应用场景
在集群的每个节点上运行存储,比如:glusterd 或 ceph。
在每个节点上运行日志收集组件,比如:flunentd 、 logstash、filebeat 等。
在每个节点上运行监控组件,比如:Prometheus、 Node Exporter 、collectd 等。
-
DaemonSet 与 Deployment 的区别
Deployment 部署的副本 Pod 会分布在各个 Node 上,每个 Node 都可能运行好几个副本。
DaemonSet 的不同之处在于:每个 Node 上最多只能运行一个副本。 -
DaemonSet 资源清单文件编写技巧
- 查看定义 Daemonset 资源需要的字段有哪些?
kubectl explain ds
KIND: DaemonSet
VERSION: apps/v1
DESCRIPTION:
DaemonSet represents the configuration of a daemon set.
FIELDS:
apiVersion <string> 当前资源使用的 api 版本,跟 VERSION: apps/v1 保持一致
kind <string> 资源类型,跟 KIND: DaemonSet 保持一致
metadata <Object> 元数据,定义 DaemonSet 名字的
spec <Object> 定义容器的
status <Object> 状态信息,不能改
- 查看 DaemonSet 的 spec 字段如何定义?
- kubectl explain ds.spec
KIND: DaemonSet
VERSION: apps/v1
RESOURCE: spec <Object>
DESCRIPTION:
The desired behavior of this daemon set. More info:
https://git.k8s.io/community/contributors/devel/sig-architecture/apiconventions.mdspec-and-status
DaemonSetSpec is the specification of a daemon set.
FIELDS:
minReadySeconds <integer> 当新的 pod 启动几秒种后,再 kill 掉旧的 pod。
revisionHistoryLimit <integer> 历史版本
selector <Object> -required- 用于匹配 pod 的标签选择器
template <Object> -required- 定义 Pod 的模板,基于这个模板定义的所有 pod 是一样的 updateStrategy <Object> daemonset 的升级策略
- 查看 DaemonSet 的 spec.template 字段如何定义?
对于 template 而言,其内部定义的就是 pod,pod 模板是一个独立的对象
kubectl explain ds.spec.template
KIND: DaemonSet
VERSION: apps/v1
RESOURCE: template <Object>
FIELDS:
metadata <Object>
spec<Object>
-
DaemonSet 使用案例-日志收集组件 fluentd
- vim daemonset.yaml
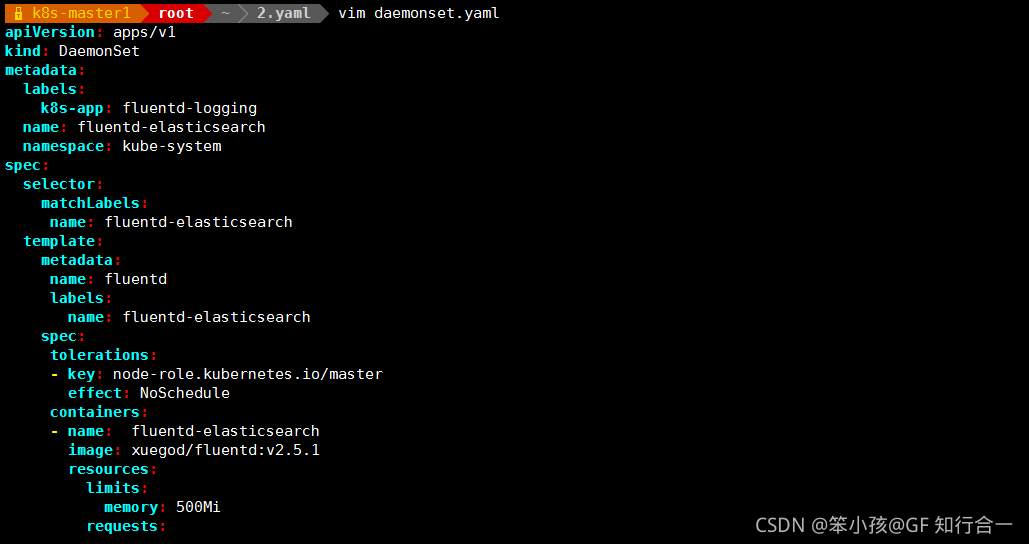

所有节点均创建了 fluentd 这个 pod

-
资源清单详细说明
- apiVersion: apps/v1 DaemonSet 使用的 api 版本
kind: DaemonSet 资源类型
metadata:
name: fluentd-elasticsearch 资源的名字
namespace: kube-system 资源所在的名称空间
labels:
k8s-app: fluentd-logging 资源具有的标签
spec:
selector: 标签选择器
matchLabels:
name: fluentd-elasticsearch
template:
metadata:
labels: 基于这回模板定义的 pod 具有的标签
name: fluentd-elasticsearch
spec:
tolerations: 定义容忍度
- key: node-role.kubernetes.io/master
effect: NoSchedule
containers: 定义容器
- name: fluentd-elasticsearch
image: xuegod/fluentd:v2.5.1
resources: 资源配额
limits:
memory: 200Mi
requests:
cpu: 100m
memory: 200Mi
volumeMounts:
- name: varlog
mountPath: /var/log 把本地/var/log 目录挂载到容器
- name: varlibdockercontainers
mountPath: /var/lib/docker/containers 把/var/lib/docker/containers/挂载到容器里
readOnly: true 挂载目录是只读权限
terminationGracePeriodSeconds: 30 优雅的关闭服务
volumes:
- name: varlog
hostPath:
path: /var/log 基于本地目录创建一个卷
- name: varlibdockercontainers
hostPath:
path: /var/lib/docker/containers 基于本地目录创建一个卷
- 扩展:什么是 terminationGracePeriodSeconds?
解释这个参数之前,先来回忆一下 K8S 滚动升级的步骤:
1.K8S 首先启动新的 POD
2.K8S 等待新的 POD 进入 Ready 状态
3.K8S 创建 Endpoint,将新的 POD 纳入负载均衡
4.K8S 移除与老 POD 相关的 Endpoint,并且将老 POD 状态设置为 Terminating,此时将不会有新的请求到达老 POD
5.同时 K8S 会给老 POD 发送 SIGTERM 信号,并且等待 terminationGracePeriodSeconds 这么长的时间。(默认为 30 秒)
6.超过 terminationGracePeriodSeconds 等待时间后, K8S 会强制结束老 POD
- erminationGracePeriodSeconds 就是 K8S 给你程序留的最后的缓冲时间,来处理关闭之前的操作。
-
DaemonSet 实现 pod 的滚动更新
- 查看 daemonset 的滚动更新策略
kubectl explain ds.spec.updateStrategy
KIND: DaemonSet
VERSION: apps/v1RESOURCE: updateStrategy <Object>
DESCRIPTION:
An update strategy to replace existing DaemonSet pods with new pods.DaemonSetUpdateStrategy is a struct used to control the update strategy for
a DaemonSet.FIELDS:
rollingUpdate <Object>
Rolling update config params. Present only if type = "RollingUpdate".type <string>
Type of daemon set update. Can be "RollingUpdate" or "OnDelete". Default is
RollingUpdate.
查看 rollingUpdate 支持的更新策略
] kubectl explain ds.spec.updateStrategy.rollingUpdate
KIND: DaemonSet
VERSION: apps/v1
RESOURCE: rollingUpdate <Object>
DESCRIPTION:
Rolling update config params. Present only if type = "RollingUpdate".
Spec to control the desired behavior of daemon set rolling update.
FIELDS:
maxUnavailable <string>表示 rollingUpdate 更新策略只支持 maxUnavailabe,先删除在更新;因为我们不支持一个
节点运行两个 pod,因此需要先删除一个,在更新一个。
更新镜像版本,可以按照如下方法:
kubectl set image daemonsets fluentd-elasticsearch *=ikubernetes/filebeat:5.6.6-alpine -n kube-system
kubectl set image (-f FILENAME | TYPE NAME) CONTAINER_NAME_1=CONTAINER_IMAGE_1 ... CONTAINER_NAME_N=CONTAINER_IMAGE_N [options]
-
Job 概念、原理解读
-
Job 控制器用于管理 Pod 对象运行一次性任务,比方说我们对数据库备份,可以直接在 k8s 上启动一个 mysqldump 备份程序,也可以启动一个 pod,这个 pod 专门用来备份用的,备份结束 pod 就可以终止了,不需要重启,而是将 Pod 对象置于"Completed"(完成)状态,若容器中的进程因错误而终止,则需要按照重启策略配置确定是否重启,对于 Job 这个类型的控制器来说,需不需要重建 pod 就看任务是否完成,完成就不需要重建,没有完成就需要重建 pod。
Job 控制器的 Pod 对象的状态转换如下图所示:
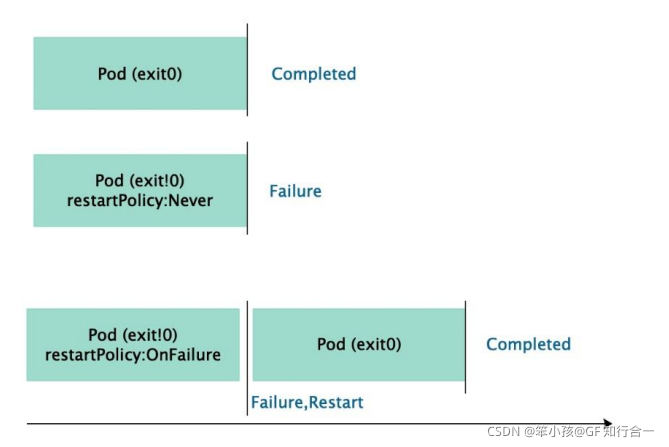
Job 用来创建 1 个或多个 Pod,并保证指定数量(.spec.completions)的 Pod 成功完成。当一个 Pod成功完成时(.status.phase=Succeeded),Job 会记录已完成的 Pod 的数量,但完成的数量达到指定值时,这个 Job 就完成了。
可以通过以下 3 种方式来判断一个 Job 是否已完成:
.status.completionTime 是否为空。Job 完成时该字段会被设置成 Job 完成的时间,否则为空
.spec.completions 和.status.succeeded 是否相等,即对比期望完成数和已成功数,当二者相等时,表示 Job 已经完成
.status.conditions[0].type:type 为 Complete 和 Failed 时,分别表示 Job 执行成功和失败
Pod 中的容器可能因为各种各样的原因失败,比如退出码不为 0、超出内存限制被 kill 掉,容器失败分两种情况:
.spec.template.spec.restartPolicy = "OnFailure":容器失败后会不断重启,直到成功(退出码为 0)
.spec.template.spec.restartPolicy = "Never":容器不会重启,Pod 的状态转为 Failed当 Pod 执行失败时,Job 会不断创建一个新的 Pod 进行重试,直到失败次数达到.spec.backoffLimit 指定的数值,整个 Job 的执行失败。可以通过判断.status.failed和.spec.backoffLimit 是否相等,即已失败数是否已经达到上限,来判断 Job 是否已经执行失败。
如下,当.spec.backoffLimit 设置为 3 时,.status.failed 已经达到 3,Job 失败,不会再尝试创建新的Pod
Job 三种使用场景:
1、非并行任务:只启一个 pod,pod 成功,job 正常结束
2、并行任务同时指定成功个数:.spec.completions 为指定成功个数,可以指定也可以不指定.spec.parallelism(指定>1,会有多个任务并行运行)。当成功个数达到.spec.completions,任务结束。
3、有工作队列的并行任务:.spec.completions 默认为 1,.spec.parallelism 为大于 0 的整数。此时并行启动多个 pod,只要有一个成功,任务结束,所有 pod 结束
适用场景:
Job 不是设计用来完成通信密集型的并行程序,如科学计算领域常见的场景。它支持并行地处理一组独立但相关的 work item,如发送邮件,渲染帧,转码文件和扫描 NoSql 数据库中的 key
相关配置:
.spec.completions:完成该 Job 需要执行成功的 Pod 数
.spec.parallelism:能够同时运行的 Pod 数
.spec.backoffLimit:允许执行失败的 Pod 数,默认值是 6,0 表示不允许 Pod 执行失败。如果Pod 是 restartPolicy 为 Nerver,则失败后会创建新的 Pod,如果是 OnFailed,则会重启 Pod,不管是哪种情况,只要 Pod 失败一次就计算一次,而不是等整个 Pod 失败后再计算一个。当失败的次数达到该限制时,整个 Job 随即结束,所有正在运行中的 Pod 都会被删除。
.spec.activeDeadlineSeconds: Job 的超时时间,一旦一个 Job 运行的时间超出该限制,则 Job失败,所有运行中的 Pod 会被结束并删除。该配置指定的值必须是个正整数。不指定则不会超时
-
CronJob 概念、原理解读
- CronJob 跟 Job 完成的工作是一样的,只不过 CronJob 添加了定时任务能力可以指定时间,实现周期性运行。
Job,CronJob 和 Deployment,DaemonSet 显著区别在于不需要持续在后台运行Deployment 主要用于管理无状态的应用(kubernetes 集群有一些 pod,某一个 pod 出现故障,删除之后会重新启动一个 pod,那么 kubernetes 这个集群中 pod 数量就正常了,更多关注的是群体,这就是无状态应用)。
使用场景:
1、在给定时间点只运行一次。
2、在给定时间点周期性地运行。
CronJob 的典型用法如下:
1、在给定的时间点调度 Job 运行。
2、创建周期性运行的 Job,例如数据库备份、发送邮件
-
Job 控制器:资源清单编写技巧
- 查看 Job 资源对象由哪几部分组成
[~] kubectl explain Job
KIND: Job
VERSION: batch/v1
DESCRIPTION:
Job represents the configuration of a single job.
FIELDS:
apiVersion <string> 当前 Job 的 api 版本
kind <string> 指定当前的资源类型
metadata <Object> 元数据,定义资源的名字和所在名称空间
spec <Object>
查看 Job 下的 spec 字段
[~] kubectl explain Job.spec
KIND: Job
VERSION: batch/v1
RESOURCE: spec <Object>
DESCRIPTION:
Specification of the desired behavior of a job. More info:
https://git.k8s.io/community/contributors/devel/sig-architecture/apiconventions.mdspec-and-status
JobSpec describes how the job execution will look like.
FIELDS:
activeDeadlineSeconds <integer> 通过指定 job 存活时间,来结束一个 job。当 job 运行时间达到 activeDeadlineSeconds 指定的时间后,job 会停止由它启动的所有任务(如:pod),并设置 job 的状态为 failed
backoffLimit <integer> job 建议指定 pod 的重启策略为 never,如:.spec.template.spec.restartPolicy = "Never",然后通过 job 的 backoffLimit 来指定失败重试次数,在达到 backoffLimit 指定的次数后,job 状态设置为 failed(默认为 6 次) completions <integer> 指定 job 启动的任务(如:pod)成功运行 completions 次,job 才算成功结束
manualSelector <boolean>
parallelism <integer> 指定 job 同时运行的任务(如:pod)个数,Parallelism 默认为 1,如果设置为 0,则 job 会暂定
selector <Object>
template <Object> -required-
ttlSecondsAfterFinished <integer> 默认情况下,job 异常或者成功结束后,包括 job 启动的任务(pod),都不会被清理掉,因为你可以依据保存的 job 和 pod,查看状态、日志,以及调试等。这些用户可以手动删除,用户手动删除 job,job controller 会级联删除对应的 pod,除了手动删除,通过指定参数 ttlSecondsAfterFinished 也可以实现自动删除 job,以及级联的资源,如:pod。如果设置为 0,job 会被立即删除。如果不指定,job 则不会被删除
-
查看 Job 下的 spec.template 字段
- template 为定义 Pod 的模板,Job 通过模板创建 Pod
[~] kubectl explain Job.spec.template
KIND: Job
VERSION: batch/v1
RESOURCE: template <Object>
DESCRIPTION:
Describes the pod that will be created when executing a job. More info:
https://kubernetes.io/docs/concepts/workloads/controllers/jobs-run-tocompletion/
FIELDS:
metadata <Object>
spec <Object>
查看 Job 下的 spec.template.spec 字段
[~] kubectl explain Job.spec.template.spec
KIND: Job
VERSION: batch/v1
RESOURCE: spec <Object>
DESCRIPTION:
Specification of the desired behavior of the pod. More info:
https://git.k8s.io/community/contributors/devel/sig-architecture/apiconventions.mdspec-and-status
PodSpec is a description of a pod.
FIELDS:
activeDeadlineSeconds <integer>
affinity <Object>
containers <[]Object> -required-
dnsConfig <Object>
dnsPolicy <string>
enableServiceLinks <boolean>
ephemeralContainers <[]Object>
hostAliases<[]Object>
hostIPC <boolean>
hostNetwork <boolean>
hostPID <boolean>
hostname <string>
imagePullSecrets <[]Object>
initContainers <[]Object>
nodeName <string>
nodeSelector <map[string]string>
overhead <map[string]string>
preemptionPolicy <string>
priority <integer>
priorityClassName <string>
readinessGates <[]Object>
restartPolicy <string> 重启策略,对于 Job,只能设置为 Never 或者 OnFailure。对于其他 controller(比如 Deployment)可以设置为 Always 。
runtimeClassName <string>
schedulerName <string>
securityContext <Object>
serviceAccount <string>
serviceAccountName <string>
setHostnameAsFQDN <boolean>
shareProcessNamespace <boolean>
subdomain <string>
terminationGracePeriodSeconds <integer>
tolerations <[]Object>
topologySpreadConstraints <[]Object>
volumes <[]Object>
-
Job -创建一个一次性任务
- vim job.yaml
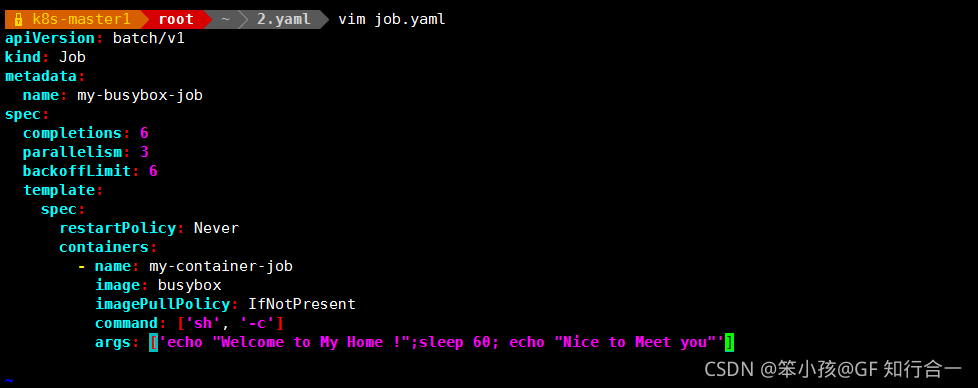


COMPLETIONS : 成功退出的 pod 数/并行运行的 pod 数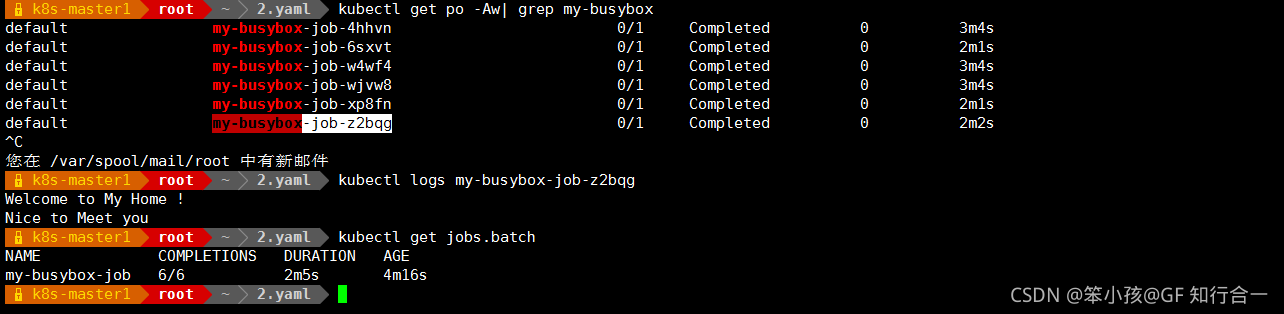
-
资源清单文件详细解读
-
- apiVersion: batch/v1
kind: Job
metadata:
name: my-busybox-job
spec:
ttlSecondsAfterFinished: 20
completions: 6 job 结束需要成功运行的 Pod 个数,即状态为 Completed 的 pod 数
parallelism: 3 一次运行 3 个 pod 指的是一次性运行几个 pod,这个值不会超过 completions 的值
backoffLimit: 6 如果 job 失败,则重试几次,
template:
spec:
restartPolicy: Never
containers:
- name: my-container-job
image: busybox
imagePullPolicy: IfNotPresent
command: ['sh', '-c']
args: ['echo "Welcome to xuegod";sleep 60; echo "Next to Meet you"'] -
CronJob 使用案例-创建周期性的定时任务
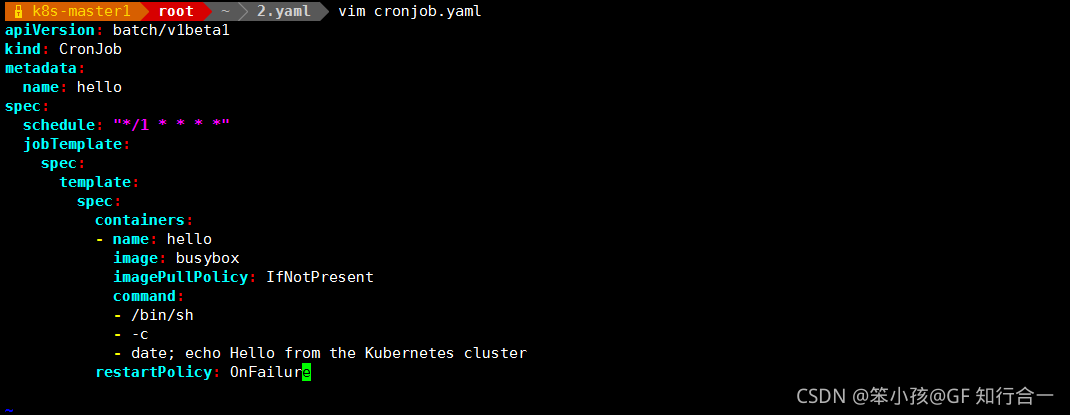
- vim cronjob.yaml
观察大概一分钟,等待 CronJob创建: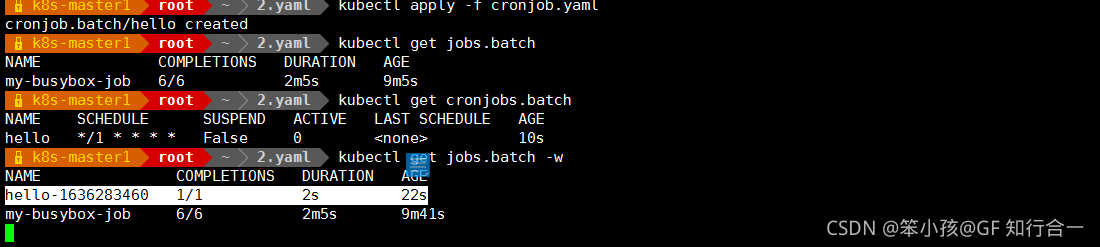
现在可以看到由 hello 这个 cronjob 调度的正在运行的 job
可以看到 hello 这个 CronJob 成功地在 LAST SCHEDULE 中指定的时间点调度了一个作业。当前有 1 个活动作业,这意味着该作业已经完成或失败。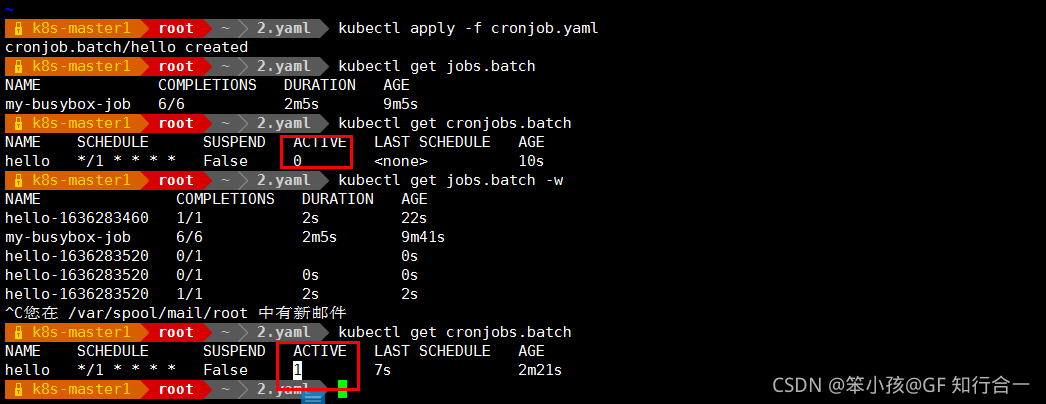



-
使用 CronJob 定期备份 MySQL 数据
- CronJob 所描述的,正是定时任务。
1、在给定时间点只运行一次
2、在给定时间点周期性地运行
一个 CronJob 对象类似于 crontab (cron table)文件中的一行。它根据指定的预定计划周期性地运行一个 Job。在这里简单的说一下 cron,是指 unix 中 cron 表达式。比如:"*/1 * * * *",这个Cron 表达式里*/1 中 *表示从 0 开始,/表示"每",1 表示偏移量,所以它的意思是:从 0 开始,每 1个时间单位执行一次。Cron 表达式中五个部分分别代表:分钟,小时,日,月,星期。
所以上述这句Cron 表达式的意思是:从当前开始,每分钟执行一次。那么我们可以利用这个机制来指定创建 mysql备份任务的对象:
apiVersion: batch/v1beta1
kind: CronJob
metadata:
name: mysqldump
spec:
schedule: "50 15 * * *"
jobTemplate:
spec:
completions: 1
template:
spec:
restartPolicy: Never
volumes:
- name: mysql-master-script
hostPath:
path: /root/app/mysql/shell
- name: mysql-master-backup
hostPath:
path: /root/app/db/backup
- name: local-time
hostPath:
path: /etc/localtime
containers:
- name: mysqldump-container
image: nacos/nacos-mysql-master:latest
volumeMounts:
- name: mysql-master-script
mountPath: /var/db/script
- name: local-time
mountPath: /etc/localtime
- name: mysql-master-backup
mountPath: /var/db/backup
command:
- "sh"
- "/var/db/script/mysqldump.sh"
在这个 Yaml 文件当中,最重要的关键词就是 jobTemplate。它是由 job 对象控制的 Controller,还有几点关键的属性这里解释说明一下:
1、spec.concurrencyPolicy 这个属性主要是由于定时任务的特殊性,很可能某个 job 还没执行完,另外一个新的 job 就产生了。它的取值分别为:Allow(job 可以同时存在),Forbid(不会创建新的job,该周期会被跳过),Replace(新产生的 Job 替换旧的,没有执行完的 Job)
2、如果某一次 Job 创建失败,这次创建会被标记为"Miss"。当在指定的事件窗口内,miss 数目达到 100 时,那么 CronJob 会停止再创建这个 Job,这个时间窗口可以有spec.startingDeadlineSeconds 来指定
3、在 Job 对象中,负责并行控制的参数有两个:spec.parallelism 它定义的是一个 Job 在任意时间最多可以启动多少个 Pod 同时运行。spec.comletions 它定义的是 job 至少完成的 Pod 数目这里容器与宿主机时差相差 8 小时。注意在设置定时任务的时候一定算好时间
- 备份数据库的脚本 , mysqldump.sh 脚本如下:
!/bin/bash
保存备份个数
number=3
备份保存路径
backup_dir=/var/db/backup
日期
dd=`date +%Y%m%d`
备份工具
tool=/usr/bin/mysqldump
用户名
username=root
密码
password=root
将要备份的数据库
database_name=test
简单写法 mysqldump -u root -p123456 users > /root/mysqlbackup/users-
$filename.sql
$tool -u $username -p$password -hmysql-master -P3306 --databases
$database_name > $backup_dir/$database_name-$dd.sql
写创建备份日志
echo "create $backup_dir/$database_name-$dd.sql" >> $backup_dir/log.txt
找出需要删除的备份
delfile=`ls -l -crt $backup_dir/*.sql | awk '{print $9 }' | head -1`
判断现在的备份数量是否大于$number
count=`ls -l -crt $backup_dir/*.sql | awk '{print $9 }' | wc -l`
if [ $count -gt $number ]
then
rm $delfile //删除最早生成的备份只保留 number 数量的备份
写删除文件日志
echo "delete $delfile" >> $backup_dir/log.txt
fi
网站声明:如果转载,请联系本站管理员。否则一切后果自行承担。
- 上周热门
- 如何使用 StarRocks 管理和优化数据湖中的数据? 2956
- 【软件正版化】软件正版化工作要点 2875
- 统信UOS试玩黑神话:悟空 2839
- 信刻光盘安全隔离与信息交换系统 2733
- 镜舟科技与中启乘数科技达成战略合作,共筑数据服务新生态 1267
- grub引导程序无法找到指定设备和分区 1231
- 华为全联接大会2024丨软通动力分论坛精彩议程抢先看! 165
- 2024海洋能源产业融合发展论坛暨博览会同期活动-海洋能源与数字化智能化论坛成功举办 163
- 点击报名 | 京东2025校招进校行程预告 163
- 华为纯血鸿蒙正式版9月底见!但Mate 70的内情还得接着挖... 159
- 本周热议
- 我的信创开放社区兼职赚钱历程 40
- 今天你签到了吗? 27
- 如何玩转信创开放社区—从小白进阶到专家 15
- 信创开放社区邀请他人注册的具体步骤如下 15
- 方德桌面操作系统 14
- 用抖音玩法闯信创开放社区——用平台宣传企业产品服务 13
- 我有15积分有什么用? 13
- 如何让你先人一步获得悬赏问题信息?(创作者必看) 12
- 2024中国信创产业发展大会暨中国信息科技创新与应用博览会 9
- 信创再发力!中央国家机关台式计算机、便携式计算机批量集中采购配置标准的通知 8
